 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDesign of an In-Pipe Robot with Contact-Angle-Guided Kinematic Decoupling for Crosstalk-Suppressed Locomotion
Mar 28, 2026In-pipe inspection robots must traverse confined pipeline networks with elbows and three-dimensional fittings, requiring both reliable axial traction and rapid rolling reorientation for posture correction. In compact V-shaped platforms, these functions often rely on shared contacts or indirect actuation, which introduces strong kinematic coupling and makes performance sensitive to geometry and friction variations. This paper presents a V-shaped in-pipe robot with a joint-axis-and-wheel-separation layout that provides two physically independent actuation channels, with all-wheel-drive propulsion and motorized rolling reorientation while using only two motors. To make the decoupling mechanism explicit and designable, we formulate an actuation transmission matrix and identify the spherical-wheel contact angle as the key geometric variable governing the dominant roll-to-propulsion leakage and roll-channel efficiency. A geometric transmission analysis maps mounting parameters to the contact angle, leakage, and efficiency, yielding a structural guideline for suppressing crosstalk by driving the contact angle toward zero. A static stability model further provides a stability-domain map for selecting torsion-spring stiffness under friction uncertainty to ensure vertical-pipe stability with a margin. Experiments validate the decoupling effect, where during high-dynamic rolling in a vertical pipe, the propulsion torque remains nearly invariant. On a multi-material testbed including out-of-plane double elbows, the robot achieved a 100% success rate in more than 10 independent round-trip trials.
ExoGait-MS: Learning Periodic Dynamics with Multi-Scale Graph Network for Exoskeleton Gait Recognition
May 23, 2025
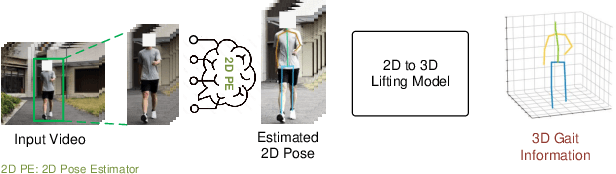


Current exoskeleton control methods often face challenges in delivering personalized treatment. Standardized walking gaits can lead to patient discomfort or even injury. Therefore, personalized gait is essential for the effectiveness of exoskeleton robots, as it directly impacts their adaptability, comfort, and rehabilitation outcomes for individual users. To enable personalized treatment in exoskeleton-assisted therapy and related applications, accurate recognition of personal gait is crucial for implementing tailored gait control. The key challenge in gait recognition lies in effectively capturing individual differences in subtle gait features caused by joint synergy, such as step frequency and step length. To tackle this issue, we propose a novel approach, which uses Multi-Scale Global Dense Graph Convolutional Networks (GCN) in the spatial domain to identify latent joint synergy patterns. Moreover, we propose a Gait Non-linear Periodic Dynamics Learning module to effectively capture the periodic characteristics of gait in the temporal domain. To support our individual gait recognition task, we have constructed a comprehensive gait dataset that ensures both completeness and reliability. Our experimental results demonstrate that our method achieves an impressive accuracy of 94.34% on this dataset, surpassing the current state-of-the-art (SOTA) by 3.77%. This advancement underscores the potential of our approach to enhance personalized gait control in exoskeleton-assisted therapy.
