 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatial Transcriptomics-Guided Alignment Enhances Molecular Profiling in Pathology Foundation Model
May 29, 2026Comprehensive molecular profiling is essential for modern precision oncology but remains hindered by prohibitive costs, specimen exhaustion, and protracted turnaround times. While pathology foundation models (PFMs) have demonstrated potential for inferring molecular phenotypes from routine hematoxylin and eosin (H&E) whole-slide images (WSIs), current architectures primarily rely on vision-centric self-supervised learning or vision-language alignment, lacking the spatially resolved molecular supervision required to connect subtle morphological features with underlying genomic alterations. Spatial transcriptomics (ST) emerges as a transformative technology that enables transcriptomic quantification within intact tissue sections, thereby preserving the precise spatial link between histology and molecular profiles. In this study, we present a Spatial Transcriptomics-guided Alignment framework for Molecular Profiling (STAMP), which endows PFMs with intrinsic molecular awareness. To support this paradigm, we curated HumanST-1k, a human ST dataset spanning diverse anatomical organs and sequencing platforms. This atlas yields 1.8 million pairs of H&E patches and corresponding transcriptomic profiles, providing a corpus that links histological structures with their molecular states. To mitigate the technical noise inherent to raw transcriptomics, STAMP applies a pathway-informed alignment strategy that aggregates transcriptomic data into biologically functional pathways, which are subsequently integrated into PFMs via parameter-efficient fine-tuning. This alignment enriches the representation space of PFMs and unlocks their capacity to resolve sub-visual molecular signatures. The clinical utility of these augmented representations was validated through a multi-tier evaluation framework.
A Decade-Scale Benchmark Evaluating LLMs' Clinical Practice Guidelines Detection and Adherence in Multi-turn Conversations
Mar 26, 2026Clinical practice guidelines (CPGs) play a pivotal role in ensuring evidence-based decision-making and improving patient outcomes. While Large Language Models (LLMs) are increasingly deployed in healthcare scenarios, it is unclear to which extend LLMs could identify and adhere to CPGs during conversations. To address this gap, we introduce CPGBench, an automated framework benchmarking the clinical guideline detection and adherence capabilities of LLMs in multi-turn conversations. We collect 3,418 CPG documents from 9 countries/regions and 2 international organizations published in the last decade spanning across 24 specialties. From these documents, we extract 32,155 clinical recommendations with corresponding publication institute, date, country, specialty, recommendation strength, evidence level, etc. One multi-turn conversation is generated for each recommendation accordingly to evaluate the detection and adherence capabilities of 8 leading LLMs. We find that the 71.1%-89.6% recommendations can be correctly detected, while only 3.6%-29.7% corresponding titles can be correctly referenced, revealing the gap between knowing the guideline contents and where they come from. The adherence rates range from 21.8% to 63.2% in different models, indicating a large gap between knowing the guidelines and being able to apply them. To confirm the validity of our automatic analysis, we further conduct a comprehensive human evaluation involving 56 clinicians from different specialties. To our knowledge, CPGBench is the first benchmark systematically revealing which clinical recommendations LLMs fail to detect or adhere to during conversations. Given that each clinical recommendation may affect a large population and that clinical applications are inherently safety critical, addressing these gaps is crucial for the safe and responsible deployment of LLMs in real world clinical practice.
Progressive Residual Warmup for Language Model Pretraining
Mar 05, 2026Transformer architectures serve as the backbone for most modern Large Language Models, therefore their pretraining stability and convergence speed are of central concern. Motivated by the logical dependency of sequentially stacked layers, we propose Progressive Residual Warmup (ProRes) for language model pretraining. ProRes implements an "early layer learns first" philosophy by multiplying each layer's residual with a scalar that gradually warms up from 0 to 1, with deeper layers taking longer warmup steps. In this way, deeper layers wait for early layers to settle into a more stable regime before contributing to learning. We demonstrate the effectiveness of ProRes through pretraining experiments across various model scales, as well as normalization and initialization schemes. Comprehensive analysis shows that ProRes not only stabilizes pretraining but also introduces a unique optimization trajectory, leading to faster convergence, stronger generalization and better downstream performance. Our code is available at https://github.com/dandingsky/ProRes.
