 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVFM-Recon: Unlocking Cross-Domain Scene-Level Neural Reconstruction with Scale-Aligned Foundation Priors
Mar 13, 2026Scene-level neural volumetric reconstruction from monocular videos remains challenging, especially under severe domain shifts. Although recent advances in vision foundation models (VFMs) provide transferable generalized priors learned from large-scale data, their scaleambiguous predictions are incompatible with the scale consistency required by volumetric fusion. To address this gap, we present VFMRecon, the first attempt to bridge transferable VFM priors with scaleconsistent requirements in scene-level neural reconstruction. Specifically, we first introduce a lightweight scale alignment stage that restores multiview scale coherence. We then integrate pretrained VFM features into the neural volumetric reconstruction pipeline via lightweight task-specific adapters, which are trained for reconstruction while preserving the crossdomain robustness of pretrained representations. We train our model on ScanNet train split and evaluate on both in-distribution ScanNet test split and out-of-distribution TUM RGB-D and Tanks and Temples datasets. The results demonstrate that our model achieves state-of-theart performance across all datasets domains. In particular, on the challenging outdoor Tanks and Temples dataset, our model achieves an F1 score of 70.1 in reconstructed mesh evaluation, substantially outperforming the closest competitor, VGGT, which only attains 51.8.
VIPeR: Visual Incremental Place Recognition with Adaptive Mining and Lifelong Learning
Jul 31, 2024Visual place recognition (VPR) is an essential component of many autonomous and augmented/virtual reality systems. It enables the systems to robustly localize themselves in large-scale environments. Existing VPR methods demonstrate attractive performance at the cost of heavy pre-training and limited generalizability. When deployed in unseen environments, these methods exhibit significant performance drops. Targeting this issue, we present VIPeR, a novel approach for visual incremental place recognition with the ability to adapt to new environments while retaining the performance of previous environments. We first introduce an adaptive mining strategy that balances the performance within a single environment and the generalizability across multiple environments. Then, to prevent catastrophic forgetting in lifelong learning, we draw inspiration from human