 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Tag is the Signal: URL-Agnostic Credibility Scoring for Messages on Telegram
Jan 19, 2026Telegram has become one of the leading platforms for disseminating misinformational messages. However, many existing pipelines still classify each message's credibility based on the reputation of its associated domain names or its lexical features. Such methods work well on traditional long-form news articles published by well-known sources, but high-risk posts on Telegram are short and URL-sparse, leading to failures for link-based and standard TF-IDF models. To this end, we propose the TAG2CRED pipeline, a method designed for such short, convoluted messages. Our model will directly score each post based on the tags assigned to the text. We designed a concise label system that covers the dimensions of theme, claim type, call to action, and evidence. The fine-tuned large language model (LLM) assigns tags to messages and then maps these tags to calibrated risk scores in the [0,1] interval through L2-regularized logistic regression. We evaluated 87,936 Telegram messages associated with Media Bias/Fact Check (MBFC), using URL masking and domain disjoint splits. The results showed that the ROC-AUC of the TAG2CRED model reached 0.871, the macro-F1 value was 0.787, and the Brier score was 0.167, outperforming the baseline TF-IDF (macro-F1 value 0.737, Brier score 0.248); at the same time, the number of features used in this model is much smaller, and the generalization ability on infrequent domains is stronger. The performance of the stacked ensemble model (TF-IDF + TAG2CRED + SBERT) was further improved over the baseline SBERT. ROC-AUC reached 0.901, and the macro-F1 value was 0.813 (Brier score 0.114). This indicates that style labels and lexical features may capture different but complementary dimensions of information risk.
DynamicRTL: RTL Representation Learning for Dynamic Circuit Behavior
Nov 12, 2025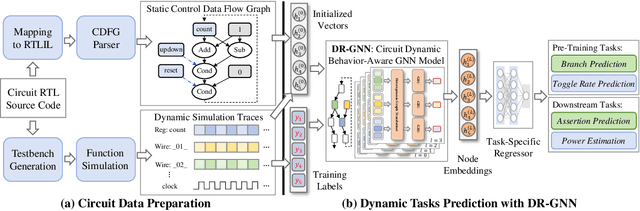

