 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTextured Gaussians for Enhanced 3D Scene Appearance Modeling
Nov 27, 2024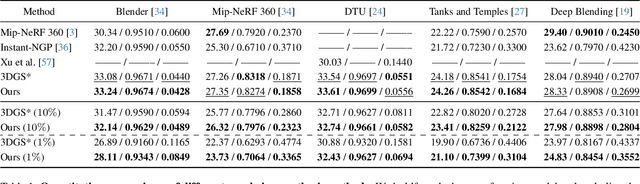
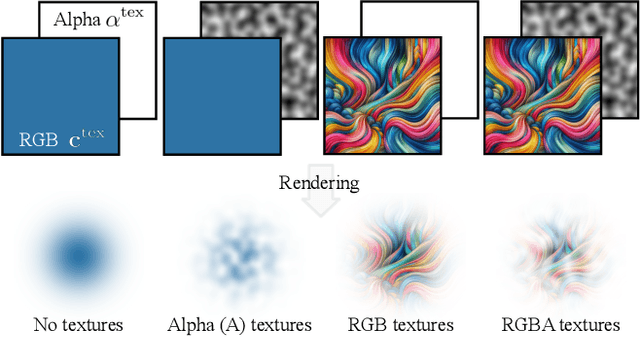

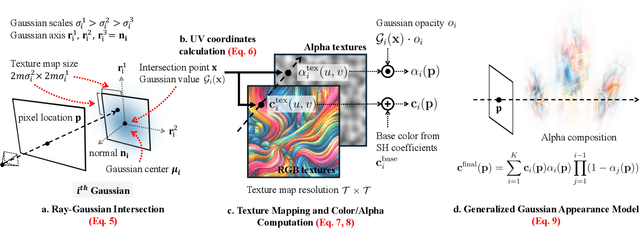
3D Gaussian Splatting (3DGS) has recently emerged as a state-of-the-art 3D reconstruction and rendering technique due to its high-quality results and fast training and rendering time. However, pixels covered by the same Gaussian are always shaded in the same color up to a Gaussian falloff scaling factor. Furthermore, the finest geometric detail any individual Gaussian can represent is a simple ellipsoid. These properties of 3DGS greatly limit the expressivity of individual Gaussian primitives. To address these issues, we draw inspiration from texture and alpha mapping in traditional graphics and integrate it with 3DGS. Specifically, we propose a new generalized Gaussian appearance representation that augments each Gaussian with alpha~(A), RGB, or RGBA texture maps to model spatially varying color and opacity across the extent of each Gaussian. As such, each Gaussian can represent a richer set of texture patterns and geometric structures, instead of just a single color and ellipsoid as in naive Gaussian Splatting. Surprisingly, we found that the expressivity of Gaussians can be greatly improved by using alpha-only texture maps, and further augmenting Gaussians with RGB texture maps achieves the highest expressivity. We validate our method on a wide variety of standard benchmark datasets and our own custom captures at both the object and scene levels. We demonstrate image quality improvements over existing methods while using a similar or lower number of Gaussians.
OmnimatteRF: Robust Omnimatte with 3D Background Modeling
Sep 14, 2023
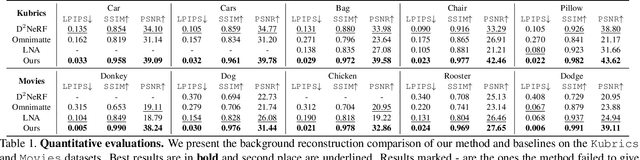


Video matting has broad applications, from adding interesting effects to casually captured movies to assisting video production professionals. Matting with associated effects such as shadows and reflections has also attracted increasing research activity, and methods like Omnimatte have been proposed to separate dynamic foreground objects of interest into their own layers. However, prior works represent video backgrounds as 2D image layers, limiting their capacity to express more complicated scenes, thus hindering application to real-world videos. In this paper, we propose a novel video matting method, OmnimatteRF, that combines dynamic 2D foreground layers and a 3D background model. The 2D layers preserve the details of the subjects, while the 3D background robustly reconstructs scenes in real-world videos. Extensive experiments demonstrate that our method reconstructs scenes with better quality on various videos.
Robust Dynamic Radiance Fields
Jan 05, 2023



