 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStableHand: Quality-Aware Flow Matching for World-Space Dual-Hand Motion Estimation from Egocentric Video
May 18, 2026Recovering world space 4D motion of two interacting hands from egocentric video is a fundamental capability for supervising robot policy learning, where wrist trajectories track the end-effector and finger articulations specify the grasp pose. Two major challenges arise in this setting: hands frequently leave the camera view for extended periods due to head motion, and persistent hand-object interactions cause severe occlusions of one or both hands. Existing methods uniformly condition on noisy hand motion observations without accounting for their per-frame reliability, leading to substantial performance degradation. Our key insight is that accurate world space hand motion estimation is tightly coupled with the quality of per-frame hand observations. To this end, we decompose the quality of hand motion observations extracted from an off-the-shelf hand pose estimator into four channels: wrist global translation and finger articulations for both hands. We propose StableHand, a quality-aware flow-matching framework conditioned on these four-channel quality signals, which are predicted by a learned quality network. We naturally incorporate the quality signals into the flow-matching process through a per-channel forward schedule, a quality-adjusted velocity target, AdaLN modulation of the DiT denoiser, and a quality-aware ODE initialization. This unified generative process preserves high-quality observations while reconstructing unreliable ones using a learned bimanual motion prior. Experiments on HOT3D and ARCTIC, two egocentric benchmarks featuring long missing-hand spans and persistent hand-object occlusions, show that StableHand achieves state-of-the-art performance across all reported metrics, reducing W-MPJPE by 20-25% compared to the strongest baseline, with the largest gains on heavily occluded ARCTIC sequences.
Seedance 2.0: Advancing Video Generation for World Complexity
Apr 15, 2026Seedance 2.0 is a new native multi-modal audio-video generation model, officially released in China in early February 2026. Compared with its predecessors, Seedance 1.0 and 1.5 Pro, Seedance 2.0 adopts a unified, highly efficient, and large-scale architecture for multi-modal audio-video joint generation. This allows it to support four input modalities: text, image, audio, and video, by integrating one of the most comprehensive suites of multi-modal content reference and editing capabilities available in the industry to date. It delivers substantial, well-rounded improvements across all key sub-dimensions of video and audio generation. In both expert evaluations and public user tests, the model has demonstrated performance on par with the leading levels in the field. Seedance 2.0 supports direct generation of audio-video content with durations ranging from 4 to 15 seconds, with native output resolutions of 480p and 720p. For multi-modal inputs as reference, its current open platform supports up to 3 video clips, 9 images, and 3 audio clips. In addition, we provide Seedance 2.0 Fast version, an accelerated variant of Seedance 2.0 designed to boost generation speed for low-latency scenarios. Seedance 2.0 has delivered significant improvements to its foundational generation capabilities and multi-modal generation performance, bringing an enhanced creative experience for end users.
Hg-I2P: Bridging Modalities for Generalizable Image-to-Point-Cloud Registration via Heterogeneous Graphs
Mar 30, 2026Image-to-point-cloud (I2P) registration aims to align 2D images with 3D point clouds by establishing reliable 2D-3D correspondences. The drastic modality gap between images and point clouds makes it challenging to learn features that are both discriminative and generalizable, leading to severe performance drops in unseen scenarios. We address this challenge by introducing a heterogeneous graph that enables refining both cross-modal features and correspondences within a unified architecture. The proposed graph represents a mapping between segmented 2D and 3D regions, which enhances cross-modal feature interaction and thus improves feature discriminability. In addition, modeling the consistency among vertices and edges within the graph enables pruning of unreliable correspondences. Building on these insights, we propose a heterogeneous graph embedded I2P registration method, termed Hg-I2P. It learns a heterogeneous graph by mining multi-path feature relationships, adapts features under the guidance of heterogeneous edges, and prunes correspondences using graph-based projection consistency. Experiments on six indoor and outdoor benchmarks under cross-domain setups demonstrate that Hg-I2P significantly outperforms existing methods in both generalization and accuracy. Code is released on https://github.com/anpei96/hg-i2p-demo.
