 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVFACamou: View-Fused Adversarial Camouflage for Environment-Adaptive Physical Evasion
Jun 18, 2026Adversarial camouflage in the physical world remains highly challenging, particularly under UAV reconnaissance where targets undergo continuous geometric changes and extreme illumination variations. Existing methods either optimize 2D digital perturbations that fail to generalize to dynamic viewpoints or produce visually unnatural textures that cannot be deployed in real scenarios. Therefore, we propose an end-to-end framework for adversarial camouflage generation that automatically produces wearable adversarial patterns and maintains stable attack performance in real physical environments with changing viewpoints, poses, and lighting conditions. Our method integrates UV-volume rendering with a diffusion-based texture generator, enabling consistent appearance under varying scales, poses, and lighting conditions. To ensure environmental realism, we propose an illumination color consistency estimator that extracts dominant background attributes and guides a natural texture loss to align the generated UV texture with the surrounding environment. A multi-scale dynamic training strategy further enhances robustness against viewpoint shifts and body deformation. Extensive experiments across multiple mainstream detectors demonstrate that our method achieves strong and stable physical attack performance while maintaining high perceptual naturalness, reducing human detection rates without introducing unnatural artifacts.
Kwai Keye-VL-2.0 Technical Report
Jun 09, 2026We introduce Kwai Keye-VL-2.0-30B-A3B, an open-source Mixture-of-Experts (MoE) multimodal foundation model designed to advance long-video understanding and agentic intelligence. To address the challenges of ultra-long contexts, information redundancy, and prohibitive computational costs inherent in hour-level videos, Keye-VL-2.0 is the first to adapt DeepSeek Sparse Attention (DSA) to GQA-based multimodal architectures, enabling lossless 256K context processing while capturing critical frames and long-range temporal dependencies. This architecture is underpinned by a highly optimized training and inference infrastructure, including scalable video I/O, heterogeneous ViT-LM parallelism, and custom DSA kernels that significantly maximize throughput and minimize computational overhead. Furthermore, to overcome the algorithmic dilemma of catastrophic forgetting during multi-task alignment, we introduce Cross-Modal Multi-Teacher On-Policy Distillation (MOPD) paired with Context-RL and Video-RL. By distilling dense token-level teacher feedback from on-policy rollouts back into the MoE backbone, which activates only 3B parameters, Keye-VL-2.0 natively empowers advanced agent collaboration across Code, Tool, and Search scenarios with multimodal self-correction. Extensive evaluations across video understanding, temporal grounding, reasoning, STEM, and agent benchmarks demonstrate that Keye-VL-2.0-30B-A3B achieves state-of-the-art performance among models of similar scale, particularly excelling in fine-grained temporal localization on TimeLens and long-video comprehension on Video-MME-v2 and LongVideoBench. We release our model checkpoints to accelerate community progress toward scalable and robust multimodal agentic applications.
EmbryoDiff: A Conditional Diffusion Framework with Multi-Focal Feature Fusion for Fine-Grained Embryo Developmental Stage Recognition
Nov 14, 2025Identification of fine-grained embryo developmental stages during In Vitro Fertilization (IVF) is crucial for assessing embryo viability. Although recent deep learning methods have achieved promising accuracy, existing discriminative models fail to utilize the distributional prior of embryonic development to improve accuracy. Moreover, their reliance on single-focal information leads to incomplete embryonic representations, making them susceptible to feature ambiguity under cell occlusions. To address these limitations, we propose EmbryoDiff, a two-stage diffusion-based framework that formulates the task as a conditional sequence denoising process. Specifically, we first train and freeze a frame-level encoder to extract robust multi-focal features. In the second stage, we introduce a Multi-Focal Feature Fusion Strategy that aggregates information across focal planes to construct a 3D-aware morphological representation, effectively alleviating ambiguities arising from cell occlusions. Building on this fused representation, we derive complementary semantic and boundary cues and design a Hybrid Semantic-Boundary Condition Block to inject them into the diffusion-based denoising process, enabling accurate embryonic stage classification. Extensive experiments on two benchmark datasets show that our method achieves state-of-the-art results. Notably, with only a single denoising step, our model obtains the best average test performance, reaching 82.8% and 81.3% accuracy on the two datasets, respectively.