SyncTrack: Rhythmic Stability and Synchronization in Multi-Track Music Generation
Mar 01, 2026Multi-track music generation has garnered significant research interest due to its precise mixing and remixing capabilities. However, existing models often overlook essential attributes such as rhythmic stability and synchronization, leading to a focus on differences between tracks rather than their inherent properties. In this paper, we introduce SyncTrack, a synchronous multi-track waveform music generation model designed to capture the unique characteristics of multi-track music. SyncTrack features a novel architecture that includes track-shared modules to establish a common rhythm across all tracks and track-specific modules to accommodate diverse timbres and pitch ranges. Each track-shared module employs two cross-track attention mechanisms to synchronize rhythmic information, while each track-specific module utilizes learnable instrument priors to better represent timbre and other unique features. Additionally, we enhance the evaluation of multi-track music quality by introducing rhythmic consistency through three novel metrics: Inner-track Rhythmic Stability (IRS), Cross-track Beat Synchronization (CBS), and Cross-track Beat Dispersion (CBD). Experiments demonstrate that SyncTrack significantly improves the multi-track music quality by enhancing rhythmic consistency.
A Deployment-Friendly Foundational Framework for Efficient Computational Pathology
Feb 15, 2026Pathology foundation models (PFMs) have enabled robust generalization in computational pathology through large-scale datasets and expansive architectures, but their substantial computational cost, particularly for gigapixel whole slide images, limits clinical accessibility and scalability. Here, we present LitePath, a deployment-friendly foundational framework designed to mitigate model over-parameterization and patch level redundancy. LitePath integrates LiteFM, a compact model distilled from three large PFMs (Virchow2, H-Optimus-1 and UNI2) using 190 million patches, and the Adaptive Patch Selector (APS), a lightweight component for task-specific patch selection. The framework reduces model parameters by 28x and lowers FLOPs by 403.5x relative to Virchow2, enabling deployment on low-power edge hardware such as the NVIDIA Jetson Orin Nano Super. On this device, LitePath processes 208 slides per hour, 104.5x faster than Virchow2, and consumes 0.36 kWh per 3,000 slides, 171x lower than Virchow2 on an RTX3090 GPU. We validated accuracy using 37 cohorts across four organs and 26 tasks (26 internal, 9 external, and 2 prospective), comprising 15,672 slides from 9,808 patients disjoint from the pretraining data. LitePath ranks second among 19 evaluated models and outperforms larger models including H-Optimus-1, mSTAR, UNI2 and GPFM, while retaining 99.71% of the AUC of Virchow2 on average. To quantify the balance between accuracy and efficiency, we propose the Deployability Score (D-Score), defined as the weighted geometric mean of normalized AUC and normalized FLOP, where LitePath achieves the highest value, surpassing Virchow2 by 10.64%. These results demonstrate that LitePath enables rapid, cost-effective and energy-efficient pathology image analysis on accessible hardware while maintaining accuracy comparable to state-of-the-art PFMs and reducing the carbon footprint of AI deployment.
Composition-RL: Compose Your Verifiable Prompts for Reinforcement Learning of Large Language Models
Feb 12, 2026Large-scale verifiable prompts underpin the success of Reinforcement Learning with Verifiable Rewards (RLVR), but they contain many uninformative examples and are costly to expand further. Recent studies focus on better exploiting limited training data by prioritizing hard prompts whose rollout pass rate is 0. However, easy prompts with a pass rate of 1 also become increasingly prevalent as training progresses, thereby reducing the effective data size. To mitigate this, we propose Composition-RL, a simple yet useful approach for better utilizing limited verifiable prompts targeting pass-rate-1 prompts. More specifically, Composition-RL automatically composes multiple problems into a new verifiable question and uses these compositional prompts for RL training. Extensive experiments across model sizes from 4B to 30B show that Composition-RL consistently improves reasoning capability over RL trained on the original dataset. Performance can be further boosted with a curriculum variant of Composition-RL that gradually increases compositional depth over training. Additionally, Composition-RL enables more effective cross-domain RL by composing prompts drawn from different domains. Codes, datasets, and models are available at https://github.com/XinXU-USTC/Composition-RL.
