 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRotated Lights for Consistent and Efficient 2D Gaussians Inverse Rendering
Feb 09, 2026Inverse rendering aims to decompose a scene into its geometry, material properties and light conditions under a certain rendering model. It has wide applications like view synthesis, relighting, and scene editing. In recent years, inverse rendering methods have been inspired by view synthesis approaches like neural radiance fields and Gaussian splatting, which are capable of efficiently decomposing a scene into its geometry and radiance. They then further estimate the material and lighting that lead to the observed scene radiance. However, the latter step is highly ambiguous and prior works suffer from inaccurate color and baked shadows in their albedo estimation albeit their regularization. To this end, we propose RotLight, a simple capturing setup, to address the ambiguity. Compared to a usual capture, RotLight only requires the object to be rotated several times during the process. We show that as few as two rotations is effective in reducing artifacts. To further improve 2DGS-based inverse rendering, we additionally introduce a proxy mesh that not only allows accurate incident light tracing, but also enables a residual constraint and improves global illumination handling. We demonstrate with both synthetic and real world datasets that our method achieves superior albedo estimation while keeping efficient computation.
Weakly Supervised Segmentation Framework for Thyroid Nodule Based on High-confidence Labels and High-rationality Losses
Feb 27, 2025Weakly supervised segmentation methods can delineate thyroid nodules in ultrasound images efficiently using training data with coarse labels, but suffer from: 1) low-confidence pseudo-labels that follow topological priors, introducing significant label noise, and 2) low-rationality loss functions that rigidly compare segmentation with labels, ignoring discriminative information for nodules with diverse and complex shapes. To solve these issues, we clarify the objective and references for weakly supervised ultrasound image segmentation, presenting a framework with high-confidence pseudo-labels to represent topological and anatomical information and high-rationality losses to capture multi-level discriminative features. Specifically, we fuse geometric transformations of four-point annotations and MedSAM model results prompted by specific annotations to generate high-confidence box, foreground, and background labels. Our high-rationality learning strategy includes: 1) Alignment loss measuring spatial consistency between segmentation and box label, and topological continuity within the foreground label, guiding the network to perceive nodule location; 2) Contrastive loss pulling features from labeled foreground regions while pushing features from labeled foreground and background regions, guiding the network to learn nodule and background feature distribution; 3) Prototype correlation loss measuring consistency between correlation maps derived by comparing features with foreground and background prototypes, refining uncertain regions to accurate nodule edges. Experimental results show that our method achieves state-of-the-art performance on the TN3K and DDTI datasets. The code is available at https://github.com/bluehenglee/MLI-MSC.
Speedy-Splat: Fast 3D Gaussian Splatting with Sparse Pixels and Sparse Primitives
Nov 30, 20243D Gaussian Splatting (3D-GS) is a recent 3D scene reconstruction technique that enables real-time rendering of novel views by modeling scenes as parametric point clouds of differentiable 3D Gaussians. However, its rendering speed and model size still present bottlenecks, especially in resource-constrained settings. In this paper, we identify and address two key inefficiencies in 3D-GS, achieving substantial improvements in rendering speed, model size, and training time. First, we optimize the rendering pipeline to precisely localize Gaussians in the scene, boosting rendering speed without altering visual fidelity. Second, we introduce a novel pruning technique and integrate it into the training pipeline, significantly reducing model size and training time while further raising rendering speed. Our Speedy-Splat approach combines these techniques to accelerate average rendering speed by a drastic $6.71\times$ across scenes from the Mip-NeRF 360, Tanks & Temples, and Deep Blending datasets with $10.6\times$ fewer primitives than 3D-GS.
