 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLast But Not Least: Boundary Attention CalibratiON for Multimodal KV Cache Compression
Jun 16, 2026Multimodal Large Language Models (MLLMs) achieve strong vision-language reasoning, but long visual contexts enlarge the KV cache and increase decoding latency. Existing compression methods rely on observation window attention for stable token-importance estimation, yet this aggregation can dilute sparse visual evidence and discard answer-critical tokens under aggressive compression. Therefore, we identify last-query attention as a complementary source for recovering such evidence, but its answer-irrelevant signals can mislead retention. We propose BACON, a plug-and-play method that calibrates observation window attention with last-query evidence and suppresses isolated noise via intra-layer coherence and inter-layer persistence. Across diverse benchmarks, models, budgets, and compression methods, BACON improves multimodal KV compression by 7.5% on average under the most aggressive budget, with gains up to 30.9%. Our project page is available at https://ryu1ion.github.io/official_BACON/
LACO: Adaptive Latent Communication for Collaborative Driving
May 21, 2026Collaborative driving aims to improve safety and efficiency by enabling connected vehicles to coordinate under partial observability. Recent approaches have evolved from sharing visual features for perception to exchanging language-based reasoning through foundation models for behavioral coordination. Though communicating in language provides intuitive information, it introduces two challenges: high latency caused by autoregressive decoding and information loss caused by compressing rich internal representations into discrete tokens. To address these challenges, we analyze latent communication in collaborative driving under inherent limitations of multi-agent settings. Our analysis reveals agent identity confusion, where direct fusion of latent states entangles decision representations across vehicles. Motivated by this, we propose LACO, a training-free \textbf{LA}tent \textbf{CO}mmunication paradigm that seamlessly adapts pretrained driving models to collaborative settings. LACO introduces Iterative Latent Deliberation (ILD) for latent reasoning, Cross-Horizon Saliency Attribution (CHSA) for communication-efficient information selection, and Structured Semantic Knowledge Distillation (SSKD) to stabilize ego-centric decision making. Closed-loop experiments in CARLA show that LACO notably reduces communication and inference latency while maintaining strong collaborative driving performance.
Delta Forcing: Trust Region Steering for Interactive Autoregressive Video Generation
May 14, 2026Interactive real-time autoregressive video generation is essential for applications such as content creation and world modeling, where visual content must adapt to dynamically evolving event conditions. A fundamental challenge lies in balancing reactivity and stability: models must respond promptly to new events while maintaining temporal coherence over long horizons. Existing approaches distill bidirectional models into autoregressive generators and further adapt them via streaming long tuning, yet often exhibit persistent drift after condition changes. We identify the cause as conditional bias, where the teacher may provide condition-aligned but trajectory-agnostic guidance, biasing generation toward locally valid yet globally inconsistent modes. Inspired by Trust Region Policy Optimization, we propose Delta Forcing, a simple yet effective framework that constrains unreliable teacher supervision within an adaptive trust region. Specifically, Delta Forcing estimates transition consistency from the latent delta between teacher and generator trajectories, and uses it to balance teacher supervision with a monotonic continuity objective. This suppress unreliable teacher-induced shifts while preserving responsiveness to new events. Extensive experiments demonstrate that Delta Forcing significantly improves consistency while maintaining event reactivity.
Progressive Residual Warmup for Language Model Pretraining
Mar 05, 2026Transformer architectures serve as the backbone for most modern Large Language Models, therefore their pretraining stability and convergence speed are of central concern. Motivated by the logical dependency of sequentially stacked layers, we propose Progressive Residual Warmup (ProRes) for language model pretraining. ProRes implements an "early layer learns first" philosophy by multiplying each layer's residual with a scalar that gradually warms up from 0 to 1, with deeper layers taking longer warmup steps. In this way, deeper layers wait for early layers to settle into a more stable regime before contributing to learning. We demonstrate the effectiveness of ProRes through pretraining experiments across various model scales, as well as normalization and initialization schemes. Comprehensive analysis shows that ProRes not only stabilizes pretraining but also introduces a unique optimization trajectory, leading to faster convergence, stronger generalization and better downstream performance. Our code is available at https://github.com/dandingsky/ProRes.
