 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Multimodal Approach Combining Structural and Cross-domain Textual Guidance for Weakly Supervised OCT Segmentation
Nov 19, 2024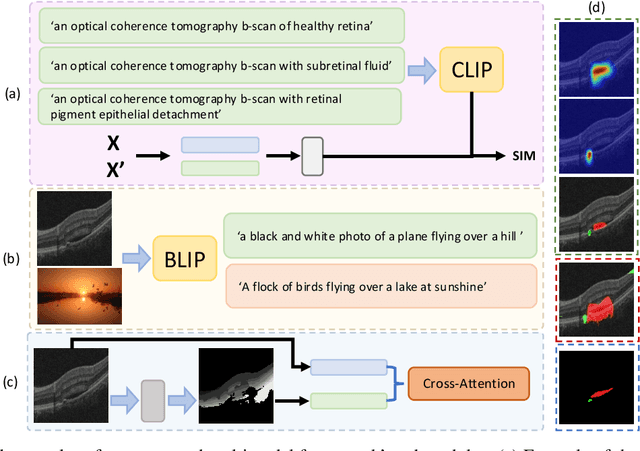
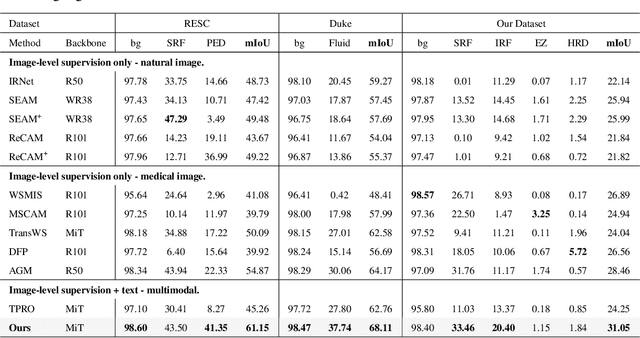
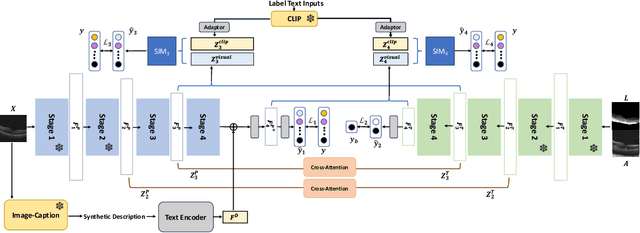
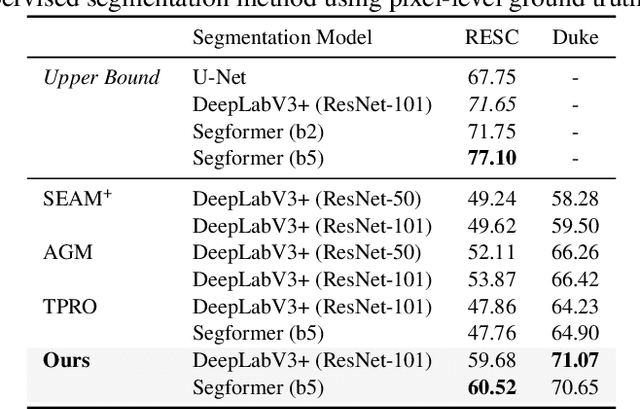
Accurate segmentation of Optical Coherence Tomography (OCT) images is crucial for diagnosing and monitoring retinal diseases. However, the labor-intensive nature of pixel-level annotation limits the scalability of supervised learning with large datasets. Weakly Supervised Semantic Segmentation (WSSS) provides a promising alternative by leveraging image-level labels. In this study, we propose a novel WSSS approach that integrates structural guidance with text-driven strategies to generate high-quality pseudo labels, significantly improving segmentation performance. In terms of visual information, our method employs two processing modules that exchange raw image features and structural features from OCT images, guiding the model to identify where lesions are likely to occur. In terms of textual information, we utilize large-scale pretrained models from cross-domain sources to implement label-informed textual guidance and synthetic descriptive integration with two textual processing modules that combine local semantic features with consistent synthetic descriptions. By fusing these visual and textual components within a multimodal framework, our approach enhances lesion localization accuracy. Experimental results on three OCT datasets demonstrate that our method achieves state-of-the-art performance, highlighting its potential to improve diagnostic accuracy and efficiency in medical imaging.