GaNI: Global and Near Field Illumination Aware Neural Inverse Rendering
Mar 22, 2024



In this paper, we present GaNI, a Global and Near-field Illumination-aware neural inverse rendering technique that can reconstruct geometry, albedo, and roughness parameters from images of a scene captured with co-located light and camera. Existing inverse rendering techniques with co-located light-camera focus on single objects only, without modeling global illumination and near-field lighting more prominent in scenes with multiple objects. We introduce a system that solves this problem in two stages; we first reconstruct the geometry powered by neural volumetric rendering NeuS, followed by inverse neural radiosity that uses the previously predicted geometry to estimate albedo and roughness. However, such a naive combination fails and we propose multiple technical contributions that enable this two-stage approach. We observe that NeuS fails to handle near-field illumination and strong specular reflections from the flashlight in a scene. We propose to implicitly model the effects of near-field illumination and introduce a surface angle loss function to handle specular reflections. Similarly, we observe that invNeRad assumes constant illumination throughout the capture and cannot handle moving flashlights during capture. We propose a light position-aware radiance cache network and additional smoothness priors on roughness to reconstruct reflectance. Experimental evaluation on synthetic and real data shows that our method outperforms the existing co-located light-camera-based inverse rendering techniques. Our approach produces significantly better reflectance and slightly better geometry than capture strategies that do not require a dark room.
OmnimatteRF: Robust Omnimatte with 3D Background Modeling
Sep 14, 2023
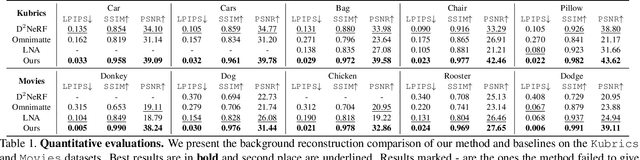


Video matting has broad applications, from adding interesting effects to casually captured movies to assisting video production professionals. Matting with associated effects such as shadows and reflections has also attracted increasing research activity, and methods like Omnimatte have been proposed to separate dynamic foreground objects of interest into their own layers. However, prior works represent video backgrounds as 2D image layers, limiting their capacity to express more complicated scenes, thus hindering application to real-world videos. In this paper, we propose a novel video matting method, OmnimatteRF, that combines dynamic 2D foreground layers and a 3D background model. The 2D layers preserve the details of the subjects, while the 3D background robustly reconstructs scenes in real-world videos. Extensive experiments demonstrate that our method reconstructs scenes with better quality on various videos.
Inverse Global Illumination using a Neural Radiometric Prior
May 03, 2023Inverse rendering methods that account for global illumination are becoming more popular, but current methods require evaluating and automatically differentiating millions of path integrals by tracing multiple light bounces, which remains expensive and prone to noise. Instead, this paper proposes a radiometric prior as a simple alternative to building complete path integrals in a traditional differentiable path tracer, while still correctly accounting for global illumination. Inspired by the Neural Radiosity technique, we use a neural network as a radiance function, and we introduce a prior consisting of the norm of the residual of the rendering equation in the inverse rendering loss. We train our radiance network and optimize scene parameters simultaneously using a loss consisting of both a photometric term between renderings and the multi-view input images, and our radiometric prior (the residual term). This residual term enforces a physical constraint on the optimization that ensures that the radiance field accounts for global illumination. We compare our method to a vanilla differentiable path tracer, and more advanced techniques such as Path Replay Backpropagation. Despite the simplicity of our approach, we can recover scene parameters with comparable and in some cases better quality, at considerably lower computation times.
