 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeORCE: Order-Aware Alignment of Verbalized Confidence in Large Language Models
May 12, 2026Large language models (LLMs) often produce answers with high certainty even when they are incorrect, making reliable confidence estimation essential for deployment in real-world scenarios. Verbalized confidence, where models explicitly state their confidence in natural language, provides a flexible and user-facing uncertainty signal that can be applied even when token logits are unavailable. However, existing verbalized-confidence methods often optimize answer generation and confidence generation jointly, which can cause confidence-alignment objectives to interfere with answer accuracy. In this work, we propose a decoupled and order-aware framework for verbalized confidence calibration. Our method first generates an answer and then estimates confidence conditioned on the fixed question--answer pair, allowing confidence optimization without directly perturbing the answer-generation process. To align confidence with correctness likelihood, we construct a sampling-based surrogate from multiple model completions and optimize rank-based reinforcement learning objectives that encourage responses with higher estimated correctness likelihood to receive higher verbalized confidence. Experiments on reasoning and knowledge-intensive benchmarks show that our method improves calibration and failure prediction performance while largely preserving answer accuracy. These results demonstrate that verbalized confidence can be more reliably aligned by decoupling confidence estimation from answer generation and optimizing the relative ordering of confidence across responses.
Topo-R1: Detecting Topological Anomalies via Vision-Language Models
Mar 13, 2026Topological correctness is crucial for tubular structures such as blood vessels, nerve fibers, and road networks. Existing topology-preserving methods rely on domain-specific ground truth, which is costly and rarely transfers across domains. When deployed to a new domain without annotations, a key question arises: how can we detect topological anomalies without ground-truth supervision? We reframe this as topological anomaly detection, a structured visual reasoning task requiring a model to locate and classify topological errors in predicted segmentation masks. Vision-Language Models (VLMs) are natural candidates; however, we find that state-of-the-art VLMs perform nearly at random, lacking the fine-grained, topology-aware perception needed to identify sparse connectivity errors in dense structures. To bridge this gap, we develop an automated data-curation pipeline that synthesizes diverse topological anomalies with verifiable annotations across progressively difficult levels, thereby constructing the first large-scale, multi-domain benchmark for this task. We then introduce Topo-R1, a framework that endows VLMs with topology-aware perception via two-stage training: supervised fine-tuning followed by reinforcement learning with Group Relative Policy Optimization (GRPO). Central to our approach is a topology-aware composite reward that integrates type-aware Hungarian matching for structured error classification, spatial localization scoring, and a centerline Dice (clDice) reward that directly penalizes connectivity disruptions, thereby jointly incentivizing semantic precision and structural fidelity. Extensive experiments demonstrate that Topo-R1 establishes a new paradigm for annotation-free topological quality assessment, consistently outperforming general-purpose VLMs and supervised baselines across all evaluation protocols.
Act Like a Pathologist: Tissue-Aware Whole Slide Image Reasoning
Feb 28, 2026Computational pathology has advanced rapidly in recent years, driven by domain-specific image encoders and growing interest in using vision-language models to answer natural-language questions about diseases. Yet, the core problem behind pathology question-answering remains unsolved, considering that a gigapixel slide contains far more information than necessary for a given question. Pathologists naturally navigate tissue and morphology complexity by scanning broadly, and zooming in selectively according to the clinical questions. Current models, in contrast, rely on uniform patch sampling or broad attention maps, often attending equally to irrelevant regions while overlooking key visual evidence. In this work, we try to bring models closer to how humans actually examine slides. We propose a question-guided, tissue-aware, and coarse-to-fine retrieval framework, HistoSelect, that consists of two key components: a group sampler that identifies question-relevant tissue regions, followed by a patch selector that retrieves the most informative patches within those regions. By selecting only the most informative patches, our method becomes significantly more efficient: reducing visual token usage by 70% on average, while improving accuracy across three pathology QA tasks. Evaluated on 356,000 question-answer pairs, our approach outperforms existing methods and produces answers grounded in interpretable, pathologist-consistent regions. Our results suggest that bringing human-like search and attention patterns into WSI reasoning is a promising direction for building practical and reliable pathology VLMs.
