 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDriveAgent: Multi-Agent Structured Reasoning with LLM and Multimodal Sensor Fusion for Autonomous Driving
May 04, 2025
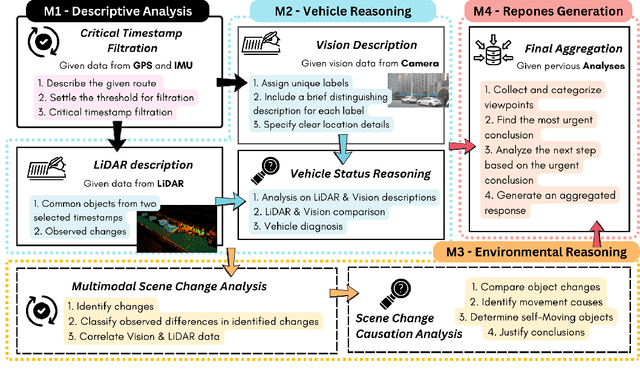
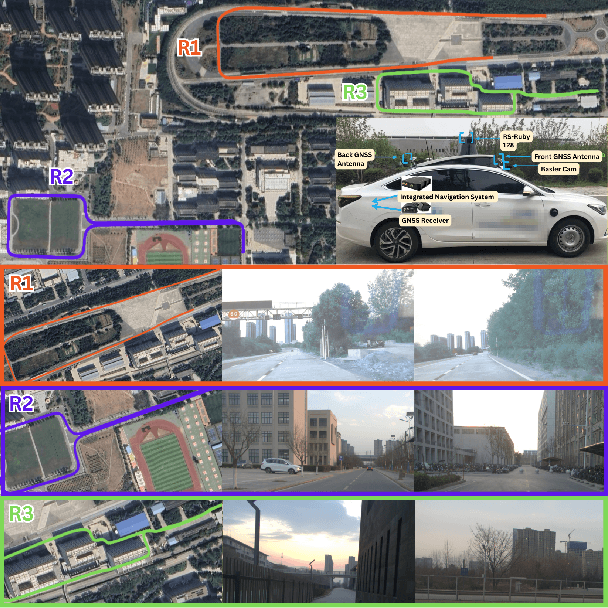
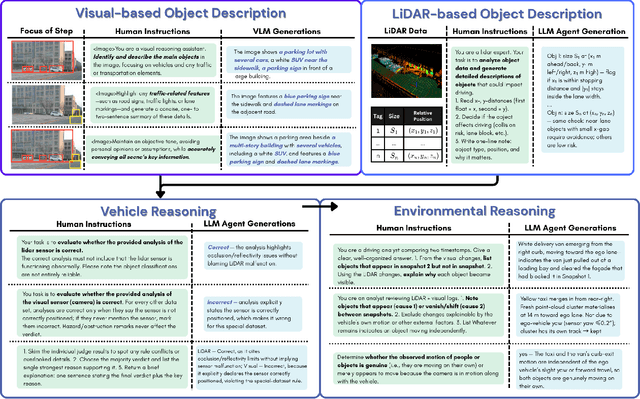
We introduce DriveAgent, a novel multi-agent autonomous driving framework that leverages large language model (LLM) reasoning combined with multimodal sensor fusion to enhance situational understanding and decision-making. DriveAgent uniquely integrates diverse sensor modalities-including camera, LiDAR, GPS, and IMU-with LLM-driven analytical processes structured across specialized agents. The framework operates through a modular agent-based pipeline comprising four principal modules: (i) a descriptive analysis agent identifying critical sensor data events based on filtered timestamps, (ii) dedicated vehicle-level analysis conducted by LiDAR and vision agents that collaboratively assess vehicle conditions and movements, (iii) environmental reasoning and causal analysis agents explaining contextual changes and their underlying mechanisms, and (iv) an urgency-aware decision-generation agent prioritizing insights and proposing timely maneuvers. This modular design empowers the LLM to effectively coordinate specialized perception and reasoning agents, delivering cohesive, interpretable insights into complex autonomous driving scenarios. Extensive experiments on challenging autonomous driving datasets demonstrate that DriveAgent is achieving superior performance on multiple metrics against baseline methods. These results validate the efficacy of the proposed LLM-driven multi-agent sensor fusion framework, underscoring its potential to substantially enhance the robustness and reliability of autonomous driving systems.