PEGNet: A Physics-Embedded Graph Network for Long-Term Stable Multiphysics Simulation
Nov 11, 2025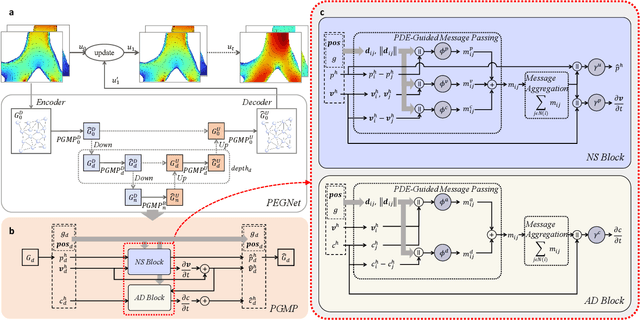
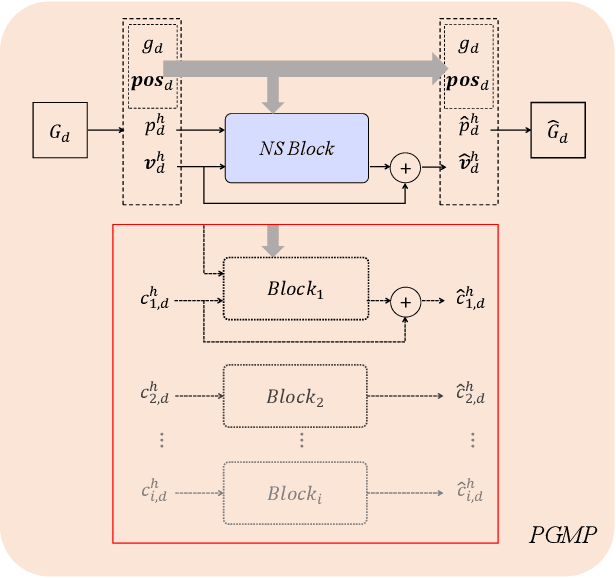
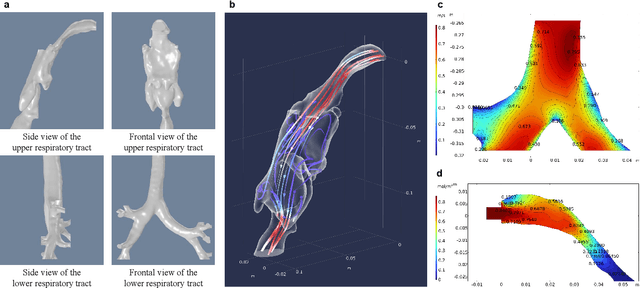
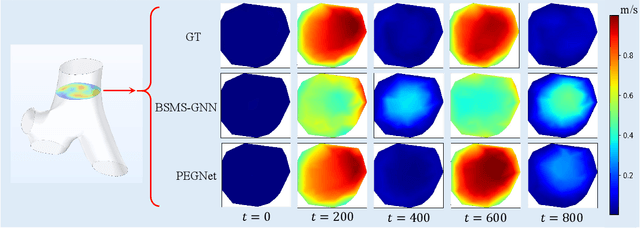
Accurate and efficient simulations of physical phenomena governed by partial differential equations (PDEs) are important for scientific and engineering progress. While traditional numerical solvers are powerful, they are often computationally expensive. Recently, data-driven methods have emerged as alternatives, but they frequently suffer from error accumulation and limited physical consistency, especially in multiphysics and complex geometries. To address these challenges, we propose PEGNet, a Physics-Embedded Graph Network that incorporates PDE-guided message passing to redesign the graph neural network architecture. By embedding key PDE dynamics like convection, viscosity, and diffusion into distinct message functions, the model naturally integrates physical constraints into its forward propagation, producing more stable and physically consistent solutions. Additionally, a hierarchical architecture is employed to capture multi-scale features, and physical regularization is integrated into the loss function to further enforce adherence to governing physics. We evaluated PEGNet on benchmarks, including custom datasets for respiratory airflow and drug delivery, showing significant improvements in long-term prediction accuracy and physical consistency over existing methods. Our code is available at https://github.com/Yanghuoshan/PEGNet.
