 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePRISM: Streaming Human Motion Generation with Per-Joint Latent Decomposition
Mar 10, 2026Text-to-motion generation has advanced rapidly, yet two challenges persist. First, existing motion autoencoders compress each frame into a single monolithic latent vector, entangling trajectory and per-joint rotations in an unstructured representation that downstream generators struggle to model faithfully. Second, text-to-motion, pose-conditioned generation, and long-horizon sequential synthesis typically require separate models or task-specific mechanisms, with autoregressive approaches suffering from severe error accumulation over extended rollouts. We present PRISM, addressing each challenge with a dedicated contribution. (1) A joint-factorized motion latent space: each body joint occupies its own token, forming a structured 2D grid (time joints) compressed by a causal VAE with forward-kinematics supervision. This simple change to the latent space -- without modifying the generator -- substantially improves generation quality, revealing that latent space design has been an underestimated bottleneck. (2) Noise-free condition injection: each latent token carries its own timestep embedding, allowing conditioning frames to be injected as clean tokens (timestep0) while the remaining tokens are denoised. This unifies text-to-motion and pose-conditioned generation in a single model, and directly enables autoregressive segment chaining for streaming synthesis. Self-forcing training further suppresses drift in long rollouts. With these two components, we train a single motion generation foundation model that seamlessly handles text-to-motion, pose-conditioned generation, autoregressive sequential generation, and narrative motion composition, achieving state-of-the-art on HumanML3D, MotionHub, BABEL, and a 50-scenario user study.
CoMoVi: Co-Generation of 3D Human Motions and Realistic Videos
Jan 15, 2026In this paper, we find that the generation of 3D human motions and 2D human videos is intrinsically coupled. 3D motions provide the structural prior for plausibility and consistency in videos, while pre-trained video models offer strong generalization capabilities for motions, which necessitate coupling their generation processes. Based on this, we present CoMoVi, a co-generative framework that couples two video diffusion models (VDMs) to generate 3D human motions and videos synchronously within a single diffusion denoising loop. To achieve this, we first propose an effective 2D human motion representation that can inherit the powerful prior of pre-trained VDMs. Then, we design a dual-branch diffusion model to couple human motion and video generation process with mutual feature interaction and 3D-2D cross attentions. Moreover, we curate CoMoVi Dataset, a large-scale real-world human video dataset with text and motion annotations, covering diverse and challenging human motions. Extensive experiments demonstrate the effectiveness of our method in both 3D human motion and video generation tasks.
HY-Motion 1.0: Scaling Flow Matching Models for Text-To-Motion Generation
Dec 29, 2025We present HY-Motion 1.0, a series of state-of-the-art, large-scale, motion generation models capable of generating 3D human motions from textual descriptions. HY-Motion 1.0 represents the first successful attempt to scale up Diffusion Transformer (DiT)-based flow matching models to the billion-parameter scale within the motion generation domain, delivering instruction-following capabilities that significantly outperform current open-source benchmarks. Uniquely, we introduce a comprehensive, full-stage training paradigm -- including large-scale pretraining on over 3,000 hours of motion data, high-quality fine-tuning on 400 hours of curated data, and reinforcement learning from both human feedback and reward models -- to ensure precise alignment with the text instruction and high motion quality. This framework is supported by our meticulous data processing pipeline, which performs rigorous motion cleaning and captioning. Consequently, our model achieves the most extensive coverage, spanning over 200 motion categories across 6 major classes. We release HY-Motion 1.0 to the open-source community to foster future research and accelerate the transition of 3D human motion generation models towards commercial maturity.