LTCF-Net: A Transformer-Enhanced Dual-Channel Fourier Framework for Low-Light Image Restoration
Nov 24, 2024



We introduce LTCF-Net, a novel network architecture designed for enhancing low-light images. Unlike Retinex-based methods, our approach utilizes two color spaces - LAB and YUV - to efficiently separate and process color information, by leveraging the separation of luminance from chromatic components in color images. In addition, our model incorporates the Transformer architecture to comprehensively understand image content while maintaining computational efficiency. To dynamically balance the brightness in output images, we also introduce a Fourier transform module that adjusts the luminance channel in the frequency domain. This mechanism could uniformly balance brightness across different regions while eliminating background noises, and thereby enhancing visual quality. By combining these innovative components, LTCF-Net effectively improves low-light image quality while keeping the model lightweight. Experimental results demonstrate that our method outperforms current state-of-the-art approaches across multiple evaluation metrics and datasets, achieving more natural color restoration and a balanced brightness distribution.
Benchmarking Neural Radiance Fields for Autonomous Robots: An Overview
May 09, 2024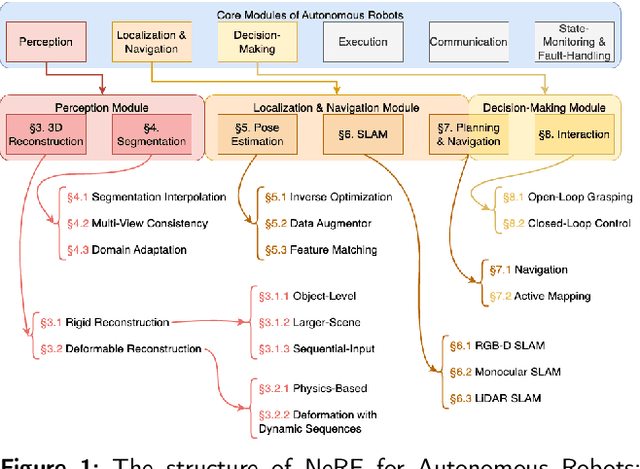
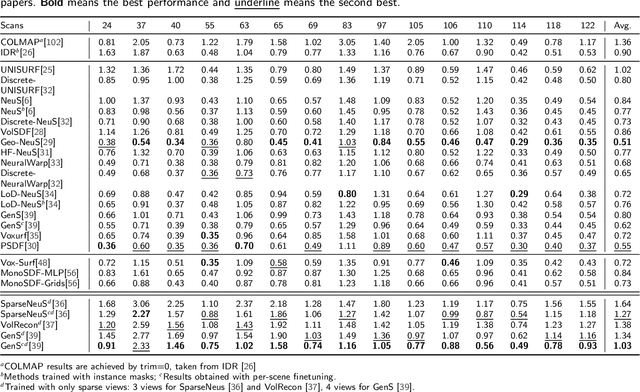
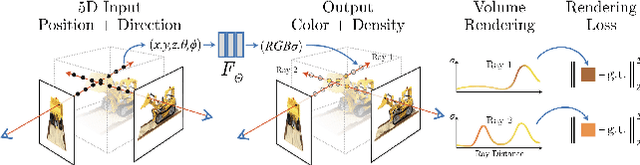
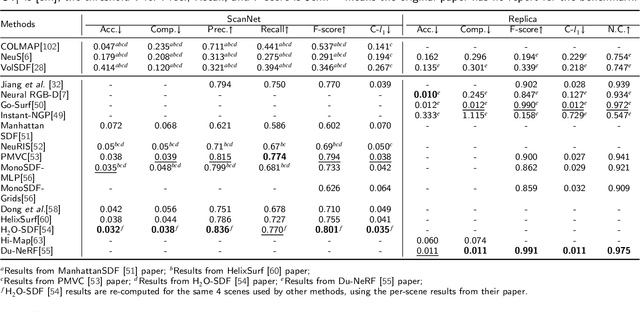
Neural Radiance Fields (NeRF) have emerged as a powerful paradigm for 3D scene representation, offering high-fidelity renderings and reconstructions from a set of sparse and unstructured sensor data. In the context of autonomous robotics, where perception and understanding of the environment are pivotal, NeRF holds immense promise for improving performance. In this paper, we present a comprehensive survey and analysis of the state-of-the-art techniques for utilizing NeRF to enhance the capabilities of autonomous robots. We especially focus on the perception, localization and