Distilled Prompt Learning for Incomplete Multimodal Survival Prediction
Mar 03, 2025The integration of multimodal data including pathology images and gene profiles is widely applied in precise survival prediction. Despite recent advances in multimodal survival models, collecting complete modalities for multimodal fusion still poses a significant challenge, hindering their application in clinical settings. Current approaches tackling incomplete modalities often fall short, as they typically compensate for only a limited part of the knowledge of missing modalities. To address this issue, we propose a Distilled Prompt Learning framework (DisPro) to utilize the strong robustness of Large Language Models (LLMs) to missing modalities, which employs two-stage prompting for compensation of comprehensive information for missing modalities. In the first stage, Unimodal Prompting (UniPro) distills the knowledge distribution of each modality, preparing for supplementing modality-specific knowledge of the missing modality in the subsequent stage. In the second stage, Multimodal Prompting (MultiPro) leverages available modalities as prompts for LLMs to infer the missing modality, which provides modality-common information. Simultaneously, the unimodal knowledge acquired in the first stage is injected into multimodal inference to compensate for the modality-specific knowledge of the missing modality. Extensive experiments covering various missing scenarios demonstrated the superiority of the proposed method. The code is available at https://github.com/Innse/DisPro.
Learning with Noisy Labels: the Exploration of Error Bounds in Classification
Jan 25, 2025Numerous studies have shown that label noise can lead to poor generalization performance, negatively affecting classification accuracy. Therefore, understanding the effectiveness of classifiers trained using deep neural networks in the presence of noisy labels is of considerable practical significance. In this paper, we focus on the error bounds of excess risks for classification problems with noisy labels within deep learning frameworks. We begin by exploring loss functions with noise-tolerant properties, ensuring that the empirical minimizer on noisy data aligns with that on the true data. Next, we estimate the error bounds of the excess risks, expressed as a sum of statistical error and approximation error. We estimate the statistical error on a dependent (mixing) sequence, bounding it with the help of the associated independent block sequence. For the approximation error, we first express the classifiers as the composition of the softmax function and a continuous function from $[0,1]^d$ to $\mathbb{R}^K$. The main task is then to estimate the approximation error for the continuous function from $[0,1]^d$ to $\mathbb{R}^K$. Finally, we focus on the curse of dimensionality based on the low-dimensional manifold assumption.
UGMathBench: A Diverse and Dynamic Benchmark for Undergraduate-Level Mathematical Reasoning with Large Language Models
Jan 23, 2025Large Language Models (LLMs) have made significant strides in mathematical reasoning, underscoring the need for a comprehensive and fair evaluation of their capabilities. However, existing benchmarks often fall short, either lacking extensive coverage of undergraduate-level mathematical problems or probably suffering from test-set contamination. To address these issues, we introduce UGMathBench, a diverse and dynamic benchmark specifically designed for evaluating undergraduate-level mathematical reasoning with LLMs. UGMathBench comprises 5,062 problems across 16 subjects and 111 topics, featuring 10 distinct answer types. Each problem includes three randomized versions, with additional versions planned for release as leading open-source LLMs become saturated in UGMathBench. Furthermore, we propose two key metrics: effective accuracy (EAcc), which measures the percentage of correctly solved problems across all three versions, and reasoning gap ($\Delta$), which assesses reasoning robustness by calculating the difference between the average accuracy across all versions and EAcc. Our extensive evaluation of 23 leading LLMs reveals that the highest EAcc achieved is 56.3\% by OpenAI-o1-mini, with large $\Delta$ values observed across different models. This highlights the need for future research aimed at developing "large reasoning models" with high EAcc and $\Delta = 0$. We anticipate that the release of UGMathBench, along with its detailed evaluation codes, will serve as a valuable resource to advance the development of LLMs in solving mathematical problems.
* Accepted to ICLR 2025