Dynamic radiance field reconstruction methods aim to model the time-varying structure and appearance of a dynamic scene. Existing methods, however, assume that accurate camera poses can be reliably estimated by Structure from Motion (SfM) algorithms. These methods, thus, are unreliable as SfM algorithms often fail or produce erroneous poses on challenging videos with highly dynamic objects, poorly textured surfaces, and rotating camera motion. We address this robustness issue by jointly estimating the static and dynamic radiance fields along with the camera parameters (poses and focal length). We demonstrate the robustness of our approach via extensive quantitative and qualitative experiments. Our results show favorable performance over the state-of-the-art dynamic view synthesis methods.
AMICO: Amodal Instance Composition
Oct 11, 2022
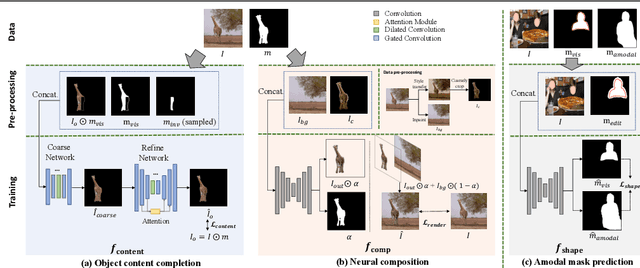


Image composition aims to blend multiple objects to form a harmonized image. Existing approaches often assume precisely segmented and intact objects. Such assumptions, however, are hard to satisfy in unconstrained scenarios. We present Amodal Instance Composition for compositing imperfect -- potentially incomplete and/or coarsely segmented -- objects onto a target image. We first develop object shape prediction and content completion modules to synthesize the amodal contents. We then propose a neural composition model to blend the objects seamlessly. Our primary technical novelty lies in using separate foreground/background representations and blending mask prediction to alleviate segmentation errors. Our results show state-of-the-art performance on public COCOA and KINS benchmarks and attain favorable visual results across diverse scenes. We demonstrate various image composition applications such as object insertion and de-occlusion.
Dynamic View Synthesis from Dynamic Monocular Video
May 13, 2021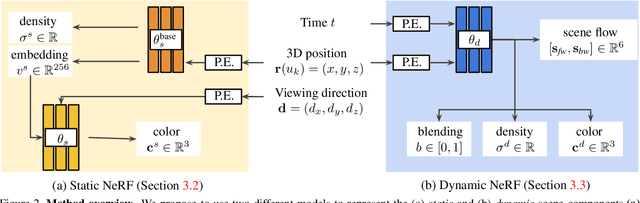
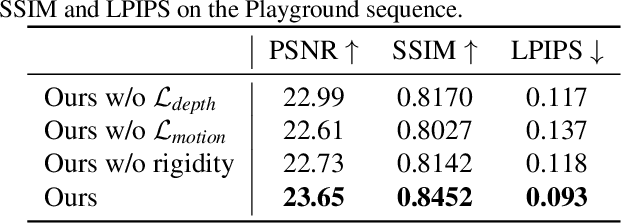


We present an algorithm for generating novel views at arbitrary viewpoints and any input time step given a monocular video of a dynamic scene. Our work builds upon recent advances in neural implicit representation and uses continuous and differentiable functions for modeling the time-varying structure and the appearance of the scene. We jointly train a time-invariant static NeRF and a time-varying dynamic NeRF, and learn how to blend the results in an unsupervised manner. However, learning this implicit function from a single video is highly ill-posed (with infinitely many solutions that match the input video). To resolve the ambiguity, we introduce regularization losses to encourage a more physically plausible solution. We show extensive quantitative and qualitative results of dynamic view synthesis from casually captured videos.
Flow-edge Guided Video Completion
Sep 03, 2020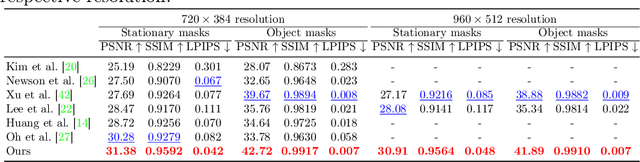
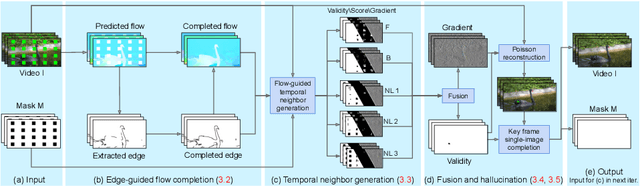
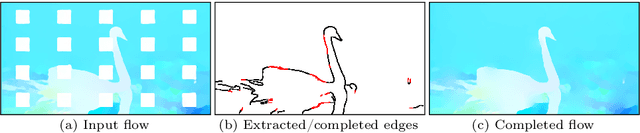