navigation, and decision-making modules of autonomous robots and delve into tasks crucial for autonomous operation, including 3D reconstruction, segmentation, pose estimation, simultaneous localization and mapping (SLAM), navigation and planning, and interaction. Our survey meticulously benchmarks existing NeRF-based methods, providing insights into their strengths and limitations. Moreover, we explore promising avenues for future research and development in this domain. Notably, we discuss the integration of advanced techniques such as 3D Gaussian splatting (3DGS), large language models (LLM), and generative AIs, envisioning enhanced reconstruction efficiency, scene understanding, decision-making capabilities. This survey serves as a roadmap for researchers seeking to leverage NeRFs to empower autonomous robots, paving the way for innovative solutions that can navigate and interact seamlessly in complex environments.
Robotic Inspection and Characterization of Subsurface Defects on Concrete Structures Using Impact Sounding
Aug 12, 2022
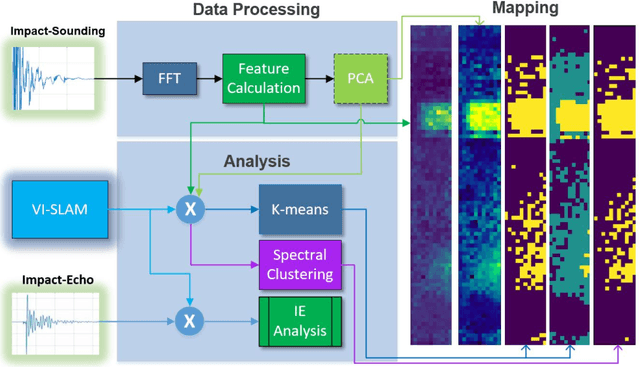
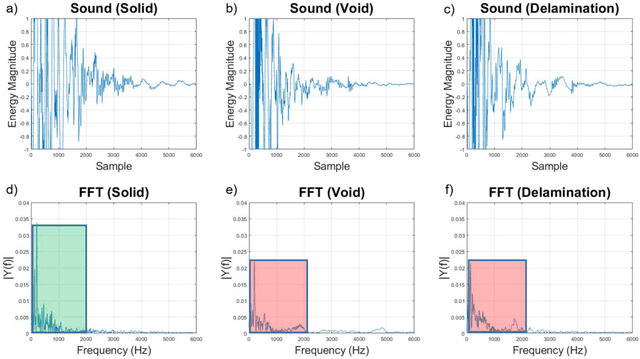
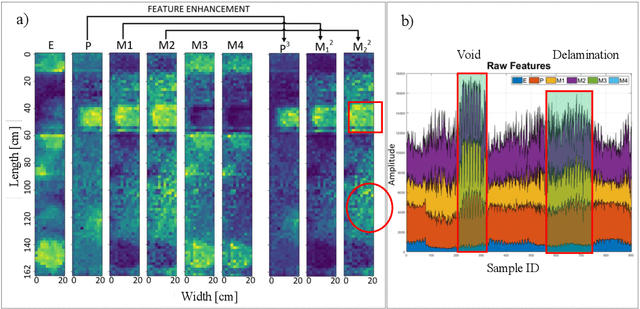
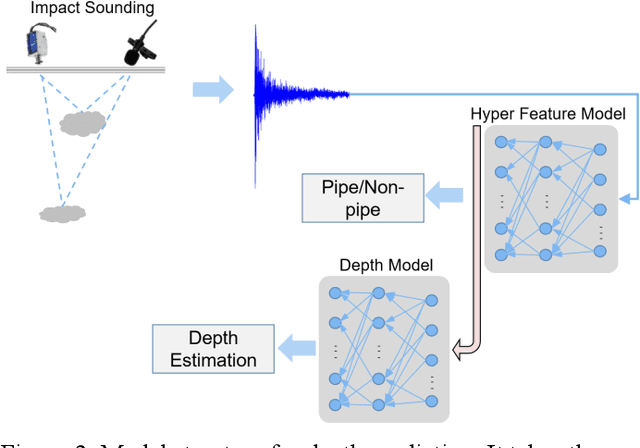
Impact-sounding (IS) and impact-echo (IE) are well-developed non-destructive evaluation (NDE) methods that are widely used for inspections of concrete structures to ensure the safety and sustainability. However, it is a tedious work to collect IS and IE data along grid lines covering a large target area for characterization of subsurface defects. On the other hand, data processing is very complicated that requires domain experts to interpret the results. To address the above problems, we present a novel robotic inspection system named as Impact-Rover to automate the data collection process and introduce data analytics software to visualize the inspection result allowing regular non-professional people to understand. The system consists of three modules: 1) a robotic platform with vertical mobility to collect IS and IE data in hard-to-reach locations, 2) vision-based