Towards Real-World Deepfake Detection: A Diverse In-the-wild Dataset of Forgery Faces
Oct 09, 2025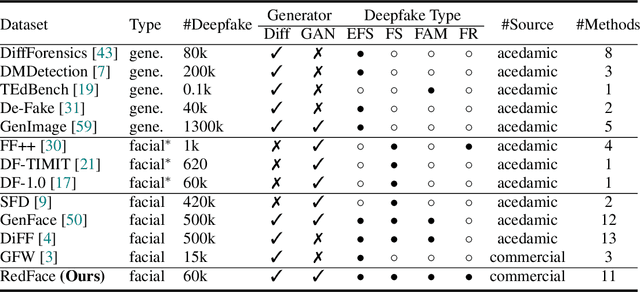


Deepfakes, leveraging advanced AIGC (Artificial Intelligence-Generated Content) techniques, create hyper-realistic synthetic images and videos of human faces, posing a significant threat to the authenticity of social media. While this real-world threat is increasingly prevalent, existing academic evaluations and benchmarks for detecting deepfake forgery often fall short to achieve effective application for their lack of specificity, limited deepfake diversity, restricted manipulation techniques.To address these limitations, we introduce RedFace (Real-world-oriented Deepfake Face), a specialized facial deepfake dataset, comprising over 60,000 forged images and 1,000 manipulated videos derived from authentic facial features, to bridge the gap between academic evaluations and real-world necessity. Unlike prior benchmarks, which typically rely on academic methods to generate deepfakes, RedFace utilizes 9 commercial online platforms to integrate the latest deepfake technologies found "in the wild", effectively simulating real-world black-box scenarios.Moreover, RedFace's deepfakes are synthesized using bespoke algorithms, allowing it to capture diverse and evolving methods used by real-world deepfake creators. Extensive experimental results on RedFace (including cross-domain, intra-domain, and real-world social network dissemination simulations) verify the limited practicality of existing deepfake detection schemes against real-world applications. We further perform a detailed analysis of the RedFace dataset, elucidating the reason of its impact on detection performance compared to conventional datasets. Our dataset is available at: https://github.com/kikyou-220/RedFace.
Time-Lapse Video-Based Embryo Grading via Complementary Spatial-Temporal Pattern Mining
Jun 05, 2025Artificial intelligence has recently shown promise in automated embryo selection for In-Vitro Fertilization (IVF). However, current approaches either address partial embryo evaluation lacking holistic quality assessment or target clinical outcomes inevitably confounded by extra-embryonic factors, both limiting clinical utility. To bridge this gap, we propose a new task called Video-Based Embryo Grading - the first paradigm that directly utilizes full-length time-lapse monitoring (TLM) videos to predict embryologists' overall quality assessments. To support this task, we curate a real-world clinical dataset comprising over 2,500 TLM videos, each annotated with a grading label indicating the overall quality of embryos. Grounded in clinical decision-making principles, we propose a Complementary Spatial-Temporal Pattern Mining (CoSTeM) framework that conceptually replicates embryologists' evaluation process. The CoSTeM comprises two branches: (1) a morphological branch using a Mixture of Cross-Attentive Experts layer and a Temporal Selection Block to select discriminative local structural features, and (2) a morphokinetic branch employing a Temporal Transformer to model global developmental trajectories, synergistically integrating static and dynamic determinants for grading embryos. Extensive experimental results demonstrate the superiority of our design. This work provides a valuable methodological framework for AI-assisted embryo selection. The dataset and source code will be publicly available upon acceptance.
ExoGait-MS: Learning Periodic Dynamics with Multi-Scale Graph Network for Exoskeleton Gait Recognition
May 23, 2025
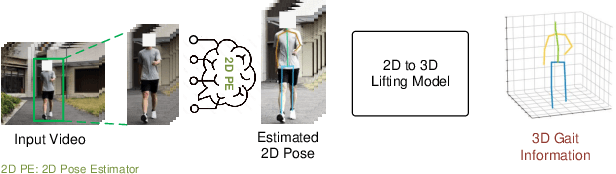


Current exoskeleton control methods often face challenges in delivering personalized treatment. Standardized walking gaits can lead to patient discomfort or even injury. Therefore, personalized gait is essential for the effectiveness of exoskeleton robots, as it directly impacts their adaptability, comfort, and rehabilitation outcomes for individual users. To enable personalized treatment in exoskeleton-assisted therapy and related applications, accurate recognition of personal gait is crucial for implementing tailored gait control. The key challenge in gait recognition lies in effectively capturing individual differences in subtle gait features caused by joint synergy, such as step frequency and step length. To tackle this issue, we propose a novel approach, which uses Multi-Scale Global Dense Graph Convolutional Networks (GCN) in the spatial domain to identify latent joint synergy patterns. Moreover, we propose a Gait Non-linear Periodic Dynamics Learning module to effectively capture the periodic characteristics of gait in the temporal domain. To support our individual gait recognition task, we have constructed a comprehensive gait dataset that ensures both completeness and reliability. Our experimental results demonstrate that our method achieves an impressive accuracy of 94.34% on this dataset, surpassing the current state-of-the-art (SOTA) by 3.77%. This advancement underscores the potential of our approach to enhance personalized gait control in exoskeleton-assisted therapy.
