 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComputer-Aided Road Inspection: Systems and Algorithms
Mar 04, 2022
Road damage is an inconvenience and a safety hazard, severely affecting vehicle condition, driving comfort, and traffic safety. The traditional manual visual road inspection process is pricey, dangerous, exhausting, and cumbersome. Also, manual road inspection results are qualitative and subjective, as they depend entirely on the inspector's personal experience. Therefore, there is an ever-increasing need for automated road inspection systems. This chapter first compares the five most common road damage types. Then, 2-D/3-D road imaging systems are discussed. Finally, state-of-the-art machine vision and intelligence-based road damage detection algorithms are introduced.
Computer Stereo Vision for Autonomous Driving
Dec 17, 2020


As an important component of autonomous systems, autonomous car perception has had a big leap with recent advances in parallel computing architectures. With the use of tiny but full-feature embedded supercomputers, computer stereo vision has been prevalently applied in autonomous cars for depth perception. The two key aspects of computer stereo vision are speed and accuracy. They are both desirable but conflicting properties, as the algorithms with better disparity accuracy usually have higher computational complexity. Therefore, the main aim of developing a computer stereo vision algorithm for resource-limited hardware is to improve the trade-off between speed and accuracy. In this chapter, we introduce both the hardware and software aspects of computer stereo vision for autonomous car systems. Then, we discuss four autonomous car perception tasks, including 1) visual feature detection, description and matching, 2) 3D information acquisition, 3) object detection/recognition and 4) semantic image segmentation. The principles of computer stereo vision and parallel computing on multi-threading CPU and GPU architectures are then detailed.
Learning Collision-Free Space Detection from Stereo Images: Homography Matrix Brings Better Data Augmentation
Dec 14, 2020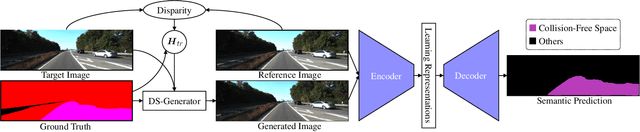
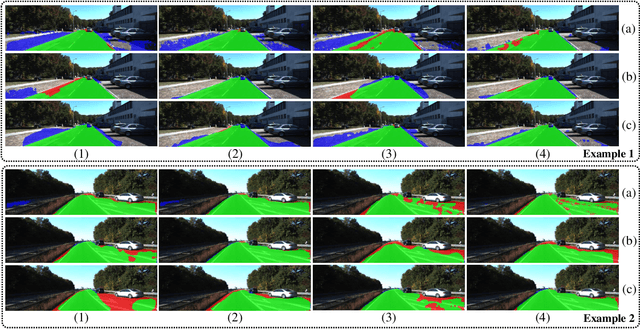

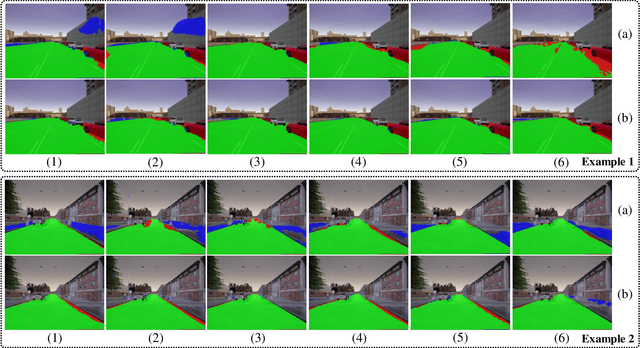
Collision-free space detection is a critical component of autonomous vehicle perception. The state-of-the-art algorithms are typically based on supervised learning. The performance of such approaches is always dependent on the quality and amount of labeled training data. Additionally, it remains an open challenge to train deep convolutional neural networks (DCNNs) using only a small quantity of training samples. Therefore, this paper mainly explores an effective training data augmentation approach that can be employed to improve the overall DCNN performance, when additional images captured from different views are available. Due to the fact that the pixels of the collision-free space (generally regarded as a planar surface) between two images captured from different views can be associated by a homography matrix, the scenario of the target image can be transformed into the reference view. This provides a simple but effective way of generating training data from additional multi-view images. Extensive experimental results, conducted with six state-of-the-art semantic segmentation DCNNs on three datasets, demonstrate the effectiveness of our proposed training data augmentation algorithm for enhancing collision-free space detection performance. When validated on the KITTI road benchmark, our approach provides the best results for stereo vision-based collision-free space detection.