positioning module that fuses the RGB-D camera, IMU and wheel encoder to estimate the 6-DOF pose of the robot, 3) a data analytics software module for processing the IS data to generate defect maps. The Impact-Rover hosts both IE and IS devices on a sliding mechanism and can perform move-stop-sample operations to collect multiple IS and IE data at adjustable spacing. The robot takes samples much faster than the manual data collection method because it automatically takes the multiple measurements along a straight line and records the locations. This paper focuses on reporting experimental results on IS. We calculate features and use unsupervised learning methods for analyzing the data. By combining the pose generated by our vision-based localization module and the position of the head of the sliding mechanism we can generate maps of possible defects. The results on concrete slabs demonstrate that our impact-sounding system can effectively reveal shallow defects.
Automatic Impact-sounding Acoustic Inspection of Concrete Structure
Oct 25, 2021
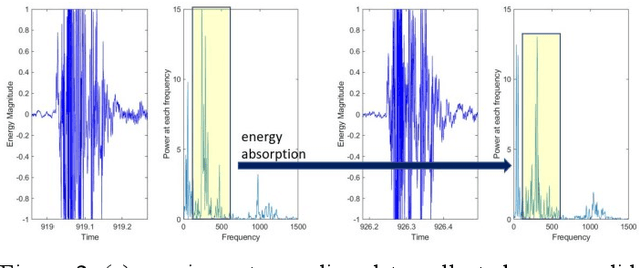

Impact sounding signal has been shown to contain information about structural integrity flaws and subsurface objects from previous research. As non-destructive testing (NDT) method, one of the biggest challenges in impact sounding based inspection is the subsurface targets detection and reconstruction. This paper presents the importance and practicability of using solenoids to trigger impact sounding signal and using acoustic data to reconstruct subsurface objects to address this issue. First, by taking advantage of Visual Simultaneous Localization and Mapping (V-SLAM), we could obtain the 3D position of the robot during the inspection. Second, our NDE method is based on Frequency Density (FD) analysis for the Fast Fourier Transform (FFT) of the impact sounding signal. At last, by combining the 3D position data and acoustic data, this paper creates a 3D map to highlight the possible subsurface objects. The experimental results demonstrate the feasibility of the method.