TAFG-MAN: Timestep-Adaptive Frequency-Gated Latent Diffusion for Efficient and High-Quality Low-Dose CT Image Denoising
Mar 21, 2026Low-dose computed tomography (LDCT) reduces radiation exposure but also introduces substantial noise and structural degradation, making it difficult to suppress noise without erasing subtle anatomical details. In this paper, we present TAFG-MAN, a latent diffusion framework for efficient and high-quality LDCT image denoising. The framework combines a perceptually optimized autoencoder, conditional latent diffusion restoration in a compact latent space, and a lightweight Timestep-Adaptive Frequency-Gated (TAFG) conditioning design. TAFG decomposes condition features into low- and high-frequency components, predicts timestep-adaptive gates from the current denoising feature and timestep embedding, and progressively releases high-frequency guidance in later denoising stages before cross-attention. In this way, the model relies more on stable structural guidance at early reverse steps and introduces fine details more cautiously as denoising proceeds, improving the balance between noise suppression and detail preservation. Experiments show that TAFG-MAN achieves a favorable quality-efficiency trade-off against representative baselines. Compared with its base variant without TAFG, it further improves detail preservation and perceptual quality while maintaining essentially the same inference cost, and ablation results confirm the effectiveness of the proposed conditioning mechanism.
GloSplat: Joint Pose-Appearance Optimization for Faster and More Accurate 3D Reconstruction
Mar 05, 2026Feature extraction, matching, structure from motion (SfM), and novel view synthesis (NVS) have traditionally been treated as separate problems with independent optimization objectives. We present GloSplat, a framework that performs \emph{joint pose-appearance optimization} during 3D Gaussian Splatting training. Unlike prior joint optimization methods (BARF, NeRF--, 3RGS) that rely purely on photometric gradients for pose refinement, GloSplat preserves \emph{explicit SfM feature tracks} as first-class entities throughout training: track 3D points are maintained as separate optimizable parameters from Gaussian primitives, providing persistent geometric anchors via a reprojection loss that operates alongside photometric supervision. This architectural choice prevents early-stage pose drift while enabling fine-grained refinement -- a capability absent in photometric-only approaches. We introduce two pipeline variants: (1) \textbf{GloSplat-F}, a COLMAP-free variant using retrieval-based pair selection for efficient reconstruction, and (2) \textbf{GloSplat-A}, an exhaustive matching variant for maximum quality. Both employ global SfM initialization followed by joint photometric-geometric optimization during 3DGS training. Experiments demonstrate that GloSplat-F achieves state-of-the-art among COLMAP-free methods while GloSplat-A surpasses all COLMAP-based baselines.
FlowHOI: Flow-based Semantics-Grounded Generation of Hand-Object Interactions for Dexterous Robot Manipulation
Feb 13, 2026Recent vision-language-action (VLA) models can generate plausible end-effector motions, yet they often fail in long-horizon, contact-rich tasks because the underlying hand-object interaction (HOI) structure is not explicitly represented. An embodiment-agnostic interaction representation that captures this structure would make manipulation behaviors easier to validate and transfer across robots. We propose FlowHOI, a two-stage flow-matching framework that generates semantically grounded, temporally coherent HOI sequences, comprising hand poses, object poses, and hand-object contact states, conditioned on an egocentric observation, a language instruction, and a 3D Gaussian splatting (3DGS) scene reconstruction. We decouple geometry-centric grasping from semantics-centric manipulation, conditioning the latter on compact 3D scene tokens and employing a motion-text alignment loss to semantically ground the generated interactions in both the physical scene layout and the language instruction. To address the scarcity of high-fidelity HOI supervision, we introduce a reconstruction pipeline that recovers aligned hand-object trajectories and meshes from large-scale egocentric videos, yielding an HOI prior for robust generation. Across the GRAB and HOT3D benchmarks, FlowHOI achieves the highest action recognition accuracy and a 1.7$\times$ higher physics simulation success rate than the strongest diffusion-based baseline, while delivering a 40$\times$ inference speedup. We further demonstrate real-robot execution on four dexterous manipulation tasks, illustrating the feasibility of retargeting generated HOI representations to real-robot execution pipelines.