Road Crack Detection Using Deep Convolutional Neural Network and Adaptive Thresholding
Apr 18, 2019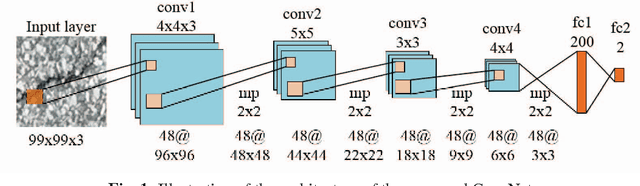
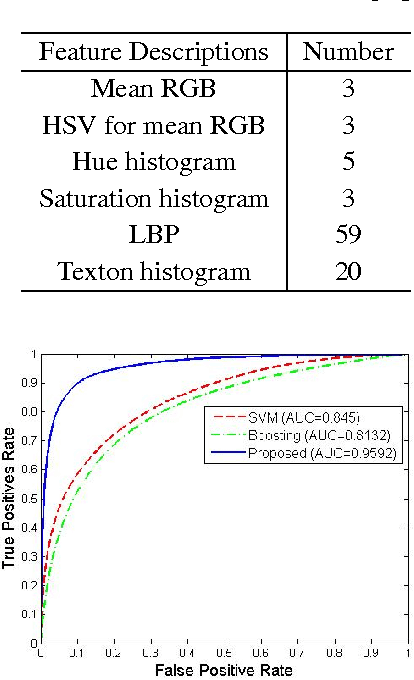
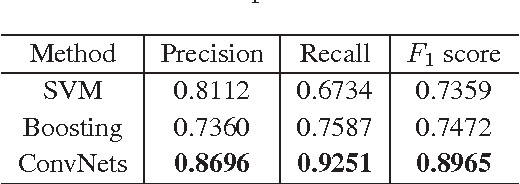
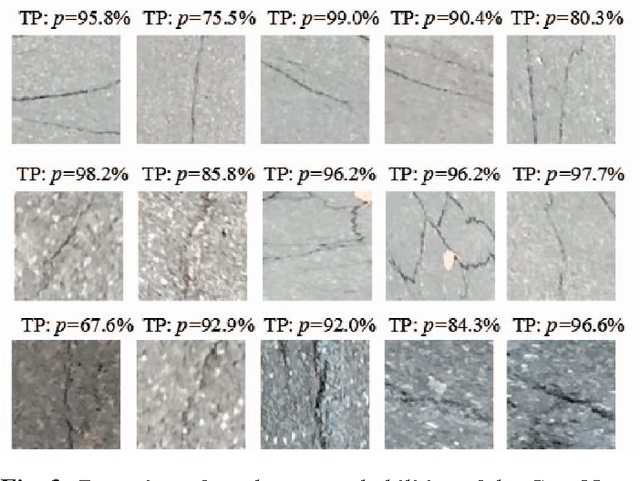
Crack is one of the most common road distresses which may pose road safety hazards. Generally, crack detection is performed by either certified inspectors or structural engineers. This task is, however, time-consuming, subjective and labor-intensive. In this paper, we propose a novel road crack detection algorithm based on deep learning and adaptive image segmentation. Firstly, a deep convolutional neural network is trained to determine whether an image contains cracks or not. The images containing cracks are then smoothed using bilateral filtering, which greatly minimizes the number of noisy pixels. Finally, we utilize an adaptive thresholding method to extract the cracks from road surface. The experimental results illustrate that our network can classify images with an accuracy of 99.92%, and the cracks can be successfully extracted from the images using our proposed thresholding algorithm.