Learning Generative Models using Denoising Density Estimators
Jan 08, 2020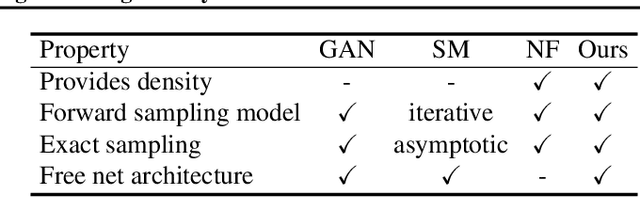
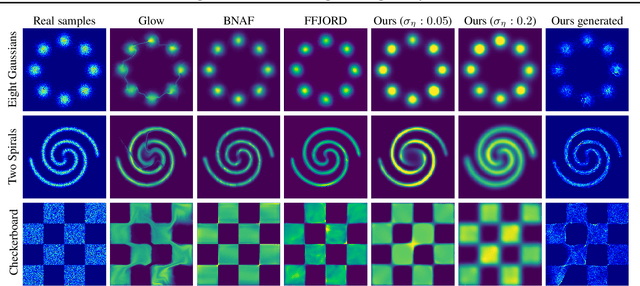

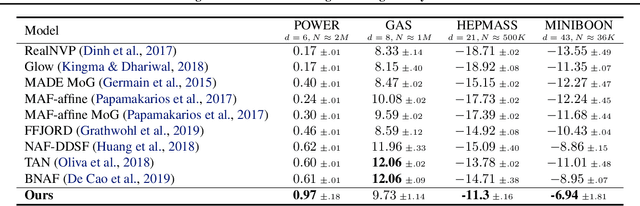
Learning generative probabilistic models that can estimate the continuous density given a set of samples, and that can sample from that density, is one of the fundamental challenges in unsupervised machine learning. In this paper we introduce a new approach to obtain such models based on what we call denoising density estimators (DDEs). A DDE is a scalar function, parameterized by a neural network, that is efficiently trained to represent a kernel density estimator of the data. Leveraging DDEs, our main contribution is to develop a novel approach to obtain generative models that sample from given densities. We prove that our algorithms to obtain both DDEs and generative models are guaranteed to converge to the correct solutions. Advantages of our approach include that we do not require specific network architectures like in normalizing flows, ordinary differential equation solvers as in continuous normalizing flows, nor do we require adversarial training as in generative adversarial networks (GANs). Finally, we provide experimental results that demonstrate practical applications of our technique.
Learning to Generate Dense Point Clouds with Textures on Multiple Categories
Dec 22, 2019
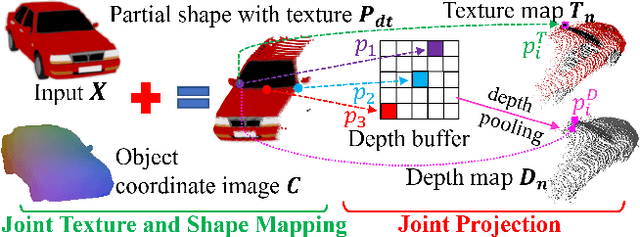

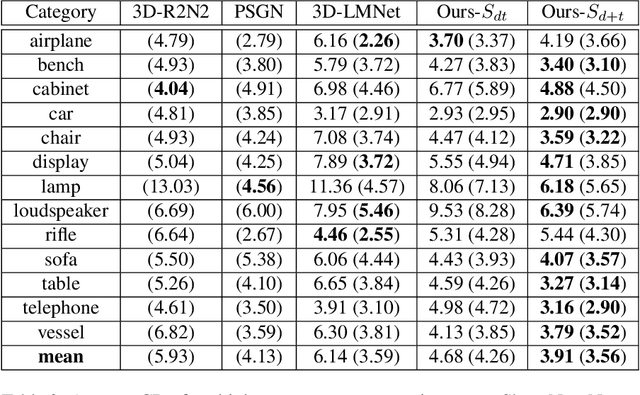
3D reconstruction from images is a core problem in computer vision. With recent advances in deep learning, it has become possible to recover plausible 3D shapes even from single RGB images for the first time. However, obtaining detailed geometry and texture for objects with arbitrary topology remains challenging. In this paper, we propose a novel approach for reconstructing point clouds from RGB images. Unlike other methods, we can recover dense point clouds with hundreds of thousands of points, and we also include RGB textures. In addition, we train our model on multiple categories which leads to superior generalization to unseen categories compared to previous techniques. We achieve this using a two-stage approach, where we first infer an object coordinate map from the input RGB image, and then obtain the final point cloud using a reprojection and completion step. We show results on standard benchmarks that demonstrate the advantages of our technique. Code is available at https://github.com/TaoHuUMD/3D-Reconstruction.