Ready-to-React: Online Reaction Policy for Two-Character Interaction Generation
Feb 27, 2025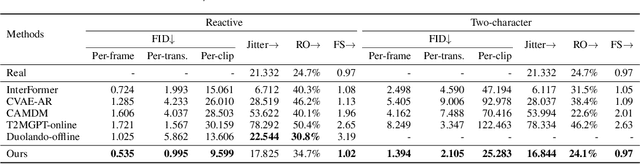
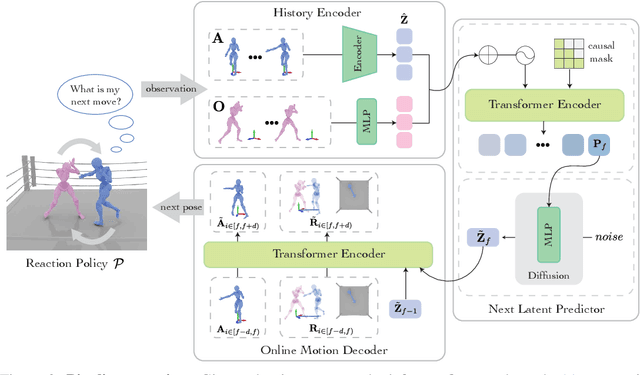
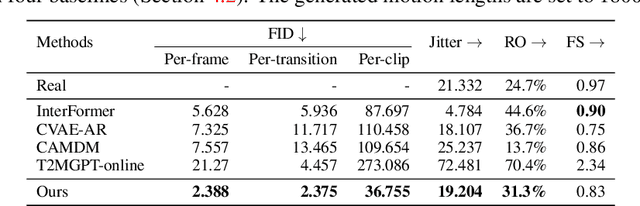
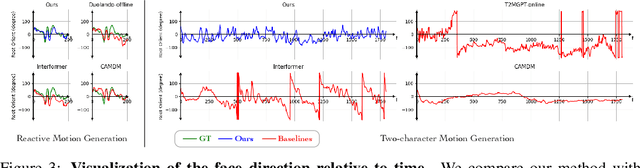
This paper addresses the task of generating two-character online interactions. Previously, two main settings existed for two-character interaction generation: (1) generating one's motions based on the counterpart's complete motion sequence, and (2) jointly generating two-character motions based on specific conditions. We argue that these settings fail to model the process of real-life two-character interactions, where humans will react to their counterparts in real time and act as independent individuals. In contrast, we propose an online reaction policy, called Ready-to-React, to generate the next character pose based on past observed motions. Each character has its own reaction policy as its "brain", enabling them to interact like real humans in a streaming manner. Our policy is implemented by incorporating a diffusion head into an auto-regressive model, which can dynamically respond to the counterpart's motions while effectively mitigating the error accumulation throughout the generation process. We conduct comprehensive experiments using the challenging boxing task. Experimental results demonstrate that our method outperforms existing baselines and can generate extended motion sequences. Additionally, we show that our approach can be controlled by sparse signals, making it well-suited for VR and other online interactive environments.
IDOL: Instant Photorealistic 3D Human Creation from a Single Image
Dec 19, 2024



Creating a high-fidelity, animatable 3D full-body avatar from a single image is a challenging task due to the diverse appearance and poses of humans and the limited availability of high-quality training data. To achieve fast and high-quality human reconstruction, this work rethinks the task from the perspectives of dataset, model, and representation. First, we introduce a large-scale HUman-centric GEnerated dataset, HuGe100K, consisting of 100K diverse, photorealistic sets of human images. Each set contains 24-view frames in specific human poses, generated using a pose-controllable image-to-multi-view model. Next, leveraging the diversity in views, poses, and appearances within HuGe100K, we develop a scalable feed-forward transformer model to predict a 3D human Gaussian representation in a uniform space from a given human image. This model is trained to disentangle human pose, body shape, clothing geometry, and texture. The estimated Gaussians can be animated without post-processing. We conduct comprehensive experiments to validate the effectiveness of the proposed dataset and method. Our model demonstrates the ability to efficiently reconstruct photorealistic humans at 1K resolution from a single input image using a single GPU instantly. Additionally, it seamlessly supports various applications, as well as shape and texture editing tasks.