Robotic Inspection and 3D GPR-based Reconstruction for Underground Utilities
Jun 03, 2021

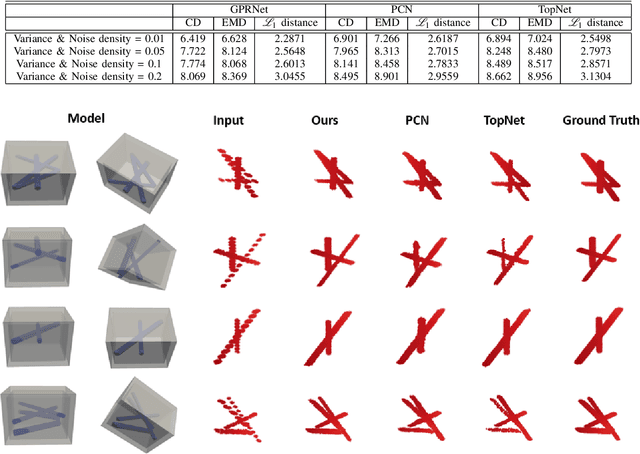
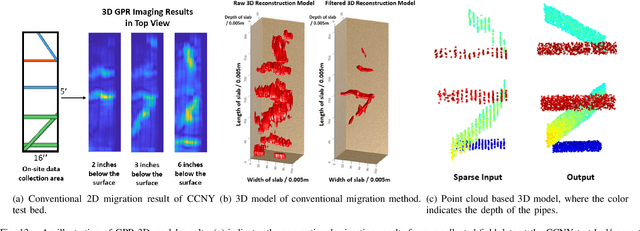
Ground Penetrating Radar (GPR) is an effective non-destructive evaluation (NDE) device for inspecting and surveying subsurface objects (i.e., rebars, utility pipes) in complex environments. However, the current practice for GPR data collection requires a human inspector to move a GPR cart along pre-marked grid lines and record the GPR data in both X and Y directions for post-processing by 3D GPR imaging software. It is time-consuming and tedious work to survey a large area. Furthermore, identifying the subsurface targets depends on the knowledge of an experienced engineer, who has to make manual and subjective interpretation that limits the GPR applications, especially in large-scale scenarios. In addition, the current GPR imaging technology is not intuitive, and not for normal users to understand, and not friendly to visualize. To address the above challenges, this paper presents a novel robotic system to collect GPR data, interpret GPR data, localize the underground utilities, reconstruct and visualize the underground objects' dense point cloud model in a user-friendly manner. This system is composed of three modules: 1) a vision-aided Omni-directional robotic data collection platform, which enables the GPR antenna to scan the target area freely with an arbitrary trajectory while using a visual-inertial-based positioning module tags the GPR measurements with positioning information; 2) a deep neural network (DNN) migration module to interpret the raw GPR B-scan image into a cross-section of object model; 3) a DNN-based 3D reconstruction method, i.e., GPRNet, to generate underground utility model represented as fine 3D point cloud. Comparative studies on synthetic and field GPR raw data with various incompleteness and noise are performed.
