 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Depth Foundation Model: Recent Trends in Vision-Based Depth Estimation
Jul 15, 2025Depth estimation is a fundamental task in 3D computer vision, crucial for applications such as 3D reconstruction, free-viewpoint rendering, robotics, autonomous driving, and AR/VR technologies. Traditional methods relying on hardware sensors like LiDAR are often limited by high costs, low resolution, and environmental sensitivity, limiting their applicability in real-world scenarios. Recent advances in vision-based methods offer a promising alternative, yet they face challenges in generalization and stability due to either the low-capacity model architectures or the reliance on domain-specific and small-scale datasets. The emergence of scaling laws and foundation models in other domains has inspired the development of "depth foundation models": deep neural networks trained on large datasets with strong zero-shot generalization capabilities. This paper surveys the evolution of deep learning architectures and paradigms for depth estimation across the monocular, stereo, multi-view, and monocular video settings. We explore the potential of these models to address existing challenges and provide a comprehensive overview of large-scale datasets that can facilitate their development. By identifying key architectures and training strategies, we aim to highlight the path towards robust depth foundation models, offering insights into their future research and applications.
BoxDreamer: Dreaming Box Corners for Generalizable Object Pose Estimation
Apr 10, 2025This paper presents a generalizable RGB-based approach for object pose estimation, specifically designed to address challenges in sparse-view settings. While existing methods can estimate the poses of unseen objects, their generalization ability remains limited in scenarios involving occlusions and sparse reference views, restricting their real-world applicability. To overcome these limitations, we introduce corner points of the object bounding box as an intermediate representation of the object pose. The 3D object corners can be reliably recovered from sparse input views, while the 2D corner points in the target view are estimated through a novel reference-based point synthesizer, which works well even in scenarios involving occlusions. As object semantic points, object corners naturally establish 2D-3D correspondences for object pose estimation with a PnP algorithm. Extensive experiments on the YCB-Video and Occluded-LINEMOD datasets show that our approach outperforms state-of-the-art methods, highlighting the effectiveness of the proposed representation and significantly enhancing the generalization capabilities of object pose estimation, which is crucial for real-world applications.
MatchAnything: Universal Cross-Modality Image Matching with Large-Scale Pre-Training
Jan 13, 2025Image matching, which aims to identify corresponding pixel locations between images, is crucial in a wide range of scientific disciplines, aiding in image registration, fusion, and analysis. In recent years, deep learning-based image matching algorithms have dramatically outperformed humans in rapidly and accurately finding large amounts of correspondences. However, when dealing with images captured under different imaging modalities that result in significant appearance changes, the performance of these algorithms often deteriorates due to the scarcity of annotated cross-modal training data. This limitation hinders applications in various fields that rely on multiple image modalities to obtain complementary information. To address this challenge, we propose a large-scale pre-training framework that utilizes synthetic cross-modal training signals, incorporating diverse data from various sources, to train models to recognize and match fundamental structures across images. This capability is transferable to real-world, unseen cross-modality image matching tasks. Our key finding is that the matching model trained with our framework achieves remarkable generalizability across more than eight unseen cross-modality registration tasks using the same network weight, substantially outperforming existing methods, whether designed for generalization or tailored for specific tasks. This advancement significantly enhances the applicability of image matching technologies across various scientific disciplines and paves the way for new applications in multi-modality human and artificial intelligence analysis and beyond.
Efficient LoFTR: Semi-Dense Local Feature Matching with Sparse-Like Speed
Mar 11, 2024



We present a novel method for efficiently producing semi-dense matches across images. Previous detector-free matcher LoFTR has shown remarkable matching capability in handling large-viewpoint change and texture-poor scenarios but suffers from low efficiency. We revisit its design choices and derive multiple improvements for both efficiency and accuracy. One key observation is that performing the transformer over the entire feature map is redundant due to shared local information, therefore we propose an aggregated attention mechanism with adaptive token selection for efficiency. Furthermore, we find spatial variance exists in LoFTR's fine correlation module, which is adverse to matching accuracy. A novel two-stage correlation layer is proposed to achieve accurate subpixel correspondences for accuracy improvement. Our efficiency optimized model is $\sim 2.5\times$ faster than LoFTR which can even surpass state-of-the-art efficient sparse matching pipeline SuperPoint + LightGlue. Moreover, extensive experiments show that our method can achieve higher accuracy compared with competitive semi-dense matchers, with considerable efficiency benefits. This opens up exciting prospects for large-scale or latency-sensitive applications such as image retrieval and 3D reconstruction. Project page: https://zju3dv.github.io/efficientloftr.