Composition-RL: Compose Your Verifiable Prompts for Reinforcement Learning of Large Language Models
Feb 12, 2026Large-scale verifiable prompts underpin the success of Reinforcement Learning with Verifiable Rewards (RLVR), but they contain many uninformative examples and are costly to expand further. Recent studies focus on better exploiting limited training data by prioritizing hard prompts whose rollout pass rate is 0. However, easy prompts with a pass rate of 1 also become increasingly prevalent as training progresses, thereby reducing the effective data size. To mitigate this, we propose Composition-RL, a simple yet useful approach for better utilizing limited verifiable prompts targeting pass-rate-1 prompts. More specifically, Composition-RL automatically composes multiple problems into a new verifiable question and uses these compositional prompts for RL training. Extensive experiments across model sizes from 4B to 30B show that Composition-RL consistently improves reasoning capability over RL trained on the original dataset. Performance can be further boosted with a curriculum variant of Composition-RL that gradually increases compositional depth over training. Additionally, Composition-RL enables more effective cross-domain RL by composing prompts drawn from different domains. Codes, datasets, and models are available at https://github.com/XinXU-USTC/Composition-RL.
Teaching LLMs According to Their Aptitude: Adaptive Reasoning for Mathematical Problem Solving
Feb 17, 2025



Existing approaches to mathematical reasoning with large language models (LLMs) rely on Chain-of-Thought (CoT) for generalizability or Tool-Integrated Reasoning (TIR) for precise computation. While efforts have been made to combine these methods, they primarily rely on post-selection or predefined strategies, leaving an open question: whether LLMs can autonomously adapt their reasoning strategy based on their inherent capabilities. In this work, we propose TATA (Teaching LLMs According to Their Aptitude), an adaptive framework that enables LLMs to personalize their reasoning strategy spontaneously, aligning it with their intrinsic aptitude. TATA incorporates base-LLM-aware data selection during supervised fine-tuning (SFT) to tailor training data to the model's unique abilities. This approach equips LLMs to autonomously determine and apply the appropriate reasoning strategy at test time. We evaluate TATA through extensive experiments on six mathematical reasoning benchmarks, using both general-purpose and math-specialized LLMs. Empirical results demonstrate that TATA effectively combines the complementary strengths of CoT and TIR, achieving superior or comparable performance with improved inference efficiency compared to TIR alone. Further analysis underscores the critical role of aptitude-aware data selection in enabling LLMs to make effective and adaptive reasoning decisions and align reasoning strategies with model capabilities.
UGMathBench: A Diverse and Dynamic Benchmark for Undergraduate-Level Mathematical Reasoning with Large Language Models
Jan 23, 2025Large Language Models (LLMs) have made significant strides in mathematical reasoning, underscoring the need for a comprehensive and fair evaluation of their capabilities. However, existing benchmarks often fall short, either lacking extensive coverage of undergraduate-level mathematical problems or probably suffering from test-set contamination. To address these issues, we introduce UGMathBench, a diverse and dynamic benchmark specifically designed for evaluating undergraduate-level mathematical reasoning with LLMs. UGMathBench comprises 5,062 problems across 16 subjects and 111 topics, featuring 10 distinct answer types. Each problem includes three randomized versions, with additional versions planned for release as leading open-source LLMs become saturated in UGMathBench. Furthermore, we propose two key metrics: effective accuracy (EAcc), which measures the percentage of correctly solved problems across all three versions, and reasoning gap ($\Delta$), which assesses reasoning robustness by calculating the difference between the average accuracy across all versions and EAcc. Our extensive evaluation of 23 leading LLMs reveals that the highest EAcc achieved is 56.3\% by OpenAI-o1-mini, with large $\Delta$ values observed across different models. This highlights the need for future research aimed at developing "large reasoning models" with high EAcc and $\Delta = 0$. We anticipate that the release of UGMathBench, along with its detailed evaluation codes, will serve as a valuable resource to advance the development of LLMs in solving mathematical problems.