RoboAct-CLIP: Video-Driven Pre-training of Atomic Action Understanding for Robotics
Apr 02, 2025Visual Language Models (VLMs) have emerged as pivotal tools for robotic systems, enabling cross-task generalization, dynamic environmental interaction, and long-horizon planning through multimodal perception and semantic reasoning. However, existing open-source VLMs predominantly trained for generic vision-language alignment tasks fail to model temporally correlated action semantics that are crucial for robotic manipulation effectively. While current image-based fine-tuning methods partially adapt VLMs to robotic applications, they fundamentally disregard temporal evolution patterns in video sequences and suffer from visual feature entanglement between robotic agents, manipulated objects, and environmental contexts, thereby limiting semantic decoupling capability for atomic actions and compromising model generalizability.To overcome these challenges, this work presents RoboAct-CLIP with dual technical contributions: 1) A dataset reconstruction framework that performs semantic-constrained action unit segmentation and re-annotation on open-source robotic videos, constructing purified training sets containing singular atomic actions (e.g., "grasp"); 2) A temporal-decoupling fine-tuning strategy based on Contrastive Language-Image Pretraining (CLIP) architecture, which disentangles temporal action features across video frames from object-centric characteristics to achieve hierarchical representation learning of robotic atomic actions.Experimental results in simulated environments demonstrate that the RoboAct-CLIP pretrained model achieves a 12% higher success rate than baseline VLMs, along with superior generalization in multi-object manipulation tasks.
GenM$^3$: Generative Pretrained Multi-path Motion Model for Text Conditional Human Motion Generation
Mar 19, 2025Scaling up motion datasets is crucial to enhance motion generation capabilities. However, training on large-scale multi-source datasets introduces data heterogeneity challenges due to variations in motion content. To address this, we propose Generative Pretrained Multi-path Motion Model (GenM$^3$), a comprehensive framework designed to learn unified motion representations. GenM$^3$ comprises two components: 1) a Multi-Expert VQ-VAE (MEVQ-VAE) that adapts to different dataset distributions to learn a unified discrete motion representation, and 2) a Multi-path Motion Transformer (MMT) that improves intra-modal representations by using separate modality-specific pathways, each with densely activated experts to accommodate variations within that modality, and improves inter-modal alignment by the text-motion shared pathway. To enable large-scale training, we integrate and unify 11 high-quality motion datasets (approximately 220 hours of motion data) and augment it with textual annotations (nearly 10,000 motion sequences labeled by a large language model and 300+ by human experts). After training on our integrated dataset, GenM$^3$ achieves a state-of-the-art FID of 0.035 on the HumanML3D benchmark, surpassing state-of-the-art methods by a large margin. It also demonstrates strong zero-shot generalization on IDEA400 dataset, highlighting its effectiveness and adaptability across diverse motion scenarios.
Improving Generalization of Universal Adversarial Perturbation via Dynamic Maximin Optimization
Mar 17, 2025Deep neural networks (DNNs) are susceptible to universal adversarial perturbations (UAPs). These perturbations are meticulously designed to fool the target model universally across all sample classes. Unlike instance-specific adversarial examples (AEs), generating UAPs is more complex because they must be generalized across a wide range of data samples and models. Our research reveals that existing universal attack methods, which optimize UAPs using DNNs with static model parameter snapshots, do not fully leverage the potential of DNNs to generate more effective UAPs. Rather than optimizing UAPs against static DNN models with a fixed training set, we suggest using dynamic model-data pairs to generate UAPs. In particular, we introduce a dynamic maximin optimization strategy, aiming to optimize the UAP across a variety of optimal model-data pairs. We term this approach DM-UAP. DM-UAP utilizes an iterative max-min-min optimization framework that refines the model-data pairs, coupled with a curriculum UAP learning algorithm to examine the combined space of model parameters and data thoroughly. Comprehensive experiments on the ImageNet dataset demonstrate that the proposed DM-UAP markedly enhances both cross-sample universality and cross-model transferability of UAPs. Using only 500 samples for UAP generation, DM-UAP outperforms the state-of-the-art approach with an average increase in fooling ratio of 12.108%.
Past Movements-Guided Motion Representation Learning for Human Motion Prediction
Aug 04, 2024Human motion prediction based on 3D skeleton is a significant challenge in computer vision, primarily focusing on the effective representation of motion. In this paper, we propose a self-supervised learning framework designed to enhance motion representation. This framework consists of two stages: first, the network is pretrained through the self-reconstruction of past sequences, and the guided reconstruction of future sequences based on past movements. We design a velocity-based mask strategy to focus on the joints with large-scale moving. Subsequently, the pretrained network undergoes finetuning for specific tasks. Self-reconstruction, guided by patterns of past motion, substantially improves the model's ability to represent the spatiotemporal relationships among joints but also captures the latent relationships between past and future sequences. This capability is crucial for motion prediction tasks that solely depend on historical motion data. By employing this straightforward yet effective training paradigm, our method outperforms existing \textit{state-of-the-art} methods, reducing the average prediction errors by 8.8\% across Human3.6M, 3DPW, and AMASS datasets. The code is available at https://github.com/JunyuShi02/PMG-MRL.