Im4D: High-Fidelity and Real-Time Novel View Synthesis for Dynamic Scenes
Oct 12, 2023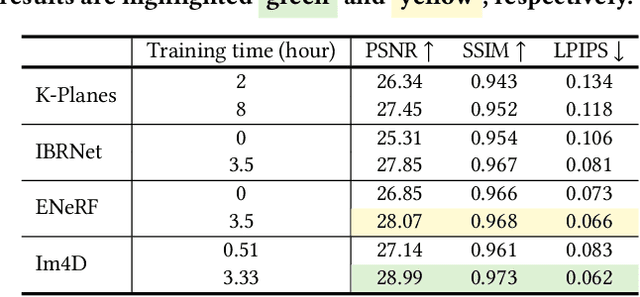
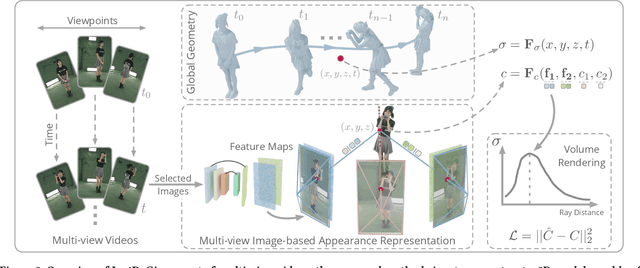

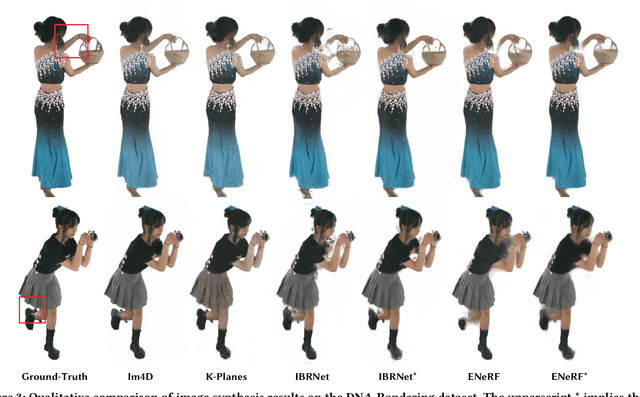
This paper aims to tackle the challenge of dynamic view synthesis from multi-view videos. The key observation is that while previous grid-based methods offer consistent rendering, they fall short in capturing appearance details of a complex dynamic scene, a domain where multi-view image-based rendering methods demonstrate the opposite properties. To combine the best of two worlds, we introduce Im4D, a hybrid scene representation that consists of a grid-based geometry representation and a multi-view image-based appearance representation. Specifically, the dynamic geometry is encoded as a 4D density function composed of spatiotemporal feature planes and a small MLP network, which globally models the scene structure and facilitates the rendering consistency. We represent the scene appearance by the original multi-view videos and a network that learns to predict the color of a 3D point from image features, instead of memorizing detailed appearance totally with networks, thereby naturally making the learning of networks easier. Our method is evaluated on five dynamic view synthesis datasets including DyNeRF, ZJU-MoCap, NHR, DNA-Rendering and ENeRF-Outdoor datasets. The results show that Im4D exhibits state-of-the-art performance in rendering quality and can be trained efficiently, while realizing real-time rendering with a speed of 79.8 FPS for 512x512 images, on a single RTX 3090 GPU.