* Accepted to ICLR 2025
Category-Theoretical and Topos-Theoretical Frameworks in Machine Learning: A Survey
Aug 26, 2024In this survey, we provide an overview of category theory-derived machine learning from four mainstream perspectives: gradient-based learning, probability-based learning, invariance and equivalence-based learning, and topos-based learning. For the first three topics, we primarily review research in the past five years, updating and expanding on the previous survey by Shiebler et al.. The fourth topic, which delves into higher category theory, particularly topos theory, is surveyed for the first time in this paper. In certain machine learning methods, the compositionality of functors plays a vital role, prompting the development of specific categorical frameworks. However, when considering how the global properties of a network reflect in local structures and how geometric properties are expressed with logic, the topos structure becomes particularly significant and profound.
Unifying Sequences, Structures, and Descriptions for Any-to-Any Protein Generation with the Large Multimodal Model HelixProtX
Jul 12, 2024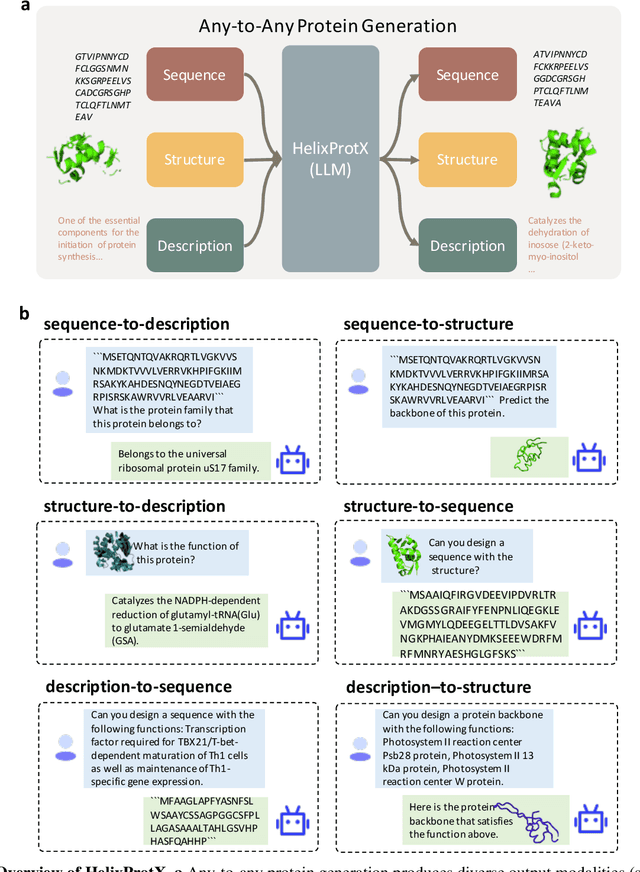
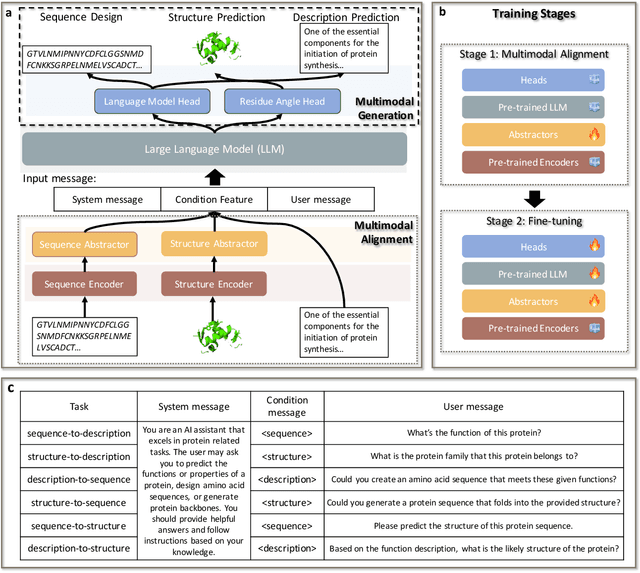
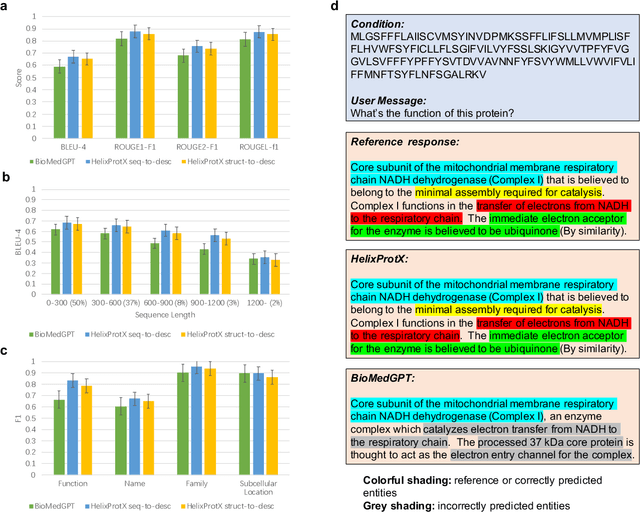
Proteins are fundamental components of biological systems and can be represented through various modalities, including sequences, structures, and textual descriptions. Despite the advances in deep learning and scientific large language models (LLMs) for protein research, current methodologies predominantly focus on limited specialized tasks -- often predicting one protein modality from another. These approaches restrict the understanding and generation of multimodal protein data. In contrast, large multimodal models have demonstrated potential capabilities in generating any-to-any content like text, images, and videos, thus enriching user interactions across various domains. Integrating these multimodal model technologies into protein research offers significant promise by potentially transforming how proteins are studied. To this end, we introduce HelixProtX, a system built upon the large multimodal model, aiming to offer a comprehensive solution to protein research by supporting any-to-any protein modality