 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAMICO: Amodal Instance Composition
Oct 11, 2022
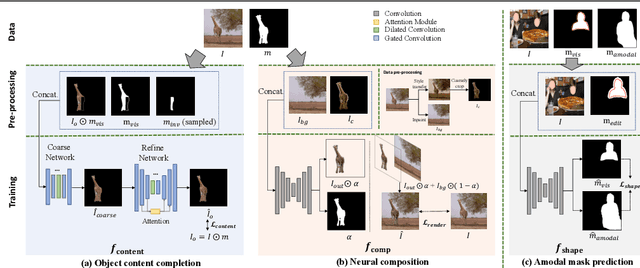


Image composition aims to blend multiple objects to form a harmonized image. Existing approaches often assume precisely segmented and intact objects. Such assumptions, however, are hard to satisfy in unconstrained scenarios. We present Amodal Instance Composition for compositing imperfect -- potentially incomplete and/or coarsely segmented -- objects onto a target image. We first develop object shape prediction and content completion modules to synthesize the amodal contents. We then propose a neural composition model to blend the objects seamlessly. Our primary technical novelty lies in using separate foreground/background representations and blending mask prediction to alleviate segmentation errors. Our results show state-of-the-art performance on public COCOA and KINS benchmarks and attain favorable visual results across diverse scenes. We demonstrate various image composition applications such as object insertion and de-occlusion.
Robust Consistent Video Depth Estimation
Dec 10, 2020