Motion-2-to-3: Leveraging 2D Motion Data to Boost 3D Motion Generation
Dec 17, 2024Text-driven human motion synthesis is capturing significant attention for its ability to effortlessly generate intricate movements from abstract text cues, showcasing its potential for revolutionizing motion design not only in film narratives but also in virtual reality experiences and computer game development. Existing methods often rely on 3D motion capture data, which require special setups resulting in higher costs for data acquisition, ultimately limiting the diversity and scope of human motion. In contrast, 2D human videos offer a vast and accessible source of motion data, covering a wider range of styles and activities. In this paper, we explore leveraging 2D human motion extracted from videos as an alternative data source to improve text-driven 3D motion generation. Our approach introduces a novel framework that disentangles local joint motion from global movements, enabling efficient learning of local motion priors from 2D data. We first train a single-view 2D local motion generator on a large dataset of text-motion pairs. To enhance this model to synthesize 3D motion, we fine-tune the generator with 3D data, transforming it into a multi-view generator that predicts view-consistent local joint motion and root dynamics. Experiments on the HumanML3D dataset and novel text prompts demonstrate that our method efficiently utilizes 2D data, supporting realistic 3D human motion generation and broadening the range of motion types it supports. Our code will be made publicly available at https://zju3dv.github.io/Motion-2-to-3/.
AnchorCrafter: Animate CyberAnchors Saling Your Products via Human-Object Interacting Video Generation
Nov 26, 2024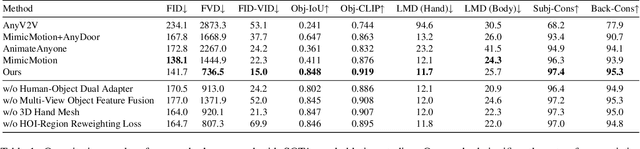

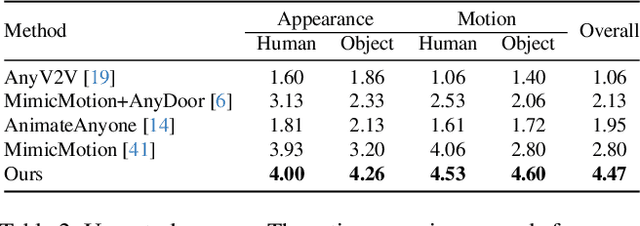
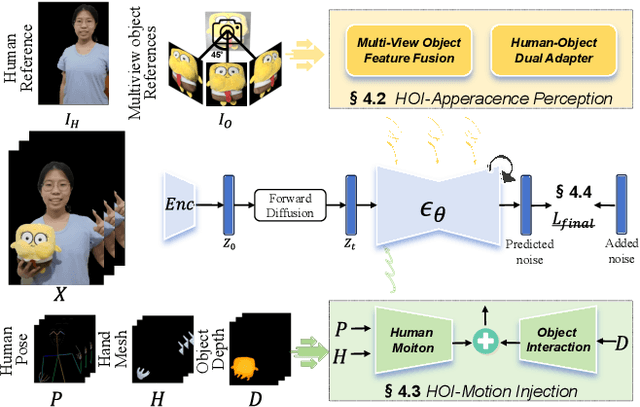
The automatic generation of anchor-style product promotion videos presents promising opportunities in online commerce, advertising, and consumer engagement. However, this remains a challenging task despite significant advancements in pose-guided human video generation. In addressing this challenge, we identify the integration of human-object interactions (HOI) into pose-guided human video generation as a core issue. To this end, we introduce AnchorCrafter, a novel diffusion-based system designed to generate 2D videos featuring a target human and a customized object, achieving high visual fidelity and controllable interactions. Specifically, we propose two key innovations: the HOI-appearance perception, which enhances object appearance recognition from arbitrary multi-view perspectives and disentangles object and human appearance, and the HOI-motion injection, which enables complex human-object interactions by overcoming challenges in object trajectory conditioning and inter-occlusion management. Additionally, we introduce the HOI-region reweighting loss, a training objective that enhances the learning of object details. Extensive experiments demonstrate that our proposed system outperforms existing methods in preserving object appearance and shape awareness, while simultaneously maintaining consistency in human appearance and motion. Project page: https://cangcz.github.io/Anchor-Crafter/
Reconstructing Close Human Interactions from Multiple Views
Jan 29, 2024



This paper addresses the challenging task of reconstructing the poses of multiple individuals engaged in close interactions, captured by multiple calibrated cameras. The difficulty arises from the noisy or false 2D keypoint detections due to inter-person occlusion, the heavy ambiguity in associating keypoints to individuals due to the close interactions, and the scarcity of training data as collecting and annotating motion data in crowded scenes is resource-intensive. We introduce a novel system to address these challenges. Our system integrates a learning-based pose estimation component and its corresponding training and inference strategies. The pose estimation component takes multi-view 2D keypoint heatmaps as input and reconstructs the pose of each individual using a 3D conditional volumetric network. As the network doesn't need images as input, we can leverage known camera parameters from test scenes and a large quantity of existing motion capture data to synthesize massive training data that mimics the real data distribution in test scenes. Extensive experiments demonstrate that our approach significantly surpasses previous approaches in terms of pose accuracy and is generalizable across various camera setups and population sizes. The code is available on our project page: https://github.com/zju3dv/CloseMoCap.