A High-frequency Pneumatic Oscillator for Soft Robotics
Nov 12, 2024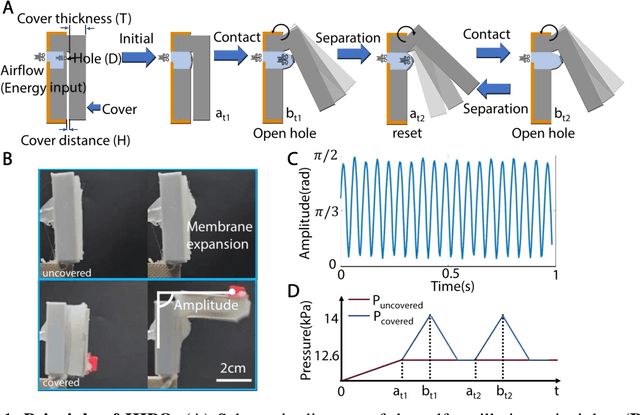
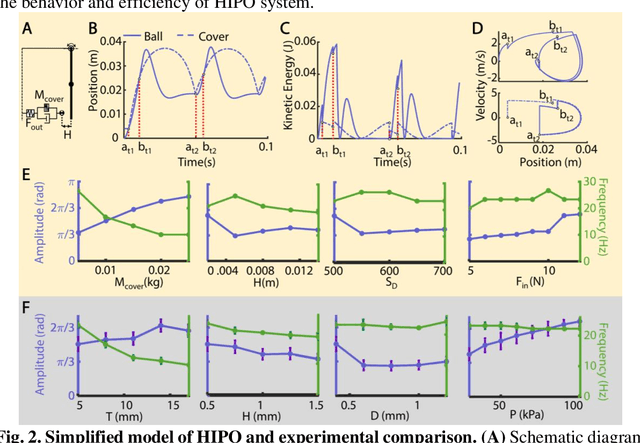
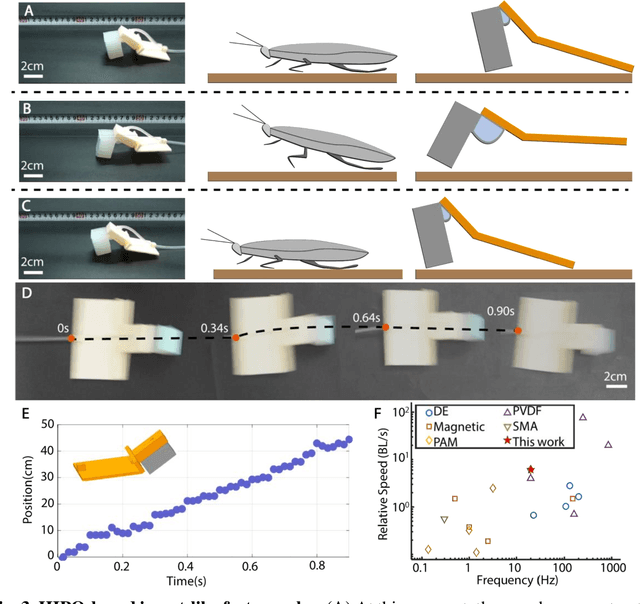
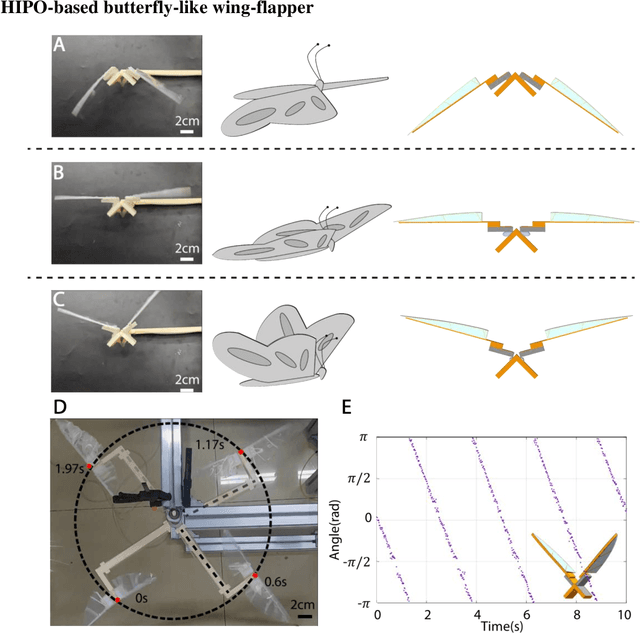
Soft robots, while highly adaptable to diverse environments through various actuation methods, still face significant performance boundary due to the inherent properties of materials. These limitations manifest in the challenge of guaranteeing rapid response and large-scale movements simultaneously, ultimately restricting the robots' absolute speed and overall efficiency. In this paper, we introduce a high-frequency pneumatic oscillator (HIPO) to overcome these challenges. Through a collision-induced phase resetting mechanism, our HIPO leverages event-based nonlinearity to trigger self-oscillation of pneumatic actuator, which positively utilizes intrinsic characteristics of materials. This enables the system to spontaneously generate periodic control signals and directly produce motion responses, eliminating the need for incorporating external actuation components. By efficiently and rapidly converting internal energy of airflow into the kinetic energy of robots, HIPO achieves a frequency of up to 20 Hz. Furthermore, we demonstrate the versatility and high-performance capabilities of HIPO through bio-inspired robots: an insect-like fast-crawler (with speeds up to 50.27 cm/s), a high-frequency butterfly-like wing-flapper, and a maneuverable duck-like swimmer. By eliminating external components and seamlessly fusing signal generation, energy conversion, and motion output, HIPO unleashes rapid and efficient motion, unlocking potential for high-performance soft robotics.