Improving Neuropathological Reconstruction Fidelity via AI Slice Imputation
Jan 31, 2026Neuropathological analyses benefit from spatially precise volumetric reconstructions that enhance anatomical delineation and improve morphometric accuracy. Our prior work has shown the feasibility of reconstructing 3D brain volumes from 2D dissection photographs. However these outputs sometimes exhibit coarse, overly smooth reconstructions of structures, especially under high anisotropy (i.e., reconstructions from thick slabs). Here, we introduce a computationally efficient super-resolution step that imputes slices to generate anatomically consistent isotropic volumes from anisotropic 3D reconstructions of dissection photographs. By training on domain-randomized synthetic data, we ensure that our method generalizes across dissection protocols and remains robust to large slab thicknesses. The imputed volumes yield improved automated segmentations, achieving higher Dice scores, particularly in cortical and white matter regions. Validation on surface reconstruction and atlas registration tasks demonstrates more accurate cortical surfaces and MRI registration. By enhancing the resolution and anatomical fidelity of photograph-based reconstructions, our approach strengthens the bridge between neuropathology and neuroimaging. Our method is publicly available at https://surfer.nmr.mgh.harvard.edu/fswiki/mri_3d_photo_recon
MATCH: Multi-faceted Adaptive Topo-Consistency for Semi-Supervised Histopathology Segmentation
Oct 02, 2025



In semi-supervised segmentation, capturing meaningful semantic structures from unlabeled data is essential. This is particularly challenging in histopathology image analysis, where objects are densely distributed. To address this issue, we propose a semi-supervised segmentation framework designed to robustly identify and preserve relevant topological features. Our method leverages multiple perturbed predictions obtained through stochastic dropouts and temporal training snapshots, enforcing topological consistency across these varied outputs. This consistency mechanism helps distinguish biologically meaningful structures from transient and noisy artifacts. A key challenge in this process is to accurately match the corresponding topological features across the predictions in the absence of ground truth. To overcome this, we introduce a novel matching strategy that integrates spatial overlap with global structural alignment, minimizing discrepancies among predictions. Extensive experiments demonstrate that our approach effectively reduces topological errors, resulting in more robust and accurate segmentations essential for reliable downstream analysis. Code is available at \href{https://github.com/Melon-Xu/MATCH}{https://github.com/Melon-Xu/MATCH}.
Bézier Meets Diffusion: Robust Generation Across Domains for Medical Image Segmentation
Sep 26, 2025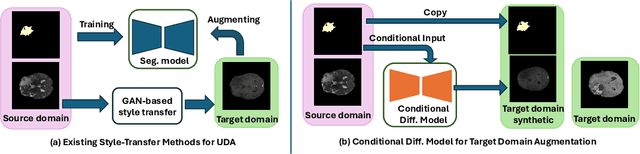
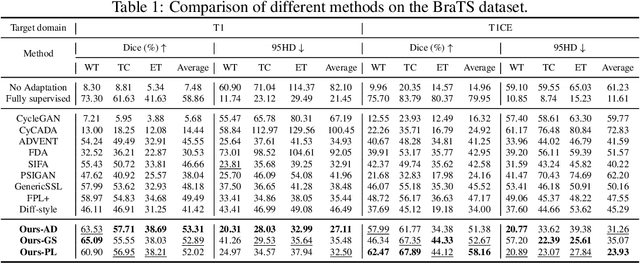
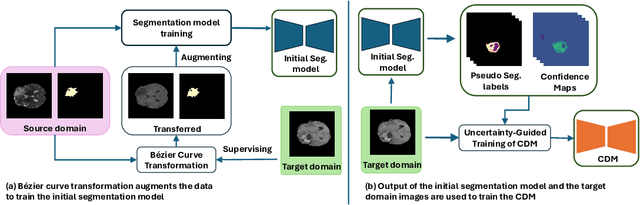
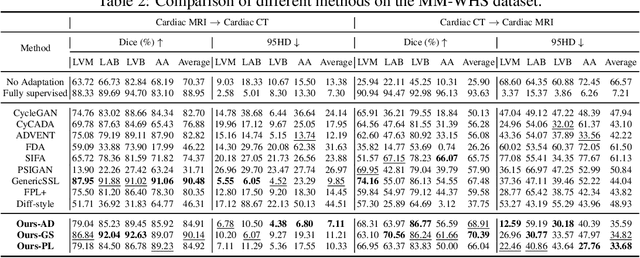
Training robust learning algorithms across different medical imaging modalities is challenging due to the large domain gap. Unsupervised domain adaptation (UDA) mitigates this problem by using annotated images from the source domain and unlabeled images from the target domain to train the deep models. Existing approaches often rely on GAN-based style transfer, but these methods struggle to capture cross-domain mappings in regions with high variability. In this paper, we propose a unified framework, B\'ezier Meets Diffusion, for cross-domain image generation. First, we introduce a B\'ezier-curve-based style transfer strategy that effectively reduces the domain gap between source and target domains. The transferred source images enable the training of a more robust segmentation model across domains. Thereafter, using pseudo-labels generated by this segmentation model on the target domain, we train a conditional diffusion model (CDM) to synthesize high-quality, labeled target-domain images. To mitigate the impact of noisy pseudo-labels, we further develop an uncertainty-guided score matching method that improves the robustness of CDM training. Extensive experiments on public datasets demonstrate that our approach generates realistic labeled images, significantly augmenting the target domain and improving segmentation performance.