Detector-Free Structure from Motion
Jun 27, 2023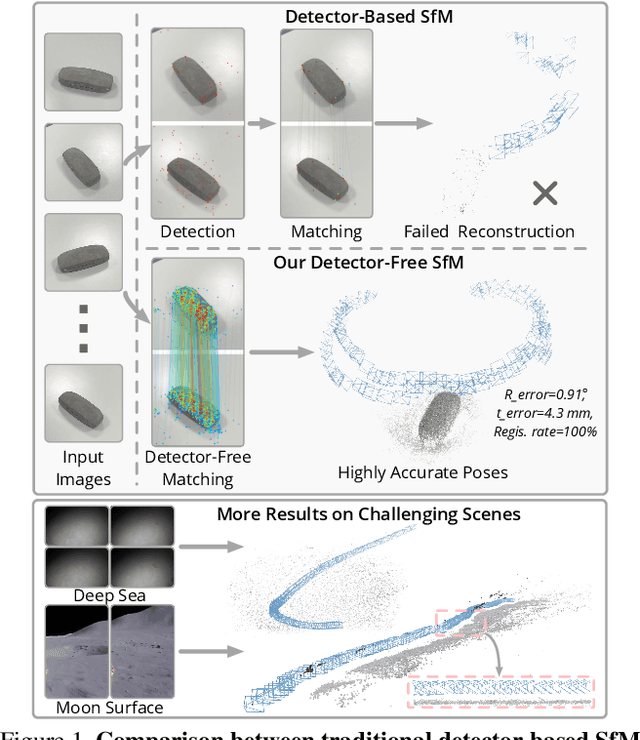
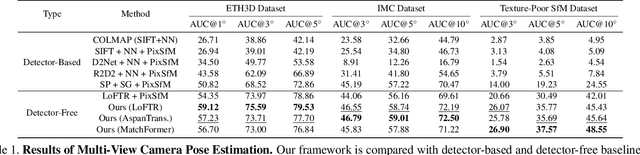
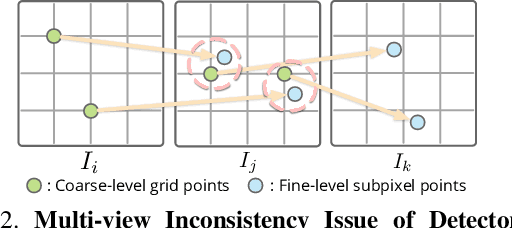
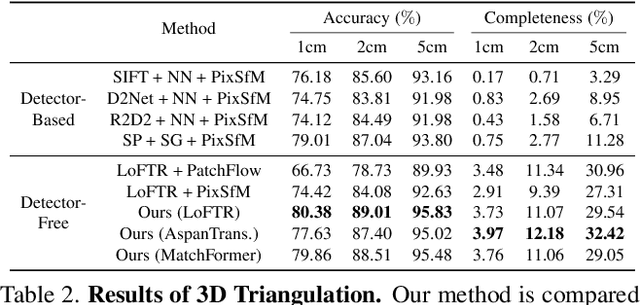
We propose a new structure-from-motion framework to recover accurate camera poses and point clouds from unordered images. Traditional SfM systems typically rely on the successful detection of repeatable keypoints across multiple views as the first step, which is difficult for texture-poor scenes, and poor keypoint detection may break down the whole SfM system. We propose a new detector-free SfM framework to draw benefits from the recent success of detector-free matchers to avoid the early determination of keypoints, while solving the multi-view inconsistency issue of detector-free matchers. Specifically, our framework first reconstructs a coarse SfM model from quantized detector-free matches. Then, it refines the model by a novel iterative refinement pipeline, which iterates between an attention-based multi-view matching module to refine feature tracks and a geometry refinement module to improve the reconstruction accuracy. Experiments demonstrate that the proposed framework outperforms existing detector-based SfM systems on common benchmark datasets. We also collect a texture-poor SfM dataset to demonstrate the capability of our framework to reconstruct texture-poor scenes. Based on this framework, we take $\textit{first place}$ in Image Matching Challenge 2023.
AutoRecon: Automated 3D Object Discovery and Reconstruction
May 15, 2023A fully automated object reconstruction pipeline is crucial for digital content creation. While the area of 3D reconstruction has witnessed profound developments, the removal of background to obtain a clean object model still relies on different forms of manual labor, such as bounding box labeling, mask annotations, and mesh manipulations. In this paper, we propose a novel framework named AutoRecon for the automated discovery and reconstruction of an object from multi-view images. We demonstrate that foreground objects can be robustly located and segmented from SfM point clouds by leveraging self-supervised 2D vision transformer features. Then, we reconstruct decomposed neural scene representations with dense supervision provided by the decomposed point clouds, resulting in accurate object reconstruction and segmentation. Experiments on the DTU, BlendedMVS and CO3D-V2 datasets demonstrate the effectiveness and robustness of AutoRecon.
OnePose++: Keypoint-Free One-Shot Object Pose Estimation without CAD Models
Jan 18, 2023

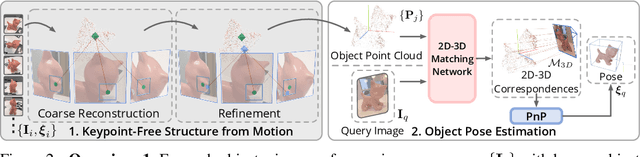

We propose a new method for object pose estimation without CAD models. The previous feature-matching-based method OnePose has shown promising results under a one-shot setting which eliminates the need for CAD models or object-specific training. However, OnePose relies on detecting repeatable image keypoints and is thus prone to failure on low-textured objects. We propose a keypoint-free pose estimation pipeline to remove the need for repeatable keypoint detection. Built upon the detector-free feature matching method LoFTR, we devise a new keypoint-free SfM method to reconstruct a semi-dense point-cloud model for the object. Given a query image for object pose estimation, a 2D-3D matching network directly establishes 2D-3D correspondences between the query image and the reconstructed point-cloud model without first detecting keypoints in the image. Experiments show that the proposed pipeline outperforms existing one-shot CAD-model-free methods by a large margin and is comparable to CAD-model-based methods on LINEMOD even for low-textured objects. We also collect a new dataset composed of 80 sequences of 40 low-textured objects to facilitate future research on one-shot object pose estimation. The supplementary material, code and dataset are available on the project page: https://zju3dv.github.io/onepose_plus_plus/.