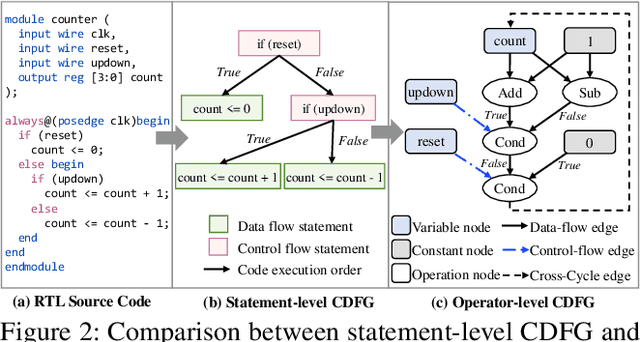

There is a growing body of work on using Graph Neural Networks (GNNs) to learn representations of circuits, focusing primarily on their static characteristics. However, these models fail to capture circuit runtime behavior, which is crucial for tasks like circuit verification and optimization. To address this limitation, we introduce DR-GNN (DynamicRTL-GNN), a novel approach that learns RTL circuit representations by incorporating both static structures and multi-cycle execution behaviors. DR-GNN leverages an operator-level Control Data Flow Graph (CDFG) to represent Register Transfer Level (RTL) circuits, enabling the model to capture dynamic dependencies and runtime execution. To train and evaluate DR-GNN, we build the first comprehensive dynamic circuit dataset, comprising over 6,300 Verilog designs and 63,000 simulation traces. Our results demonstrate that DR-GNN outperforms existing models in branch hit prediction and toggle rate prediction. Furthermore, its learned representations transfer effectively to related dynamic circuit tasks, achieving strong performance in power estimation and assertion prediction.
Time-Lapse Video-Based Embryo Grading via Complementary Spatial-Temporal Pattern Mining
Jun 05, 2025Artificial intelligence has recently shown promise in automated embryo selection for In-Vitro Fertilization (IVF). However, current approaches either address partial embryo evaluation lacking holistic quality assessment or target clinical outcomes inevitably confounded by extra-embryonic factors, both limiting clinical utility. To bridge this gap, we propose a new task called Video-Based Embryo Grading - the first paradigm that directly utilizes full-length time-lapse monitoring (TLM) videos to predict embryologists' overall quality assessments. To support this task, we curate a real-world clinical dataset comprising over 2,500 TLM videos, each annotated with a grading label indicating the overall quality of embryos. Grounded in clinical decision-making principles, we propose a Complementary Spatial-Temporal Pattern Mining (CoSTeM) framework that conceptually replicates embryologists' evaluation process. The CoSTeM comprises two branches: (1) a morphological branch using a Mixture of Cross-Attentive Experts layer and a Temporal Selection Block to select discriminative local structural features, and (2) a morphokinetic branch employing a Temporal Transformer to model global developmental trajectories, synergistically integrating static and dynamic determinants for grading embryos. Extensive experimental results demonstrate the superiority of our design. This work provides a valuable methodological framework for AI-assisted embryo selection. The dataset and source code will be publicly available upon acceptance.
Adaptive LiDAR Odometry and Mapping for Autonomous Agricultural Mobile Robots in Unmanned Farms
Dec 03, 2024Unmanned and intelligent agricultural systems are crucial for enhancing agricultural efficiency and for helping mitigate the effect of labor shortage. However, unlike urban environments, agricultural fields impose distinct and unique challenges on autonomous robotic systems, such as the unstructured and dynamic nature of the environment, the rough and uneven terrain, and the resulting non-smooth robot motion. To address these challenges, this work introduces an adaptive LiDAR odometry and mapping framework tailored for autonomous agricultural mobile robots operating in complex agricultural environments. The proposed framework consists of a robust LiDAR odometry algorithm based on dense Generalized-ICP scan matching, and an adaptive mapping module that considers motion stability and point cloud consistency for selective map updates. The key design principle of this framework is to prioritize the incremental consistency of the map by rejecting motion-distorted points and sparse dynamic objects, which in turn leads to high accuracy in odometry estimated from scan matching against the map. The effectiveness of the proposed method is validated via extensive evaluation against state-of-the-art methods on field datasets collected in real-world agricultural environments featuring various planting types, terrain types, and robot motion profiles. Results demonstrate that our method can achieve accurate odometry estimation and mapping results consistently and robustly across diverse agricultural settings, whereas other methods are sensitive to abrupt robot motion and accumulated drift in unstructured environments. Further, the computational efficiency of our method is competitive compared with other methods. The source code of the developed method and the associated field dataset are publicly available at https://github.com/UCR-Robotics/AG-LOAM.
Planar Reflection-Aware Neural Radiance Fields
Nov 07, 2024Neural Radiance Fields (NeRF) have demonstrated exceptional capabilities in reconstructing complex scenes with high fidelity. However, NeRF's view dependency can only handle low-frequency reflections. It falls short when handling complex planar reflections, often interpreting them as erroneous scene geometries and leading to duplicated and inaccurate scene representations. To address this challenge, we introduce a reflection-aware NeRF that jointly models planar reflectors, such as windows, and explicitly casts reflected rays to capture the source of the high-frequency reflections. We query a single radiance field to render the primary color and the source of the reflection. We propose a sparse edge regularization to help utilize the true sources of reflections for rendering planar reflections rather than creating a duplicate along the primary ray at the same depth. As a result, we obtain accurate scene geometry. Rendering along the primary ray results in a clean, reflection-free view, while explicitly rendering along the reflected ray allows us to reconstruct highly detailed reflections. Our extensive quantitative and qualitative evaluations of real-world datasets demonstrate our method's enhanced performance in accurately handling reflections.
On-the-Go Tree Detection and Geometric Traits Estimation with Ground Mobile Robots in Fruit Tree Groves
Apr 03, 2024



By-tree information gathering is an essential task in precision agriculture achieved by ground mobile sensors, but it can be time- and labor-intensive. In this paper we present an algorithmic framework to perform real-time and on-the-go detection of trees and key geometric characteristics (namely, width and height) with wheeled mobile robots in the field. Our method is based on the fusion of 2D domain-specific data (normalized difference vegetation index [NDVI] acquired via a red-green-near-infrared [RGN] camera) and 3D LiDAR point clouds, via a customized tree landmark association and parameter estimation algorithm. The proposed system features a multi-modal and entropy-based landmark correspondences approach, integrated into an underlying Kalman filter system to recognize the surrounding trees and jointly estimate their spatial and vegetation-based characteristics. Realistic simulated tests are used to evaluate our proposed algorithm's behavior in a variety of settings. Physical experiments in agricultural fields help validate our method's efficacy in acquiring accurate by-tree information on-the-go and in real-time by employing only onboard computational and sensing resources.
Multimodal Dataset for Localization, Mapping and Crop Monitoring in Citrus Tree Farms
Sep 29, 2023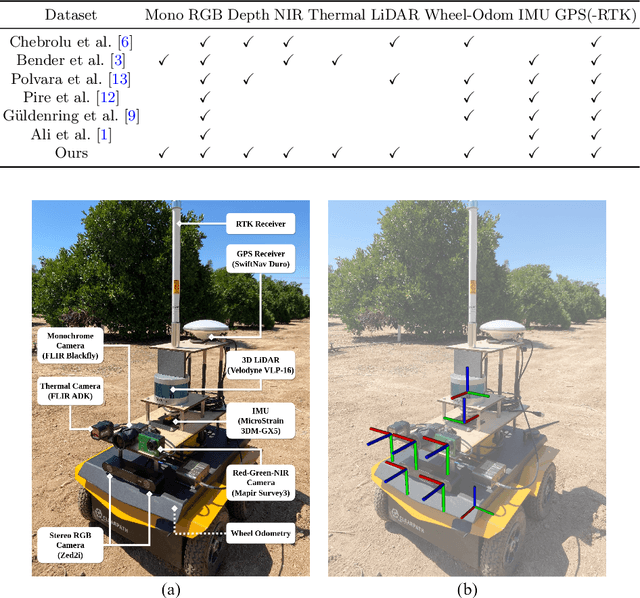
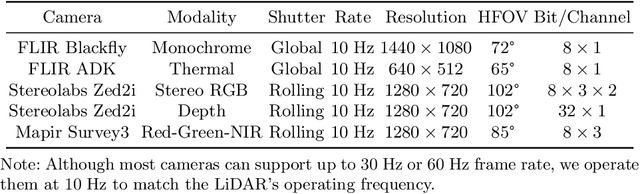

