 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Collision-Free Space Detection from Stereo Images: Homography Matrix Brings Better Data Augmentation
Paper and Code
Dec 14, 2020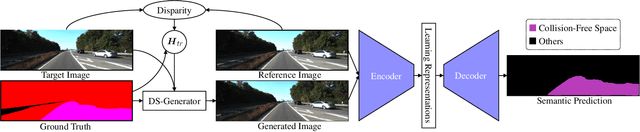
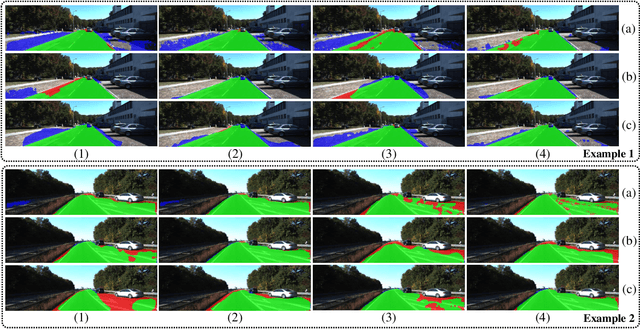

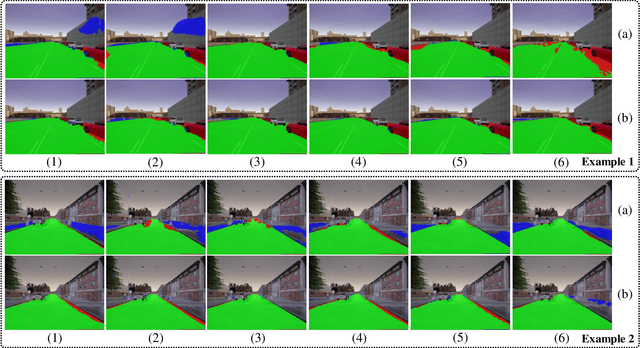
Collision-free space detection is a critical component of autonomous vehicle perception. The state-of-the-art algorithms are typically based on supervised learning. The performance of such approaches is always dependent on the quality and amount of labeled training data. Additionally, it remains an open challenge to train deep convolutional neural networks (DCNNs) using only a small quantity of training samples. Therefore, this paper mainly explores an effective training data augmentation approach that can be employed to improve the overall DCNN performance, when additional images captured from different views are available. Due to the fact that the pixels of the collision-free space (generally regarded as a planar surface) between two images captured from different views can be associated by a homography matrix, the scenario of the target image can be transformed into the reference view. This provides a simple but effective way of generating training data from additional multi-view images. Extensive experimental results, conducted with six state-of-the-art semantic segmentation DCNNs on three datasets, demonstrate the effectiveness of our proposed training data augmentation algorithm for enhancing collision-free space detection performance. When validated on the KITTI road benchmark, our approach provides the best results for stereo vision-based collision-free space detection.