memory systems and design a novel memory bank for our VIPeR. Our memory bank contains a sensory memory, a working memory and a long-term memory, with the first two focusing on the current environment and the last one for all previously visited environments. Additionally, we propose a probabilistic knowledge distillation to explicitly safeguard the previously learned knowledge. We evaluate our proposed VIPeR on three large-scale datasets, namely Oxford Robotcar, Nordland, and TartanAir. For comparison, we first set a baseline performance with naive finetuning. Then, several more recent lifelong learning methods are compared. Our VIPeR achieves better performance in almost all aspects with the biggest improvement of 13.65% in average performance.
Benchmarking Neural Radiance Fields for Autonomous Robots: An Overview
May 09, 2024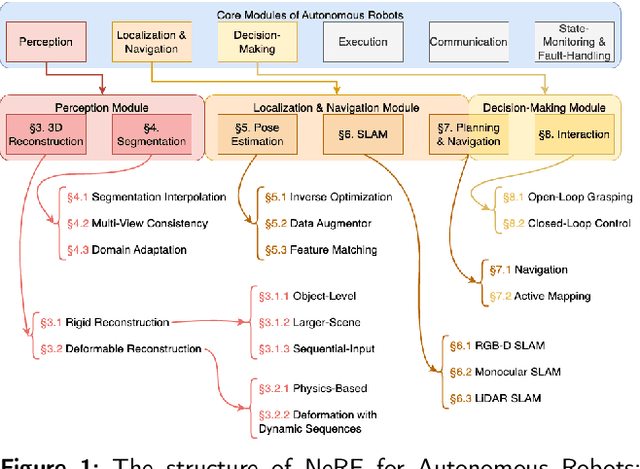
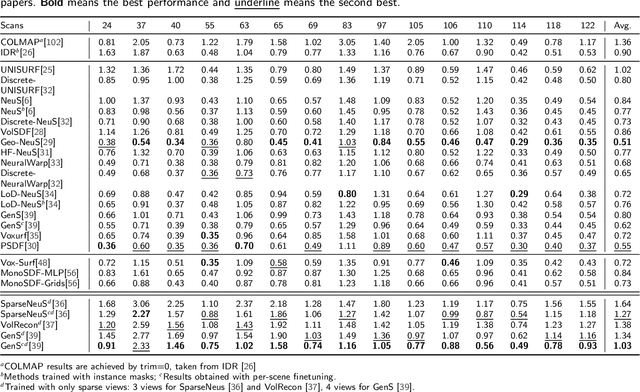
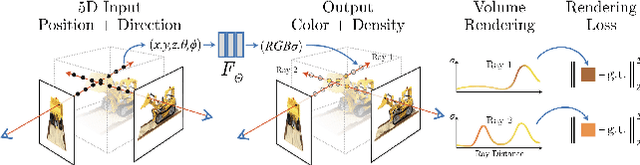
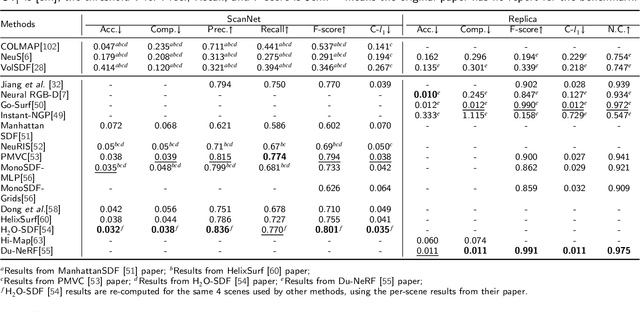
Neural Radiance Fields (NeRF) have emerged as a powerful paradigm for 3D scene representation, offering high-fidelity renderings and reconstructions from a set of sparse and unstructured sensor data. In the context of autonomous robotics, where perception and understanding of the environment are pivotal, NeRF holds immense promise for improving performance. In this paper, we present a comprehensive survey and analysis of the state-of-the-art techniques for utilizing NeRF to enhance the capabilities of autonomous robots. We especially focus on the perception, localization and navigation, and decision-making modules of autonomous robots and delve into tasks crucial for autonomous operation, including 3D reconstruction, segmentation, pose estimation, simultaneous localization and mapping (SLAM), navigation and planning, and interaction. Our survey meticulously benchmarks existing NeRF-based methods, providing insights into their strengths and limitations. Moreover, we explore promising avenues for future research and development in this domain. Notably, we discuss the integration of advanced techniques such as 3D Gaussian splatting (3DGS), large language models (LLM), and generative AIs, envisioning enhanced reconstruction efficiency, scene understanding, decision-making capabilities. This survey serves as a roadmap for researchers seeking to leverage NeRFs to empower autonomous robots, paving the way for innovative solutions that can navigate and interact seamlessly in complex environments.