generation. Unlike existing methods, it allows for the transformation of any input protein modality into any desired protein modality. The experimental results affirm the advanced capabilities of HelixProtX, not only in generating functional descriptions from amino acid sequences but also in executing critical tasks such as designing protein sequences and structures from textual descriptions. Preliminary findings indicate that HelixProtX consistently achieves superior accuracy across a range of protein-related tasks, outperforming existing state-of-the-art models. By integrating multimodal large models into protein research, HelixProtX opens new avenues for understanding protein biology, thereby promising to accelerate scientific discovery.
Multi-Agent Generative Adversarial Interactive Self-Imitation Learning for AUV Formation Control and Obstacle Avoidance
Jan 21, 2024Multiple autonomous underwater vehicles (multi-AUV) can cooperatively accomplish tasks that a single AUV cannot complete. Recently, multi-agent reinforcement learning has been introduced to control of multi-AUV. However, designing efficient reward functions for various tasks of multi-AUV control is difficult or even impractical. Multi-agent generative adversarial imitation learning (MAGAIL) allows multi-AUV to learn from expert demonstration instead of pre-defined reward functions, but suffers from the deficiency of requiring optimal demonstrations and not surpassing provided expert demonstrations. This paper builds upon the MAGAIL algorithm by proposing multi-agent generative adversarial interactive self-imitation learning (MAGAISIL), which can facilitate AUVs to learn policies by gradually replacing the provided sub-optimal demonstrations with self-generated good trajectories selected by a human trainer. Our experimental results in a multi-AUV formation control and obstacle avoidance task on the Gazebo platform with AUV simulator of our lab show that AUVs trained via MAGAISIL can surpass the provided sub-optimal expert demonstrations and reach a performance close to or even better than MAGAIL with optimal demonstrations. Further results indicate that AUVs' policies trained via MAGAISIL can adapt to complex and different tasks as well as MAGAIL learning from optimal demonstrations.