Real-Time Stereo Vision for Road Surface 3-D Reconstruction
Aug 29, 2018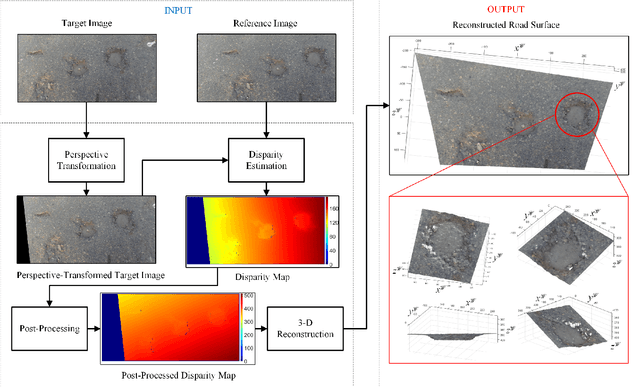

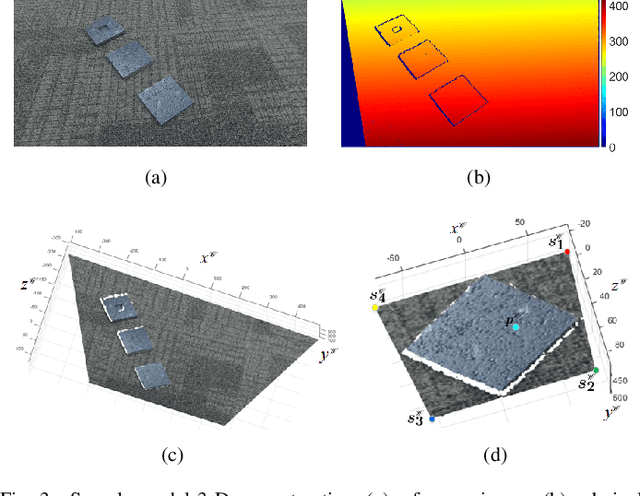
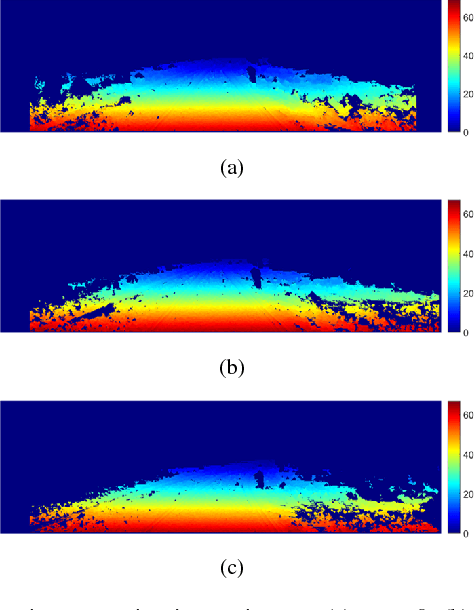
Stereo vision techniques have been widely used in civil engineering to acquire 3-D road data. The two important factors of stereo vision are accuracy and speed. However, it is very challenging to achieve both of them simultaneously and therefore the main aim of developing a stereo vision system is to improve the trade-off between these two factors. In this paper, we present a real-time stereo vision system used for road surface 3-D reconstruction. The proposed system is developed from our previously published 3-D reconstruction algorithm where the perspective view of the target image is first transformed into the reference view, which not only increases the disparity accuracy but also improves the processing speed. Then, the correlation cost between each pair of blocks is computed and stored in two 3-D cost volumes. To adaptively aggregate the matching costs from neighbourhood systems, bilateral filtering is performed on the cost volumes. This greatly reduces the ambiguities during stereo matching and further improves the precision of the estimated disparities. Finally, the subpixel resolution is achieved by conducting a parabola interpolation and the subpixel disparity map is used to reconstruct the 3-D road surface. The proposed algorithm is implemented on an NVIDIA GTX 1080 GPU for the real-time purpose. The experimental results illustrate that the reconstruction accuracy is around 3 mm.