Vox-Fusion++: Voxel-based Neural Implicit Dense Tracking and Mapping with Multi-maps
Mar 19, 2024In this paper, we introduce Vox-Fusion++, a multi-maps-based robust dense tracking and mapping system that seamlessly fuses neural implicit representations with traditional volumetric fusion techniques. Building upon the concept of implicit mapping and positioning systems, our approach extends its applicability to real-world scenarios. Our system employs a voxel-based neural implicit surface representation, enabling efficient encoding and optimization of the scene within each voxel. To handle diverse environments without prior knowledge, we incorporate an octree-based structure for scene division and dynamic expansion. To achieve real-time performance, we propose a high-performance multi-process framework. This ensures the system's suitability for applications with stringent time constraints. Additionally, we adopt the idea of multi-maps to handle large-scale scenes, and leverage loop detection and hierarchical pose optimization strategies to reduce long-term pose drift and remove duplicate geometry. Through comprehensive evaluations, we demonstrate that our method outperforms previous methods in terms of reconstruction quality and accuracy across various scenarios. We also show that our Vox-Fusion++ can be used in augmented reality and collaborative mapping applications. Our source code will be publicly available at \url{https://github.com/zju3dv/Vox-Fusion_Plus_Plus}
AEGIS-Net: Attention-guided Multi-Level Feature Aggregation for Indoor Place Recognition
Dec 15, 2023



We present AEGIS-Net, a novel indoor place recognition model that takes in RGB point clouds and generates global place descriptors by aggregating lower-level color, geometry features and higher-level implicit semantic features. However, rather than simple feature concatenation, self-attention modules are employed to select the most important local features that best describe an indoor place. Our AEGIS-Net is made of a semantic encoder, a semantic decoder and an attention-guided feature embedding. The model is trained in a 2-stage process with the first stage focusing on an auxiliary semantic segmentation task and the second one on the place recognition task. We evaluate our AEGIS-Net on the ScanNetPR dataset and compare its performance with a pre-deep-learning feature-based method and five state-of-the-art deep-learning-based methods. Our AEGIS-Net achieves exceptional performance and outperforms all six methods.
Vox-Fusion: Dense Tracking and Mapping with Voxel-based Neural Implicit Representation
Oct 28, 2022In this work, we present a dense tracking and mapping system named Vox-Fusion, which seamlessly fuses neural implicit representations with traditional volumetric fusion methods. Our approach is inspired by the recently developed implicit mapping and positioning system and further extends the idea so that it can be freely applied to practical scenarios. Specifically, we leverage a voxel-based neural implicit surface representation to encode and optimize the scene inside each voxel. Furthermore, we adopt an octree-based structure to divide the scene and support dynamic expansion, enabling our system to track and map arbitrary scenes without knowing the environment like in previous works. Moreover, we proposed a high-performance multi-process framework to speed up the method, thus supporting some applications that require real-time performance. The evaluation results show that our methods can achieve better accuracy and completeness than previous methods. We also show that our Vox-Fusion can be used in augmented reality and virtual reality applications. Our source code is publicly available at https://github.com/zju3dv/Vox-Fusion.
Vox-Surf: Voxel-based Implicit Surface Representation
Aug 21, 2022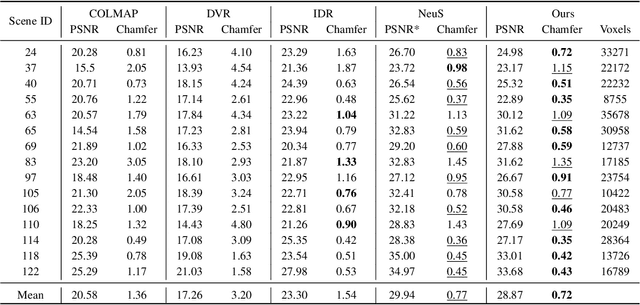
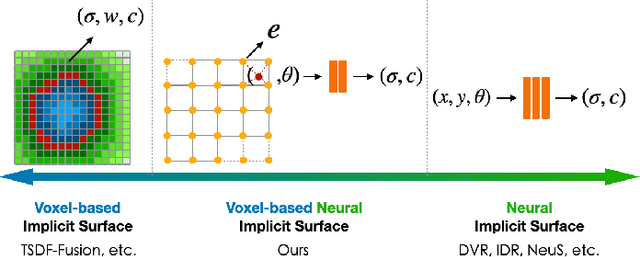
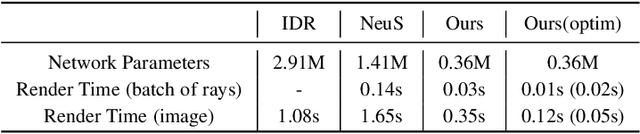
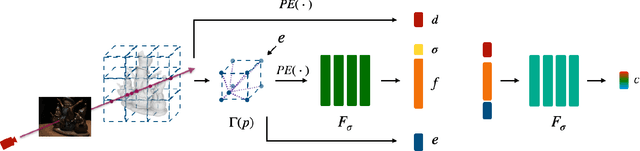
Virtual content creation and interaction play an important role in modern 3D applications such as AR and VR. Recovering detailed 3D models from real scenes can significantly expand the scope of its applications and has been studied for decades in the computer vision and computer graphics community. We propose Vox-Surf, a voxel-based implicit surface representation. Our Vox-Surf divides the space into finite bounded voxels. Each voxel stores geometry and appearance information in its corner vertices. Vox-Surf is suitable for almost any scenario thanks to sparsity inherited from voxel representation and can be easily trained from multiple view images. We leverage the progressive training procedure to extract important voxels gradually for further optimization so that only valid voxels are preserved, which greatly reduces the number of sampling points and increases rendering speed.The fine voxels can also be considered as the bounding volume for collision detection.The experiments show that Vox-Surf representation can learn delicate surface details and accurate color with less memory and faster rendering speed than other methods.We also show that Vox-Surf can be more practical in scene editing and AR applications.