Seedance 1.5 pro: A Native Audio-Visual Joint Generation Foundation Model
Dec 23, 2025Recent strides in video generation have paved the way for unified audio-visual generation. In this work, we present Seedance 1.5 pro, a foundational model engineered specifically for native, joint audio-video generation. Leveraging a dual-branch Diffusion Transformer architecture, the model integrates a cross-modal joint module with a specialized multi-stage data pipeline, achieving exceptional audio-visual synchronization and superior generation quality. To ensure practical utility, we implement meticulous post-training optimizations, including Supervised Fine-Tuning (SFT) on high-quality datasets and Reinforcement Learning from Human Feedback (RLHF) with multi-dimensional reward models. Furthermore, we introduce an acceleration framework that boosts inference speed by over 10X. Seedance 1.5 pro distinguishes itself through precise multilingual and dialect lip-syncing, dynamic cinematic camera control, and enhanced narrative coherence, positioning it as a robust engine for professional-grade content creation. Seedance 1.5 pro is now accessible on Volcano Engine at https://console.volcengine.com/ark/region:ark+cn-beijing/experience/vision?type=GenVideo.
OmniHuman-1.5: Instilling an Active Mind in Avatars via Cognitive Simulation
Aug 26, 2025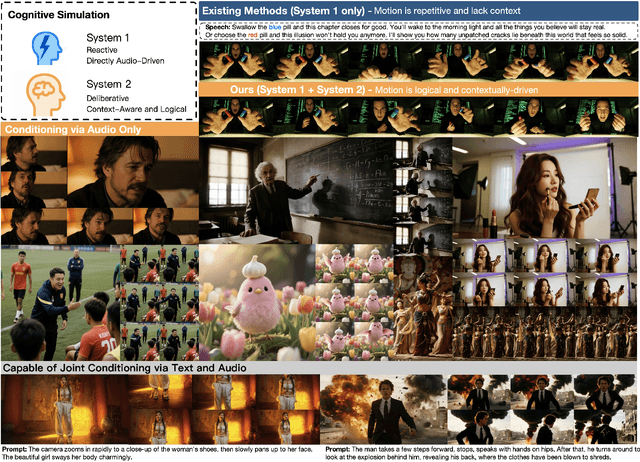
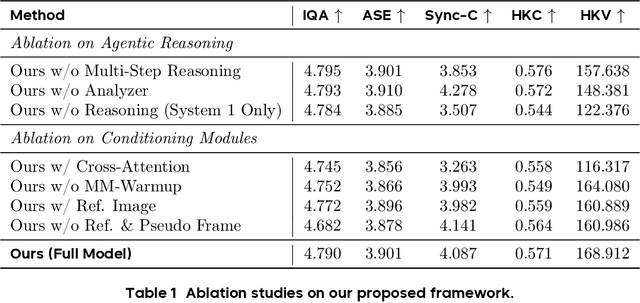
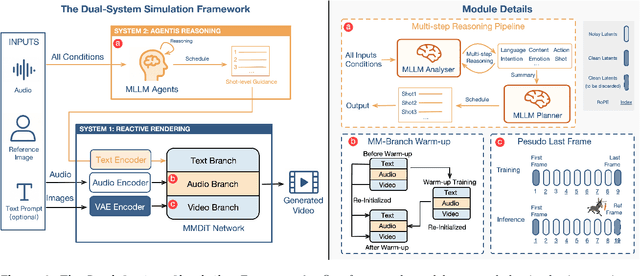

Existing video avatar models can produce fluid human animations, yet they struggle to move beyond mere physical likeness to capture a character's authentic essence. Their motions typically synchronize with low-level cues like audio rhythm, lacking a deeper semantic understanding of emotion, intent, or context. To bridge this gap, \textbf{we propose a framework designed to generate character animations that are not only physically plausible but also semantically coherent and expressive.} Our model, \textbf{OmniHuman-1.5}, is built upon two key technical contributions. First, we leverage Multimodal Large Language Models to synthesize a structured textual representation of conditions that provides high-level semantic guidance. This guidance steers our motion generator beyond simplistic rhythmic synchronization, enabling the production of actions that are contextually and emotionally resonant. Second, to ensure the effective fusion of these multimodal inputs and mitigate inter-modality conflicts, we introduce a specialized Multimodal DiT architecture with a novel Pseudo Last Frame design. The synergy of these components allows our model to accurately interpret the joint semantics of audio, images, and text, thereby generating motions that are deeply coherent with the character, scene, and linguistic content. Extensive experiments demonstrate that our model achieves leading performance across a comprehensive set of metrics, including lip-sync accuracy, video quality, motion naturalness and semantic consistency with textual prompts. Furthermore, our approach shows remarkable extensibility to complex scenarios, such as those involving multi-person and non-human subjects. Homepage: \href{https://omnihuman-lab.github.io/v1_5/}