Scalable Segmentation for Ultra-High-Resolution Brain MR Images
May 27, 2025Although deep learning has shown great success in 3D brain MRI segmentation, achieving accurate and efficient segmentation of ultra-high-resolution brain images remains challenging due to the lack of labeled training data for fine-scale anatomical structures and high computational demands. In this work, we propose a novel framework that leverages easily accessible, low-resolution coarse labels as spatial references and guidance, without incurring additional annotation cost. Instead of directly predicting discrete segmentation maps, our approach regresses per-class signed distance transform maps, enabling smooth, boundary-aware supervision. Furthermore, to enhance scalability, generalizability, and efficiency, we introduce a scalable class-conditional segmentation strategy, where the model learns to segment one class at a time conditioned on a class-specific input. This novel design not only reduces memory consumption during both training and testing, but also allows the model to generalize to unseen anatomical classes. We validate our method through comprehensive experiments on both synthetic and real-world datasets, demonstrating its superior performance and scalability compared to conventional segmentation approaches.
Biomedical Foundation Model: A Survey
Mar 03, 2025Foundation models, first introduced in 2021, are large-scale pre-trained models (e.g., large language models (LLMs) and vision-language models (VLMs)) that learn from extensive unlabeled datasets through unsupervised methods, enabling them to excel in diverse downstream tasks. These models, like GPT, can be adapted to various applications such as question answering and visual understanding, outperforming task-specific AI models and earning their name due to broad applicability across fields. The development of biomedical foundation models marks a significant milestone in leveraging artificial intelligence (AI) to understand complex biological phenomena and advance medical research and practice. This survey explores the potential of foundation models across diverse domains within biomedical fields, including computational biology, drug discovery and development, clinical informatics, medical imaging, and public health. The purpose of this survey is to inspire ongoing research in the application of foundation models to health science.
Poststroke rehabilitative mechanisms in individualized fatigue level-controlled treadmill training -- a Rat Model Study
Feb 20, 2025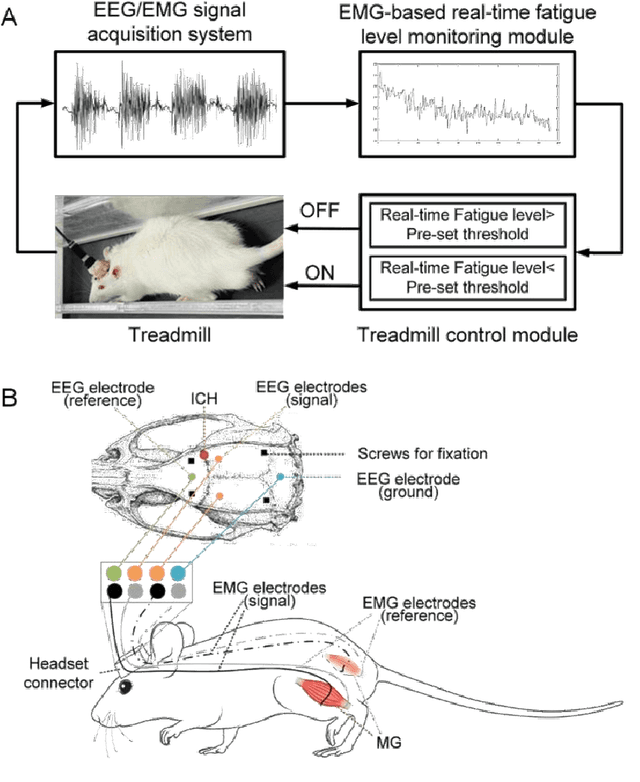
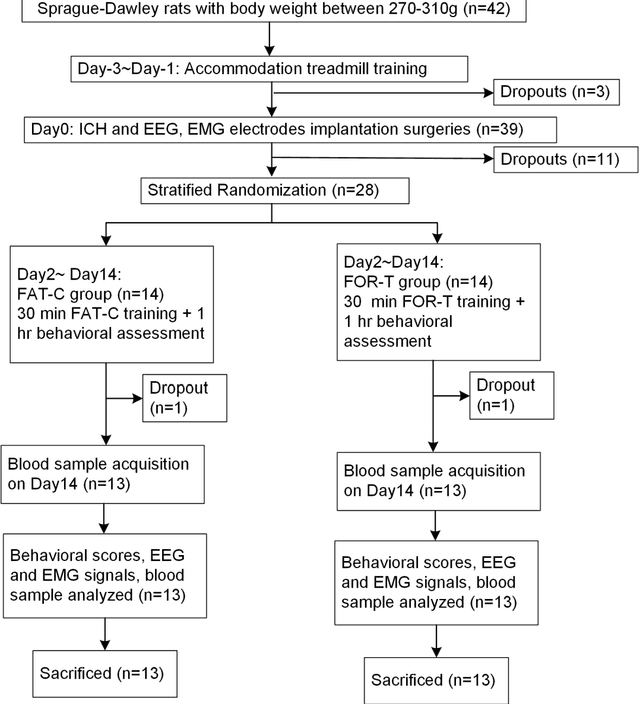