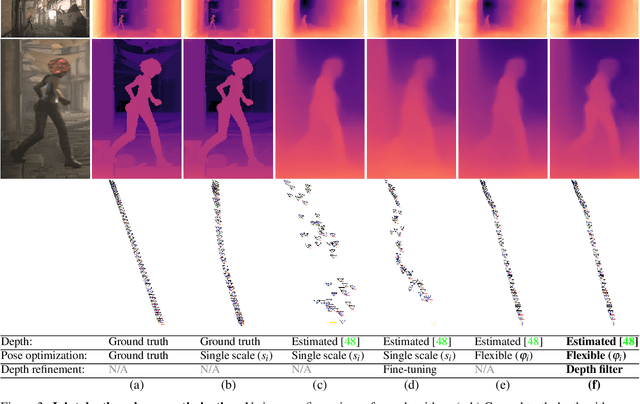

We present an algorithm for estimating consistent dense depth maps and camera poses from a monocular video. We integrate a learning-based depth prior, in the form of a convolutional neural network trained for single-image depth estimation, with geometric optimization, to estimate a smooth camera trajectory as well as detailed and stable depth reconstruction. Our algorithm combines two complementary techniques: (1) flexible deformation-splines for low-frequency large-scale alignment and (2) geometry-aware depth filtering for high-frequency alignment of fine depth details. In contrast to prior approaches, our method does not require camera poses as input and achieves robust reconstruction for challenging hand-held cell phone captures containing a significant amount of noise, shake, motion blur, and rolling shutter deformations. Our method quantitatively outperforms state-of-the-arts on the Sintel benchmark for both depth and pose estimations and attains favorable qualitative results across diverse wild datasets.
Weakly Supervised Semantic Segmentation in 3D Graph-Structured Point Clouds of Wild Scenes
May 17, 2020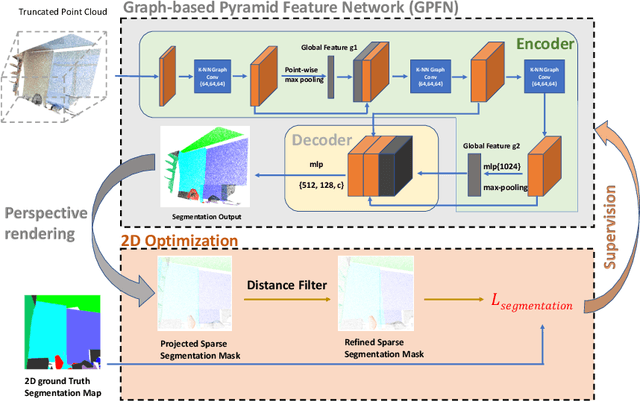
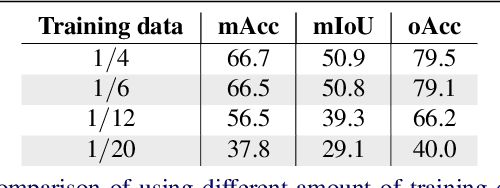
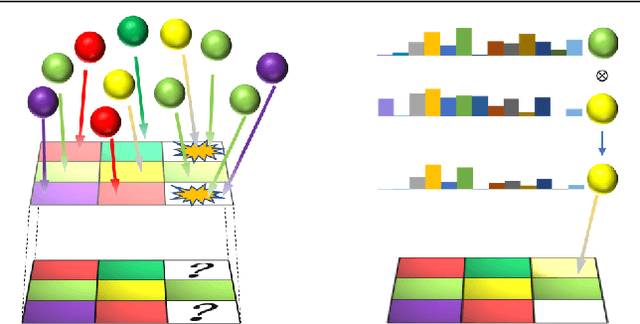
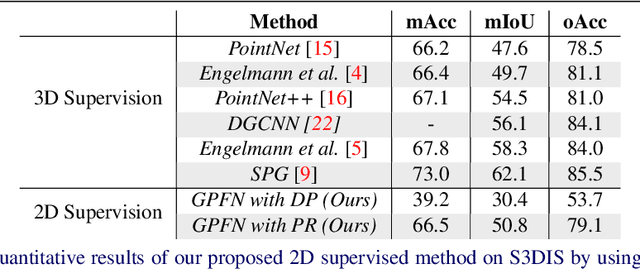
The deficiency of 3D segmentation labels is one of the main obstacles to effective point cloud segmentation, especially for scenes in the wild with varieties of different objects. To alleviate this issue, we propose a novel deep graph convolutional network-based framework for large-scale semantic scene segmentation in point clouds with sole 2D supervision. Different with numerous preceding multi-view supervised approaches focusing on single object point clouds, we argue that 2D supervision is capable of providing sufficient guidance information for training 3D semantic segmentation models of natural scene point clouds while not explicitly capturing their inherent structures, even with only single view per training sample. Specifically, a Graph-based Pyramid Feature Network (GPFN) is designed to implicitly infer both global and local features of point sets and an Observability Network (OBSNet) is introduced to further solve object occlusion problem caused by complicated spatial relations of objects in 3D scenes. During the projection process, perspective rendering and semantic fusion modules are proposed to provide refined 2D supervision signals for training along with a 2D-3D joint optimization strategy. Extensive experimental results demonstrate the effectiveness of our 2D supervised framework, which achieves comparable results with the state-of-the-art approaches trained with full 3D labels, for semantic point cloud segmentation on the popular SUNCG synthetic dataset and S3DIS real-world dataset.
Incremental Scene Synthesis
Dec 11, 2018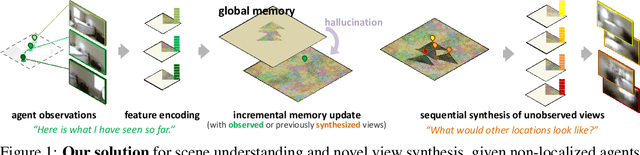
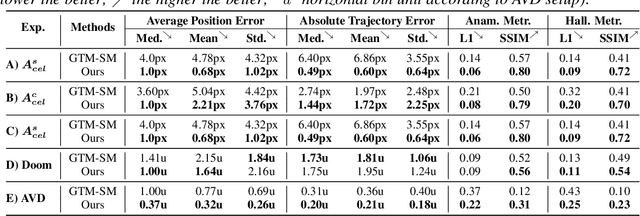
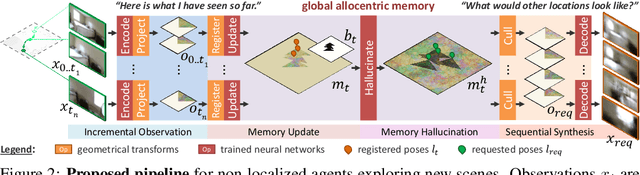
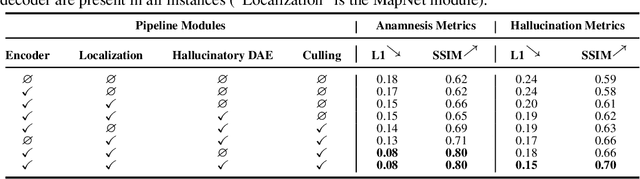
We present a method to incrementally generate complete 2D or 3D scenes with the following properties: (a) it is globally consistent at each step according to a learned scene prior, (b) real observations of an actual scene can be incorporated while observing global consistency, (c) unobserved parts of the scene can be hallucinated locally in consistence with previous observations, hallucinations and global priors, and (d) the hallucinations are statistical in nature, i.e., different consistent scenes can be generated from the same observations. To achieve this, we model the motion of an active agent through a virtual scene, where the agent at each step can either perceive a true (i.e. observed) part of the scene or generate a local hallucination. The latter can be interpreted as the expectation of the agent at this step through the scene and can already be useful, e.g., in autonomous navigation. In the limit of observing real data at each point, our method converges to solving the SLAM problem. In the limit of never observing real data, it samples entirely imagined scenes from the prior distribution. Besides autonomous agents, applications include problems where large data is required for training and testing robust real-world applications, but few data is available, necessitating data generation. We demonstrate efficacy on various 2D as well as preliminary 3D data.