* SIGGRAPH Asia 2023
AniDress: Animatable Loose-Dressed Avatar from Sparse Views Using Garment Rigging Model
Jan 27, 2024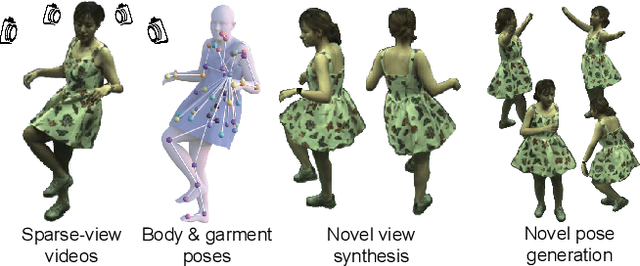



Recent communities have seen significant progress in building photo-realistic animatable avatars from sparse multi-view videos. However, current workflows struggle to render realistic garment dynamics for loose-fitting characters as they predominantly rely on naked body models for human modeling while leaving the garment part un-modeled. This is mainly due to that the deformations yielded by loose garments are highly non-rigid, and capturing such deformations often requires dense views as supervision. In this paper, we introduce AniDress, a novel method for generating animatable human avatars in loose clothes using very sparse multi-view videos (4-8 in our setting). To allow the capturing and appearance learning of loose garments in such a situation, we employ a virtual bone-based garment rigging model obtained from physics-based simulation data. Such a model allows us to capture and render complex garment dynamics through a set of low-dimensional bone transformations. Technically, we develop a novel method for estimating temporal coherent garment dynamics from a sparse multi-view video. To build a realistic rendering for unseen garment status using coarse estimations, a pose-driven deformable neural radiance field conditioned on both body and garment motions is introduced, providing explicit control of both parts. At test time, the new garment poses can be captured from unseen situations, derived from a physics-based or neural network-based simulator to drive unseen garment dynamics. To evaluate our approach, we create a multi-view dataset that captures loose-dressed performers with diverse motions. Experiments show that our method is able to render natural garment dynamics that deviate highly from the body and generalize well to both unseen views and poses, surpassing the performance of existing methods. The code and data will be publicly available.
EasyVolcap: Accelerating Neural Volumetric Video Research
Dec 11, 2023



Volumetric video is a technology that digitally records dynamic events such as artistic performances, sporting events, and remote conversations. When acquired, such volumography can be viewed from any viewpoint and timestamp on flat screens, 3D displays, or VR headsets, enabling immersive viewing experiences and more flexible content creation in a variety of applications such as sports broadcasting, video conferencing, gaming, and movie productions. With the recent advances and fast-growing interest in neural scene representations for volumetric video, there is an urgent need for a unified open-source library to streamline the process of volumetric video capturing, reconstruction, and rendering for both researchers and non-professional users to develop various algorithms and applications of this emerging technology. In this paper, we present EasyVolcap, a Python & Pytorch library for accelerating neural volumetric video research with the goal of unifying the process of multi-view data processing, 4D scene reconstruction, and efficient dynamic volumetric video rendering. Our source code is available at https://github.com/zju3dv/EasyVolcap.