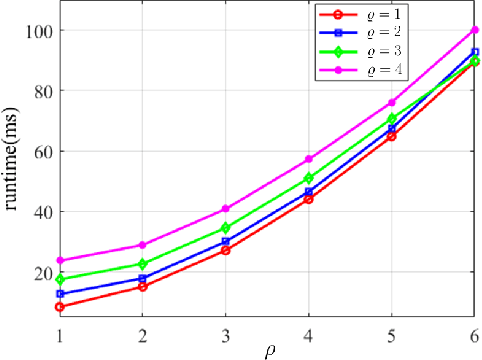
Multiple Lane Detection Algorithm Based on Optimised Dense Disparity Map Estimation
Aug 28, 2018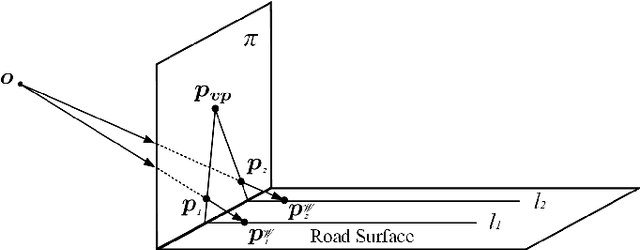
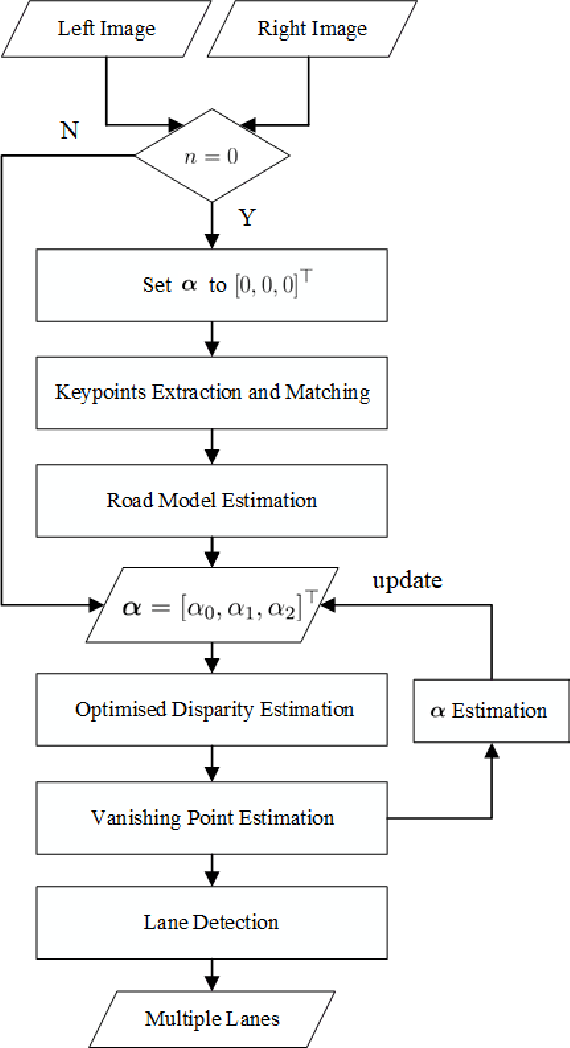

Lane detection is very important for self-driving vehicles. In recent years, computer stereo vision has been prevalently used to enhance the accuracy of the lane detection systems. This paper mainly presents a multiple lane detection algorithm developed based on optimised dense disparity map estimation, where the disparity information obtained at time t_{n} is utilised to optimise the process of disparity estimation at time t_{n+1}. This is achieved by estimating the road model at time t_{n} and then controlling the search range for the disparity estimation at time t_{n+1}. The lanes are then detected using our previously published algorithm, where the vanishing point information is used to model the lanes. The experimental results illustrate that the runtime of the disparity estimation is reduced by around 37% and the accuracy of the lane detection is about 99%.
Real-Time Subpixel Fast Bilateral Stereo
Aug 15, 2018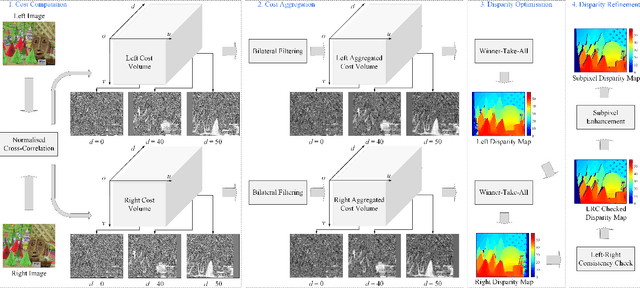
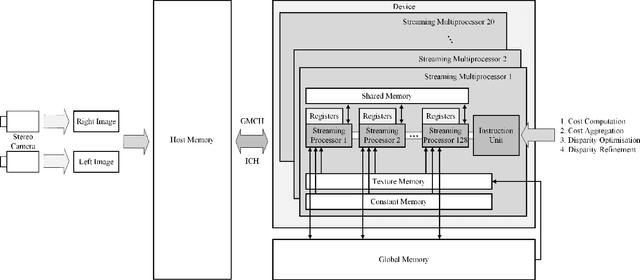
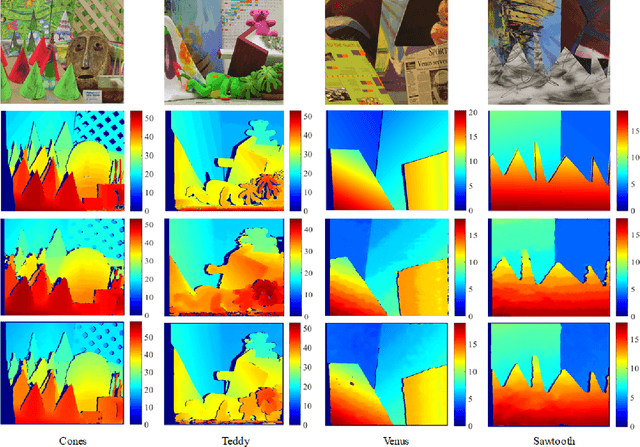
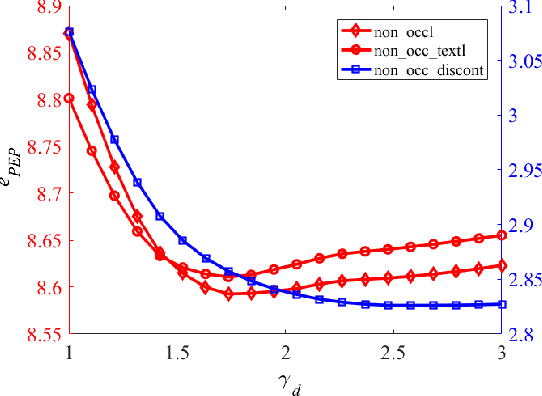
Stereo vision technique has been widely used in robotic systems to acquire 3-D information. In recent years, many researchers have applied bilateral filtering in stereo vision to adaptively aggregate the matching costs. This has greatly improved the accuracy of the estimated disparity maps. However, the