InterActHuman: Multi-Concept Human Animation with Layout-Aligned Audio Conditions
Jun 11, 2025



End-to-end human animation with rich multi-modal conditions, e.g., text, image and audio has achieved remarkable advancements in recent years. However, most existing methods could only animate a single subject and inject conditions in a global manner, ignoring scenarios that multiple concepts could appears in the same video with rich human-human interactions and human-object interactions. Such global assumption prevents precise and per-identity control of multiple concepts including humans and objects, therefore hinders applications. In this work, we discard the single-entity assumption and introduce a novel framework that enforces strong, region-specific binding of conditions from modalities to each identity's spatiotemporal footprint. Given reference images of multiple concepts, our method could automatically infer layout information by leveraging a mask predictor to match appearance cues between the denoised video and each reference appearance. Furthermore, we inject local audio condition into its corresponding region to ensure layout-aligned modality matching in a iterative manner. This design enables the high-quality generation of controllable multi-concept human-centric videos. Empirical results and ablation studies validate the effectiveness of our explicit layout control for multi-modal conditions compared to implicit counterparts and other existing methods.
From Pixels to Images: Deep Learning Advances in Remote Sensing Image Semantic Segmentation
May 21, 2025Remote sensing images (RSIs) capture both natural and human-induced changes on the Earth's surface, serving as essential data for environmental monitoring, urban planning, and resource management. Semantic segmentation (SS) of RSIs enables the fine-grained interpretation of surface features, making it a critical task in remote sensing analysis. With the increasing diversity and volume of RSIs collected by sensors on various platforms, traditional processing methods struggle to maintain efficiency and accuracy. In response, deep learning (DL) has emerged as a transformative approach, enabling substantial advances in remote sensing image semantic segmentation (RSISS) by automating feature extraction and improving segmentation accuracy across diverse modalities. This paper revisits the evolution of DL-based RSISS by categorizing existing approaches into four stages: the early pixel-based methods, the prevailing patch-based and tile-based techniques, and the emerging image-based strategies enabled by foundation models. We analyze these developments from the perspective of feature extraction and learning strategies, revealing the field's progression from pixel-level to tile-level and from unimodal to multimodal segmentation. Furthermore, we conduct a comprehensive evaluation of nearly 40 advanced techniques on a unified dataset to quantitatively characterize their performance and applicability. This review offers a holistic view of DL-based SS for RS, highlighting key advancements, comparative insights, and open challenges to guide future research.