FD-SLAM: 3-D Reconstruction Using Features and Dense Matching
Mar 25, 2022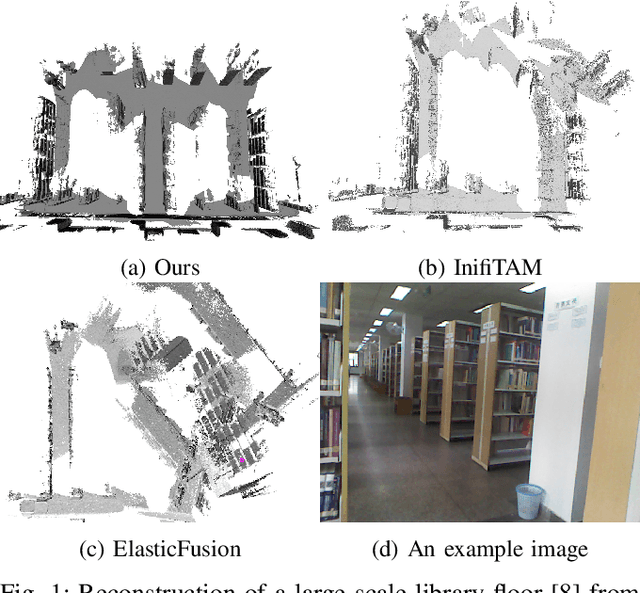
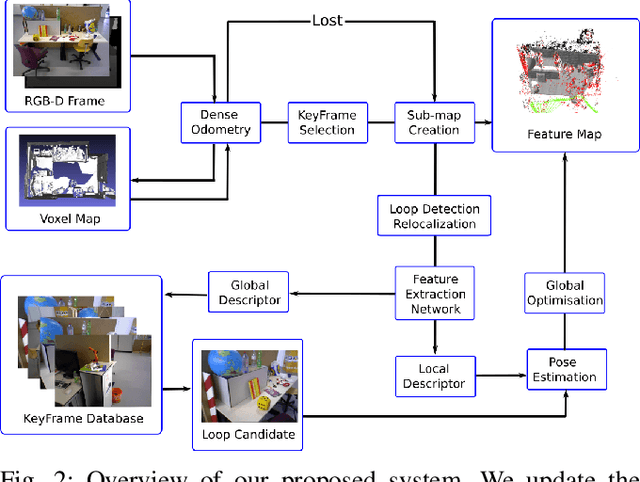

It is well known that visual SLAM systems based on dense matching are locally accurate but are also susceptible to long-term drift and map corruption. In contrast, feature matching methods can achieve greater long-term consistency but can suffer from inaccurate local pose estimation when feature information is sparse. Based on these observations, we propose an RGB-D SLAM system that leverages the advantages of both approaches: using dense frame-to-model odometry to build accurate sub-maps and on-the-fly feature-based matching across sub-maps for global map optimisation. In addition, we incorporate a learning-based loop closure component based on 3-D features which further stabilises map building. We have evaluated the approach on indoor sequences from public datasets, and the results show that it performs on par or better than state-of-the-art systems in terms of map reconstruction quality and pose estimation. The approach can also scale to large scenes where other systems often fail.