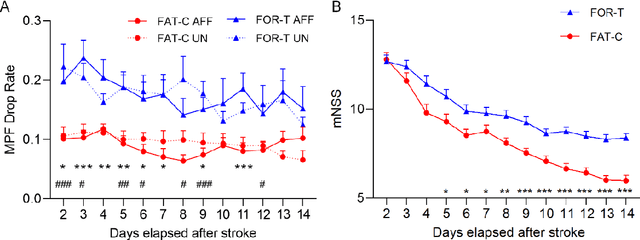
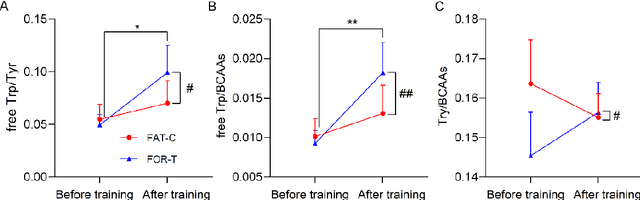
Individualized training improved post-stroke motor function rehabilitation efficiency. However, the mechanisms of how individualized training facilitates recovery is not clear. This study explored the cortical and corticomuscular rehabilitative effects in post-stroke motor function recovery during individualized training. Sprague-Dawley rats with intracerebral hemorrhage (ICH) were randomly distributed into two groups: forced training (FOR-T, n=13) and individualized fatigue-controlled training (FAT-C, n=13) to receive training respectively from day 2 to day 14 post-stroke. The FAT-C group exhibited superior motor function recovery and less central fatigue compared to the FOR-T group. EEG PSD slope analysis demonstrated a better inter-hemispheric balance in FAT-C group compare to the FOR-T group. The dCMC analysis indicated that training-induced fatigue led to a short-term down-regulation of descending corticomuscular coherence (dCMC) and an up-regulation of ascending dCMC. In the long term, excessive fatigue hindered the recovery of descending control in the affected hemisphere. The individualized strategy of peripheral fatigue-controlled training achieved better motor function recovery, which could be attributed to the mitigation of central fatigue, optimization of inter-hemispheric balance and enhancement of descending control in the affected hemisphere.
Movable Antenna Array Aided Ultra Reliable Covert Communications
Dec 29, 2024



In this paper, we construct a framework of the movable antenna (MA) aided covert communication shielded by the general noise uncertainty for the first time. According to the analysis performance on the derived closed-form expressions of the sum of the probabilities of the detection errors and the communication outage probability, the perfect covertness and the ultra reliability can be achieved by adjusting the antenna position in the MA array. Then, we formulate the communication covertness maximization problem with the constraints of the ultra reliability and the independent discrete movable position to optimize the transmitter's parameter. With the maximal ratio transmitting (MRT) design for the beamforming, we solve the closed-form optimal information transmit power and design a lightweight discrete projected gradient descent (DPGD) algorithm to determine the optimal antenna position. The numerical results show that the optimal achievable covertness and the feasible region of the steering angle with the MA array is significant larger than the one with the fixed-position antenna (FPA) array.