Towards 3D Metric GPR Imaging Based on DNN Noise Removal and Dielectric Estimation
May 15, 2021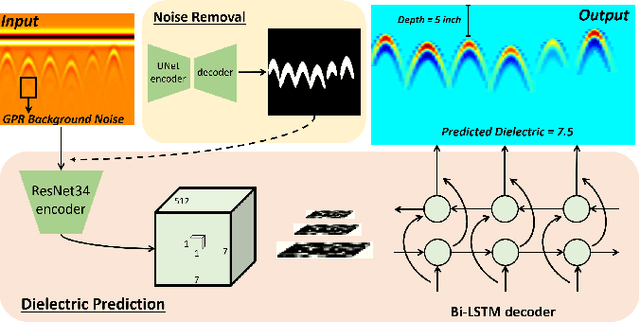

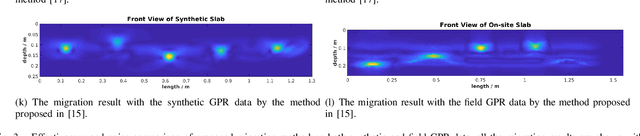
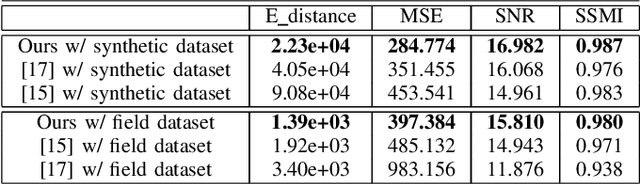
Ground Penetrating Radar (GPR) is one of the most important non-destructive evaluation (NDE) devices to detect subsurface objects (i.e., rebars, utility pipes) and reveal the underground scene. The two biggest challenges in GPR-based inspection are the GPR data collection and subsurface target imaging. To address these challenges, we propose a robotic solution that automates the GPR data collection process with a free motion pattern. It facilitates the 3D metric GPR imaging by tagging the pose information with GPR measurement in real-time. We also introduce a deep neural network (DNN) based GPR data analysis method which includes a noise removal segmentation module to clear the noise in GPR raw data and a DielectricNet to estimate the dielectric value of subsurface media in each GPR B-scan data. We use both the field and synthetic data to verify the proposed method. Experimental results demonstrate that our proposed method can achieve better performance and faster processing speed in GPR data collection and 3D GPR imaging than other methods.
* under review
GPR-based Model Reconstruction System for Underground Utilities Using GPRNet
Nov 05, 2020
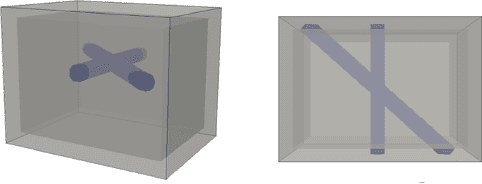
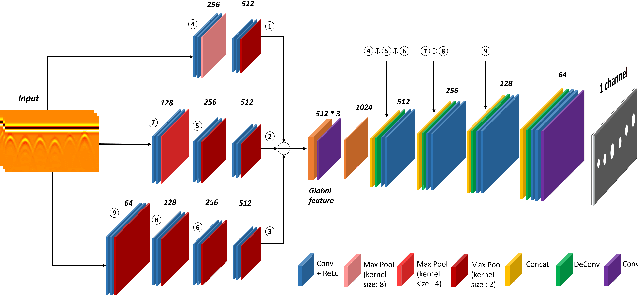
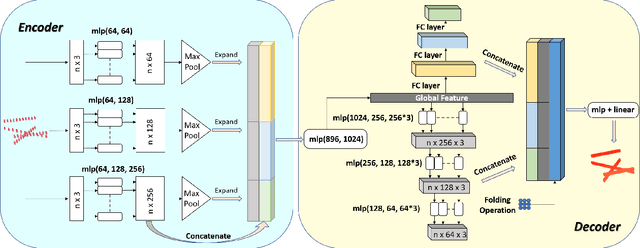
Ground Penetrating Radar (GPR) is one of the most important non-destructive evaluation (NDE) instruments to detect and locate underground objects (i.e. rebars, utility pipes). Many of the previous researches focus on GPR image-based feature detection only, and none can process sparse GPR measurements to successfully reconstruct a very fine and detailed 3D model of underground objects for better visualization. To address this problem, this paper presents a novel robotic system to collect GPR data, localize the underground utilities, and reconstruct the underground objects' dense point cloud model. This system is composed of three modules: 1) visual-inertial-based GPR data collection module which tags the GPR measurements with positioning information provided by an omnidirectional robot; 2) a deep neural network (DNN) migration module to interpret the raw GPR B-scan image into a cross-section of object model; 3) a DNN-based 3D reconstruction module, i.e., GPRNet, to generate underground utility model with the fine 3D point cloud. The experiments show that our method can generate a dense and complete point cloud model of pipe-shaped utilities based on a sparse input, i.e., GPR raw data, with various levels of incompleteness and noise. The experiment results on synthetic data as well as field test data verified the effectiveness of our method.
