 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeakly Supervised Semantic Segmentation in 3D Graph-Structured Point Clouds of Wild Scenes
Paper and Code
May 17, 2020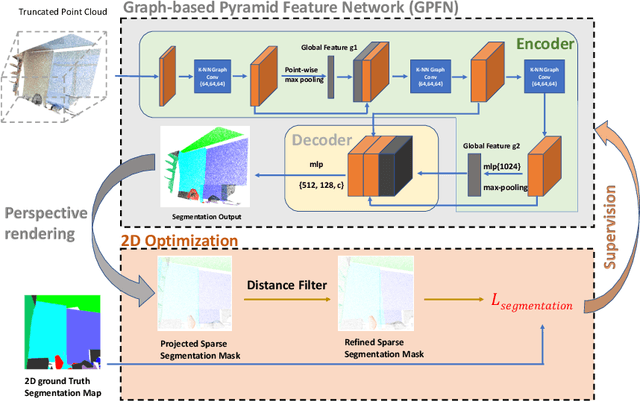
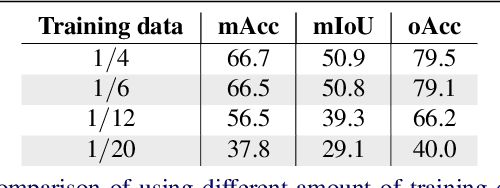
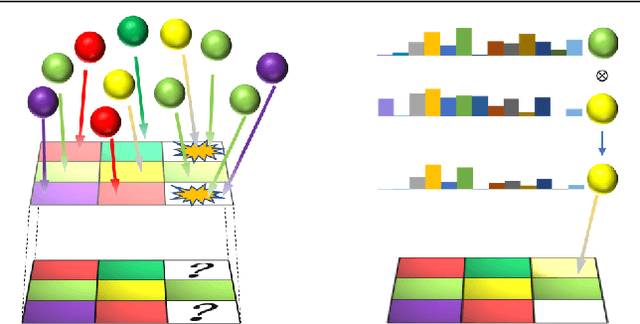
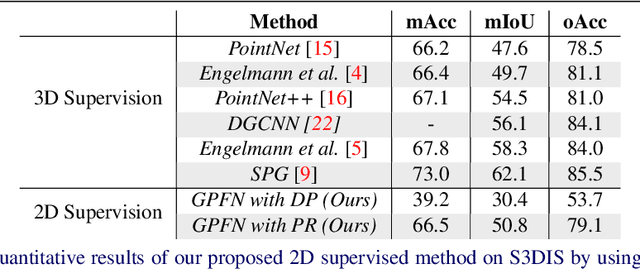
The deficiency of 3D segmentation labels is one of the main obstacles to effective point cloud segmentation, especially for scenes in the wild with varieties of different objects. To alleviate this issue, we propose a novel deep graph convolutional network-based framework for large-scale semantic scene segmentation in point clouds with sole 2D supervision. Different with numerous preceding multi-view supervised approaches focusing on single object point clouds, we argue that 2D supervision is capable of providing sufficient guidance information for training 3D semantic segmentation models of natural scene point clouds while not explicitly capturing their inherent structures, even with only single view per training sample. Specifically, a Graph-based Pyramid Feature Network (GPFN) is designed to implicitly infer both global and local features of point sets and an Observability Network (OBSNet) is introduced to further solve object occlusion problem caused by complicated spatial relations of objects in 3D scenes. During the projection process, perspective rendering and semantic fusion modules are proposed to provide refined 2D supervision signals for training along with a 2D-3D joint optimization strategy. Extensive experimental results demonstrate the effectiveness of our 2D supervised framework, which achieves comparable results with the state-of-the-art approaches trained with full 3D labels, for semantic point cloud segmentation on the popular SUNCG synthetic dataset and S3DIS real-world dataset.