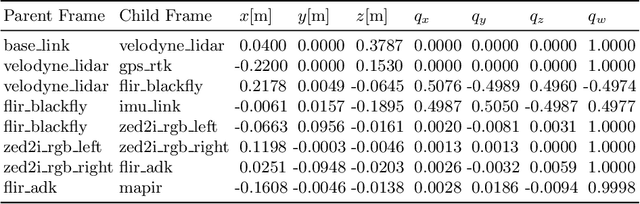
In this work we introduce the CitrusFarm dataset, a comprehensive multimodal sensory dataset collected by a wheeled mobile robot operating in agricultural fields. The dataset offers stereo RGB images with depth information, as well as monochrome, near-infrared and thermal images, presenting diverse spectral responses crucial for agricultural research. Furthermore, it provides a range of navigational sensor data encompassing wheel odometry, LiDAR, inertial measurement unit (IMU), and GNSS with Real-Time Kinematic (RTK) as the centimeter-level positioning ground truth. The dataset comprises seven sequences collected in three fields of citrus trees, featuring various tree species at different growth stages, distinctive planting patterns, as well as varying daylight conditions. It spans a total operation time of 1.7 hours, covers a distance of 7.5 km, and constitutes 1.3 TB of data. We anticipate that this dataset can facilitate the development of autonomous robot systems operating in agricultural tree environments, especially for localization, mapping and crop monitoring tasks. Moreover, the rich sensing modalities offered in this dataset can also support research in a range of robotics and computer vision tasks, such as place recognition, scene understanding, object detection and segmentation, and multimodal learning. The dataset, in conjunction with related tools and resources, is made publicly available at https://github.com/UCR-Robotics/Citrus-Farm-Dataset.
OmnimatteRF: Robust Omnimatte with 3D Background Modeling
Sep 14, 2023
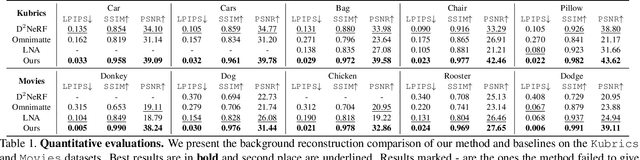


Video matting has broad applications, from adding interesting effects to casually captured movies to assisting video production professionals. Matting with associated effects such as shadows and reflections has also attracted increasing research activity, and methods like Omnimatte have been proposed to separate dynamic foreground objects of interest into their own layers. However, prior works represent video backgrounds as 2D image layers, limiting their capacity to express more complicated scenes, thus hindering application to real-world videos. In this paper, we propose a novel video matting method, OmnimatteRF, that combines dynamic 2D foreground layers and a 3D background model. The 2D layers preserve the details of the subjects, while the 3D background robustly reconstructs scenes in real-world videos. Extensive experiments demonstrate that our method reconstructs scenes with better quality on various videos.
Advances and Challenges of Multi-task Learning Method in Recommender System: A Survey
May 23, 2023



Multi-task learning has been widely applied in computational vision, natural language processing and other fields, which has achieved well performance. In recent years, a lot of work about multi-task learning recommender system has been yielded, but there is no previous literature to summarize these works. To bridge this gap, we provide a systematic literature survey about multi-task recommender systems, aiming to help researchers and practitioners quickly understand the current progress in this direction. In this survey, we first introduce the background and the motivation of the multi-task learning-based recommender systems. Then we provide a taxonomy of multi-task learning-based recommendation methods according to the different stages of multi-task learning techniques, which including task relationship discovery, model architecture and optimization strategy. Finally, we raise discussions on the application and promising future directions in this area.