CGS-Net: Aggregating Colour, Geometry and Semantic Features for Large-Scale Indoor Place Recognition
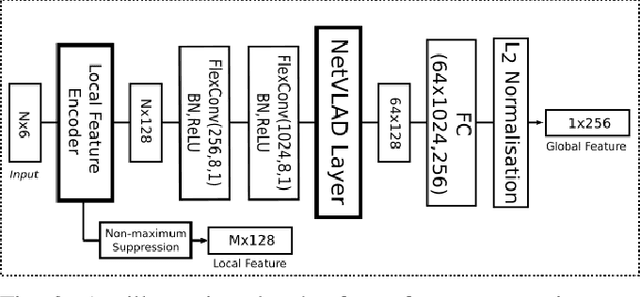
Feb 04, 2022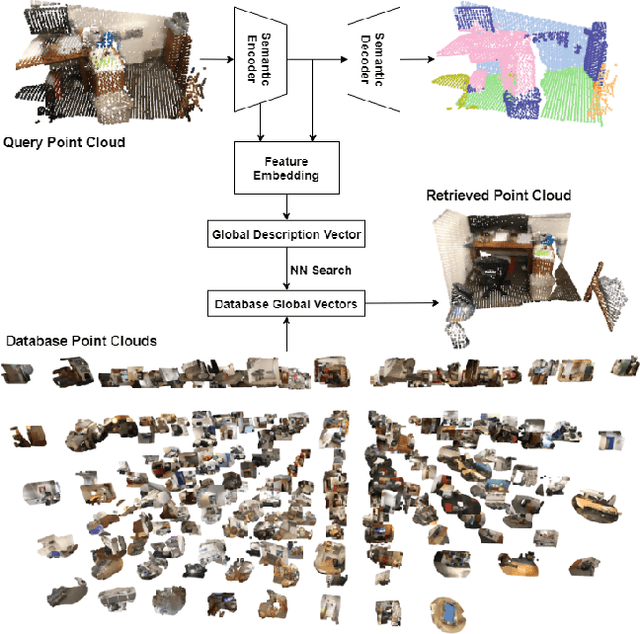
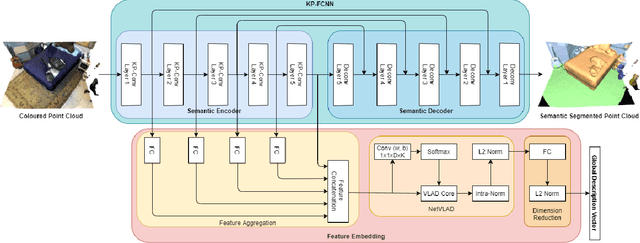


We describe an approach to large-scale indoor place recognition that aggregates low-level colour and geometric features with high-level semantic features. We use a deep learning network that takes in RGB point clouds and extracts local features with five 3-D kernel point convolutional (KPConv) layers. We specifically train the KPConv layers on the semantic segmentation task to ensure that the extracted local features are semantically meaningful. Then, feature maps from all the five KPConv layers are concatenated together and fed into the NetVLAD layer to generate the global descriptors. The approach is trained and evaluated using a large-scale indoor place recognition dataset derived from the ScanNet dataset, with a test set comprising 3,608 point clouds generated from 100 different rooms. Comparison with a traditional feature based method and three state-of-the-art deep learning methods demonstrate that the approach significantly outperforms all four methods, achieving, for example, a top-3 average recall rate of 75% compared with 41% for the closest rival method.