process of filtering the whole cost volume is very time consuming and therefore the researchers have to resort to some powerful hardware for the real-time purpose. This paper presents the implementation of fast bilateral stereo on a state-of-the-art GPU. By highly exploiting the parallel computing architecture of the GPU, the fast bilateral stereo performs in real time when processing the Middlebury stereo datasets.
A Novel Disparity Transformation Algorithm for Road Segmentation
Aug 08, 2018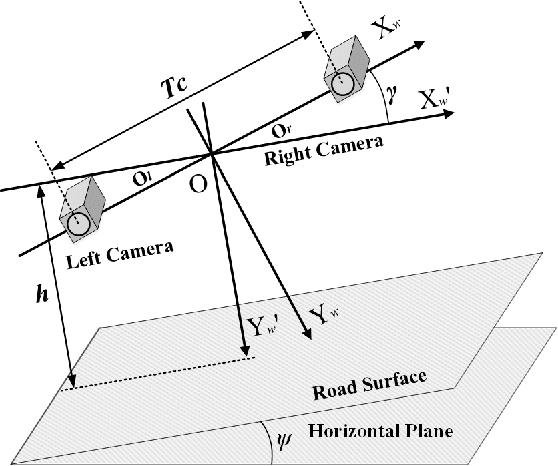
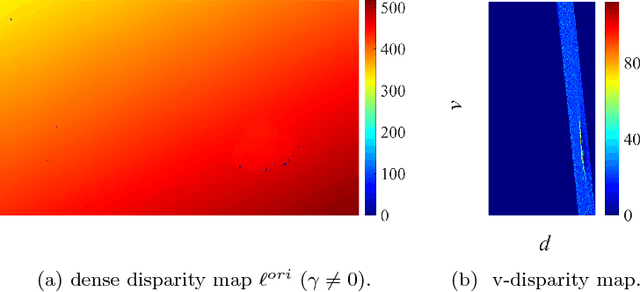


The disparity information provided by stereo cameras has enabled advanced driver assistance systems to estimate road area more accurately and effectively. In this paper, a novel disparity transformation algorithm is proposed to extract road areas from dense disparity maps by making the disparity value of the road pixels become similar. The transformation is achieved using two parameters: roll angle and fitted disparity value with respect to each row. To achieve a better processing efficiency, golden section search and dynamic programming are utilised to estimate the roll angle and the fitted disparity value, respectively. By performing a rotation around the estimated roll angle, the disparity distribution of each row becomes very compact. This further improves the accuracy of the road model estimation, as demonstrated by the various experimental results in this paper. Finally, the Otsu's thresholding method is applied to the transformed disparity map and the roads can be accurately segmented at pixel level.