Incremental Reinforcement Learning --- a New Continuous Reinforcement Learning Frame Based on Stochastic Differential Equation methods
Aug 08, 2019
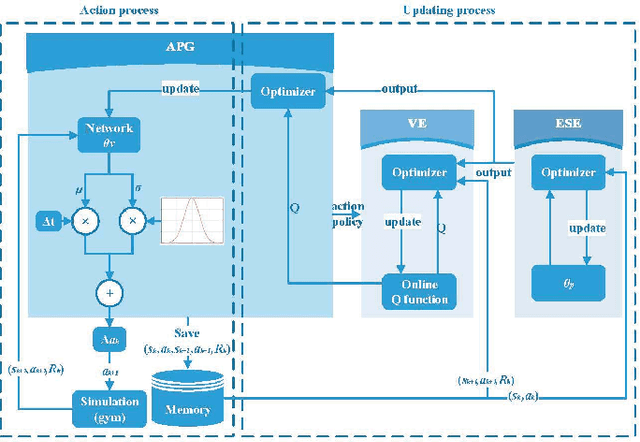
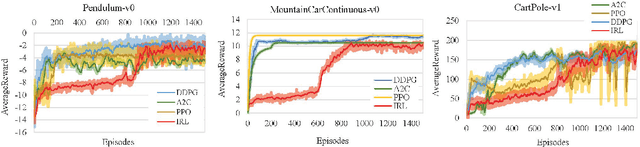
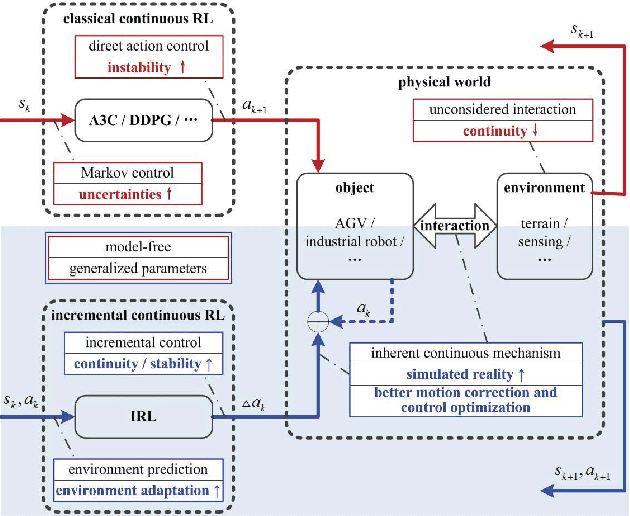
Continuous reinforcement learning such as DDPG and A3C are widely used in robot control and autonomous driving. However, both methods have theoretical weaknesses. While DDPG cannot control noises in the control process, A3C does not satisfy the continuity conditions under the Gaussian policy. To address these concerns, we propose a new continues reinforcement learning method based on stochastic differential equations and we call it Incremental Reinforcement Learning (IRL). This method not only guarantees the continuity of actions within any time interval, but controls the variance of actions in the training process. In addition, our method does not assume Markov control in agents' action control and allows agents to predict scene changes for action selection. With our method, agents no longer passively adapt to the environment. Instead, they positively interact with the environment for maximum rewards.