Object-Augmented RGB-D SLAM for Wide-Disparity Relocalisation
Aug 05, 2021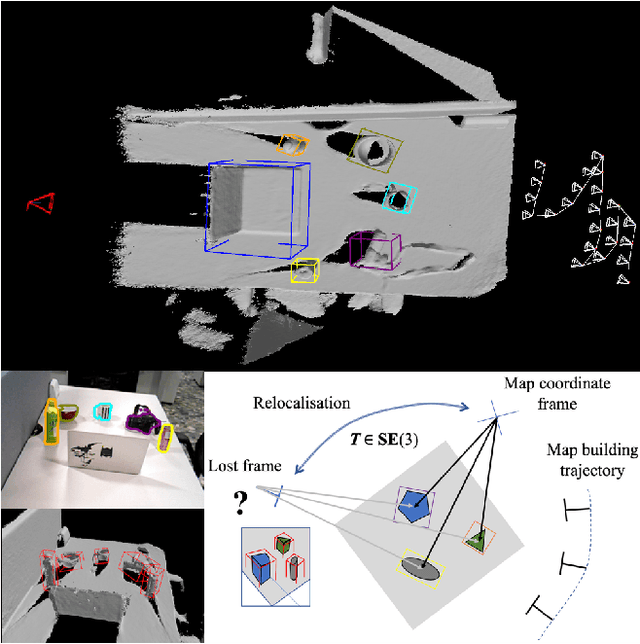
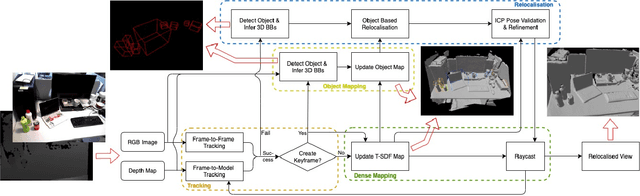
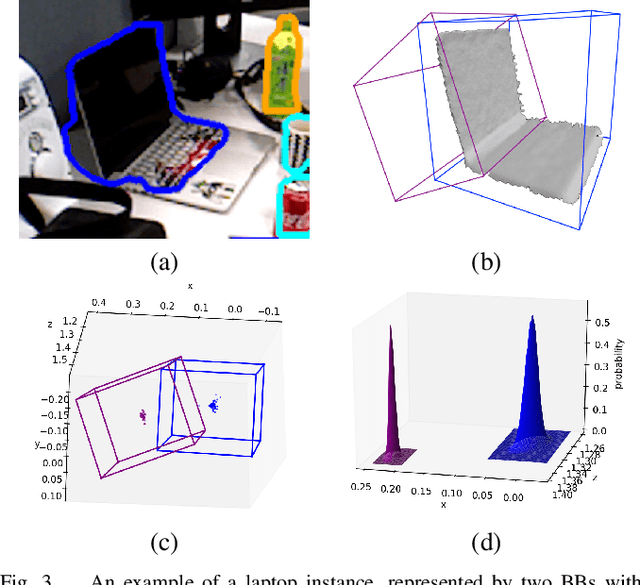

We propose a novel object-augmented RGB-D SLAM system that is capable of constructing a consistent object map and performing relocalisation based on centroids of objects in the map. The approach aims to overcome the view dependence of appearance-based relocalisation methods using point features or images. During the map construction, we use a pre-trained neural network to detect objects and estimate 6D poses from RGB-D data. An incremental probabilistic model is used to aggregate estimates over time to create the object map. Then in relocalisation, we use the same network to extract objects-of-interest in the `lost' frames. Pairwise geometric matching finds correspondences between map and frame objects, and probabilistic absolute orientation followed by application of iterative closest point to dense depth maps and object centroids gives relocalisation. Results of experiments in desktop environments demonstrate very high success rates even for frames with widely different viewpoints from those used to construct the map, significantly outperforming two appearance-based methods.