We present a new flow-based video completion algorithm. Previous flow completion methods are often unable to retain the sharpness of motion boundaries. Our method first extracts and completes motion edges, and then uses them to guide piecewise-smooth flow completion with sharp edges. Existing methods propagate colors among local flow connections between adjacent frames. However, not all missing regions in a video can be reached in this way because the motion boundaries form impenetrable barriers. Our method alleviates this problem by introducing non-local flow connections to temporally distant frames, enabling propagating video content over motion boundaries. We validate our approach on the DAVIS dataset. Both visual and quantitative results show that our method compares favorably against the state-of-the-art algorithms.
One Shot 3D Photography
Sep 01, 2020
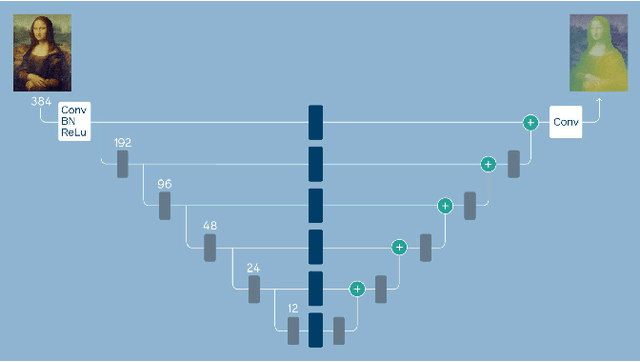

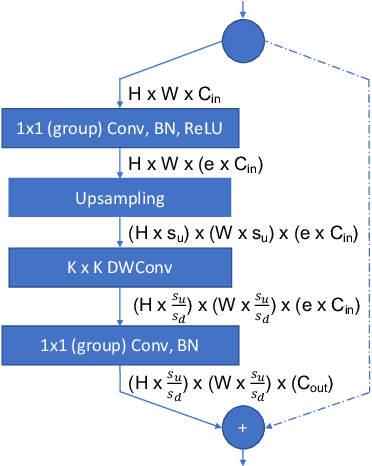
3D photography is a new medium that allows viewers to more fully experience a captured moment. In this work, we refer to a 3D photo as one that displays parallax induced by moving the viewpoint (as opposed to a stereo pair with a fixed viewpoint). 3D photos are static in time, like traditional photos, but are displayed with interactive parallax on mobile or desktop screens, as well as on Virtual Reality devices, where viewing it also includes stereo. We present an end-to-end system for creating and viewing 3D photos, and the algorithmic and design choices therein. Our 3D photos are captured in a single shot and processed directly on a mobile device. The method starts by estimating depth from the 2D input image using a new monocular depth estimation network that is optimized for mobile devices. It performs competitively to the state-of-the-art, but has lower latency and peak memory consumption and uses an order of magnitude fewer parameters. The resulting depth is lifted to a layered depth image, and new geometry is synthesized in parallax regions. We synthesize color texture and structures in the parallax regions as well, using an inpainting network, also optimized for mobile devices, on the LDI directly. Finally, we convert the result into a mesh-based representation that can be efficiently transmitted and rendered even on low-end devices and over poor network connections. Altogether, the processing takes just a few seconds on a mobile device, and the result can be instantly viewed and shared. We perform extensive quantitative evaluation to validate our system and compare its new components against the current state-of-the-art.
* Project page: https://facebookresearch.github.io/one_shot_3d_photography/ Code: https://github.com/facebookresearch/one_shot_3d_photography