Reconstructing Hand-Held Objects from Monocular Video
Nov 30, 2022
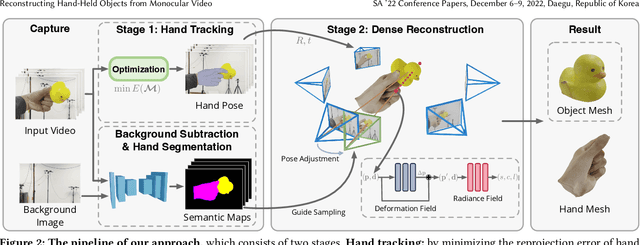


This paper presents an approach that reconstructs a hand-held object from a monocular video. In contrast to many recent methods that directly predict object geometry by a trained network, the proposed approach does not require any learned prior about the object and is able to recover more accurate and detailed object geometry. The key idea is that the hand motion naturally provides multiple views of the object and the motion can be reliably estimated by a hand pose tracker. Then, the object geometry can be recovered by solving a multi-view reconstruction problem. We devise an implicit neural representation-based method to solve the reconstruction problem and address the issues of imprecise hand pose estimation, relative hand-object motion, and insufficient geometry optimization for small objects. We also provide a newly collected dataset with 3D ground truth to validate the proposed approach.
OnePose: One-Shot Object Pose Estimation without CAD Models
May 24, 2022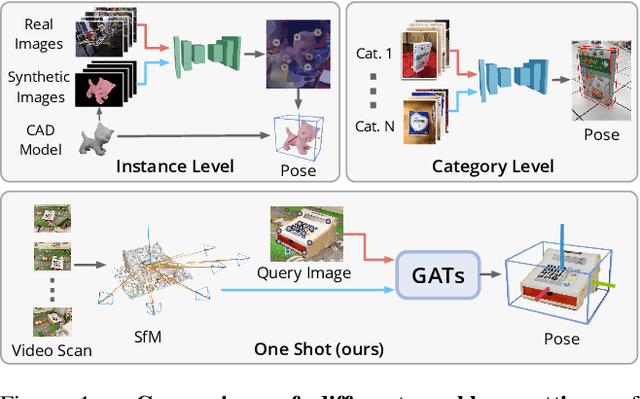

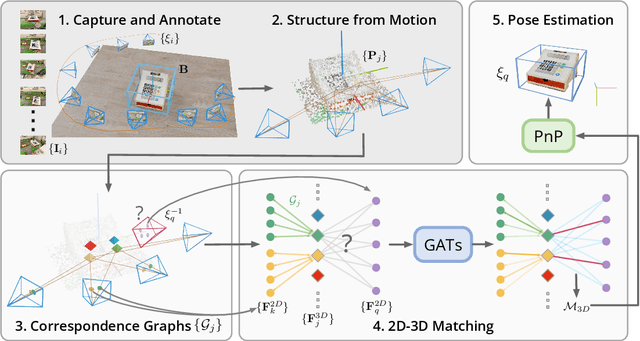
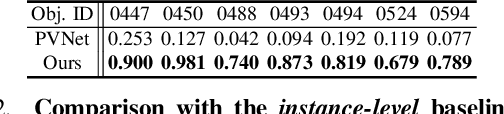
We propose a new method named OnePose for object pose estimation. Unlike existing instance-level or category-level methods, OnePose does not rely on CAD models and can handle objects in arbitrary categories without instance- or category-specific network training. OnePose draws the idea from visual localization and only requires a simple RGB video scan of the object to build a sparse SfM model of the object. Then, this model is registered to new query images with a generic feature matching network. To mitigate the slow runtime of existing visual localization methods, we propose a new graph attention network that directly matches 2D interest points in the query image with the 3D points in the SfM model, resulting in efficient and robust pose estimation. Combined with a feature-based pose tracker, OnePose is able to stably detect and track 6D poses of everyday household objects in real-time. We also collected a large-scale dataset that consists of 450 sequences of 150 objects.