Weakly Supervised Semantic Segmentation in 3D Graph-Structured Point Clouds of Wild Scenes
May 17, 2020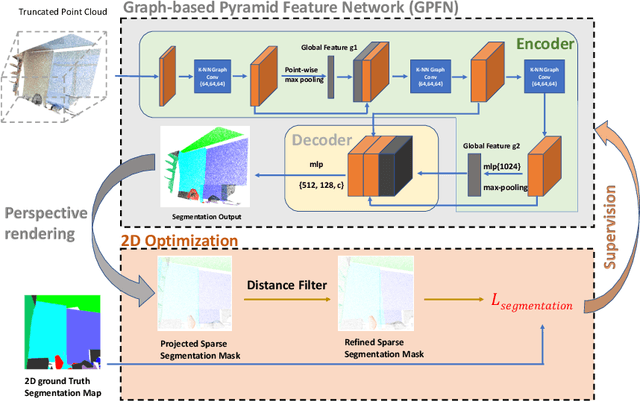
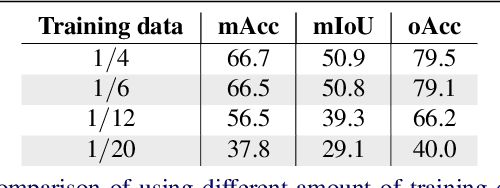
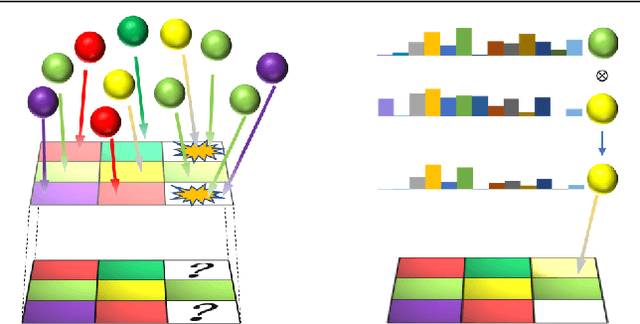
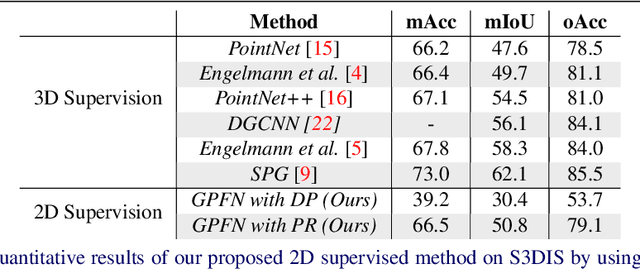
The deficiency of 3D segmentation labels is one of the main obstacles to effective point cloud segmentation, especially for scenes in the wild with varieties of different objects. To alleviate this issue, we propose a novel deep graph convolutional network-based framework for large-scale semantic scene segmentation in point clouds with sole 2D supervision. Different with numerous preceding multi-view supervised approaches focusing on single object point clouds, we argue that 2D supervision is capable of providing sufficient guidance information for training 3D semantic segmentation models of natural scene point clouds while not explicitly capturing their inherent structures, even with only single view per training sample. Specifically, a Graph-based Pyramid Feature Network (GPFN) is designed to implicitly infer both global and local features of point sets and an Observability Network (OBSNet) is introduced to further solve object occlusion problem caused by complicated spatial relations of objects in 3D scenes. During the projection process, perspective rendering and semantic fusion modules are proposed to provide refined 2D supervision signals for training along with a 2D-3D joint optimization strategy. Extensive experimental results demonstrate the effectiveness of our 2D supervised framework, which achieves comparable results with the state-of-the-art approaches trained with full 3D labels, for semantic point cloud segmentation on the popular SUNCG synthetic dataset and S3DIS real-world dataset.