 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInfinite-Instruct: Synthesizing Scaling Code instruction Data with Bidirectional Synthesis and Static Verification
May 29, 2025Traditional code instruction data synthesis methods suffer from limited diversity and poor logic. We introduce Infinite-Instruct, an automated framework for synthesizing high-quality question-answer pairs, designed to enhance the code generation capabilities of large language models (LLMs). The framework focuses on improving the internal logic of synthesized problems and the quality of synthesized code. First, "Reverse Construction" transforms code snippets into diverse programming problems. Then, through "Backfeeding Construction," keywords in programming problems are structured into a knowledge graph to reconstruct them into programming problems with stronger internal logic. Finally, a cross-lingual static code analysis pipeline filters invalid samples to ensure data quality. Experiments show that on mainstream code generation benchmarks, our fine-tuned models achieve an average performance improvement of 21.70% on 7B-parameter models and 36.95% on 32B-parameter models. Using less than one-tenth of the instruction fine-tuning data, we achieved performance comparable to the Qwen-2.5-Coder-Instruct. Infinite-Instruct provides a scalable solution for LLM training in programming. We open-source the datasets used in the experiments, including both unfiltered versions and filtered versions via static analysis. The data are available at https://github.com/xingwenjing417/Infinite-Instruct-dataset
LCSim: A Large-Scale Controllable Traffic Simulator
Jun 28, 2024
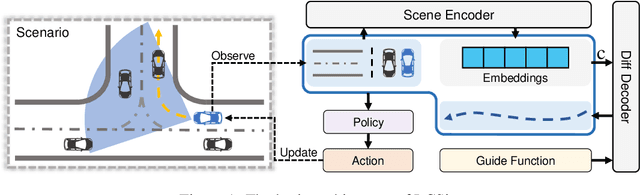


With the rapid development of urban transportation and the continuous advancement in autonomous vehicles, the demand for safely and efficiently testing autonomous driving and traffic optimization algorithms arises, which needs accurate modeling of large-scale urban traffic scenarios. Existing traffic simulation systems encounter two significant limitations. Firstly, they often rely on open-source datasets or manually crafted maps, constraining the scale of simulations. Secondly, vehicle models within these systems tend to be either oversimplified or lack controllability, compromising the authenticity and diversity of the simulations. In this paper, we propose LCSim, a large-scale controllable traffic simulator. LCSim provides map tools for constructing unified high-definition map (HD map) descriptions from open-source datasets including Waymo and Argoverse or publicly available data sources like OpenStreetMap to scale up the simulation scenarios. Also, we integrate diffusion-based traffic simulation into the simulator for realistic and controllable microscopic traffic flow modeling. By leveraging these features, LCSim provides realistic and diverse virtual traffic environments. Code and Demos are available at https://github.com/tsinghua-fib-lab/LCSim.
HoloVIC: Large-scale Dataset and Benchmark for Multi-Sensor Holographic Intersection and Vehicle-Infrastructure Cooperative
Mar 06, 2024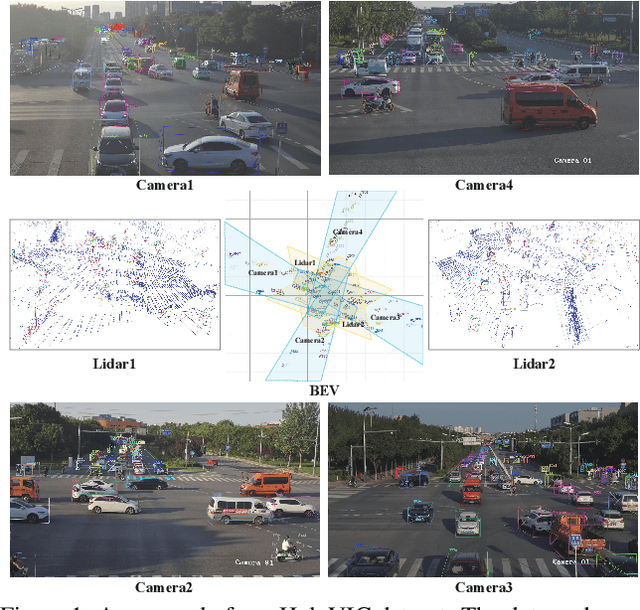
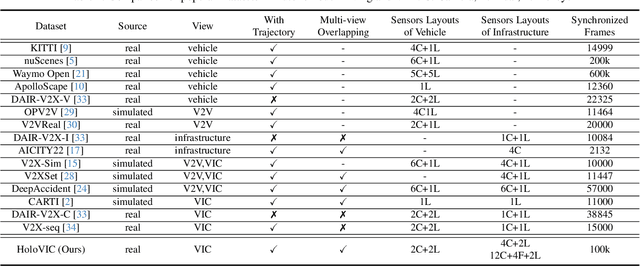
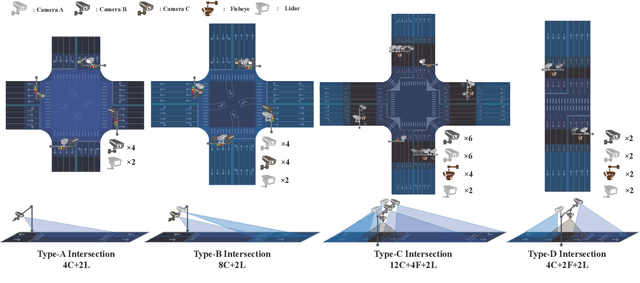
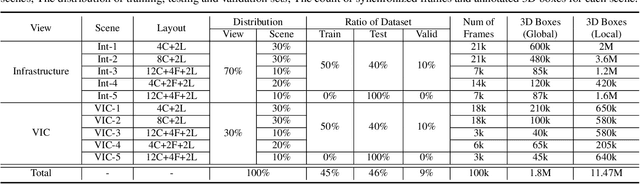
Vehicle-to-everything (V2X) is a popular topic in the field of Autonomous Driving in recent years. Vehicle-infrastructure cooperation (VIC) becomes one of the important research area. Due to the complexity of traffic conditions such as blind spots and occlusion, it greatly limits the perception capabilities of single-view roadside sensing systems. To further enhance the accuracy of roadside perception and provide better information to the vehicle side, in this paper, we constructed holographic intersections with various layouts to build a large-scale multi-sensor holographic vehicle-infrastructure cooperation dataset, called HoloVIC. Our dataset includes 3 different types of sensors (Camera, Lidar, Fisheye) and employs 4 sensor-layouts based on the different intersections. Each intersection is equipped with 6-18 sensors to capture synchronous data. While autonomous vehicles pass through these intersections for collecting VIC data. HoloVIC contains in total on 100k+ synchronous frames from different sensors. Additionally, we annotated 3D bounding boxes based on Camera, Fisheye, and Lidar. We also associate the IDs of the same objects across different devices and consecutive frames in sequence. Based on HoloVIC, we formulated four tasks to facilitate the development of related research. We also provide benchmarks for these tasks.
Unsupervised Learning of Accurate Siamese Tracking
Apr 04, 2022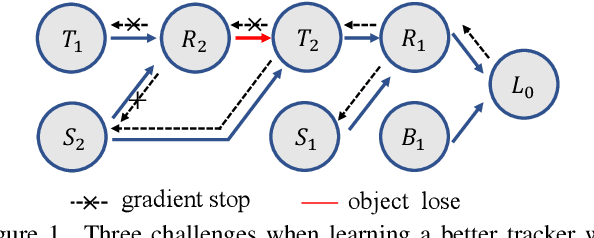
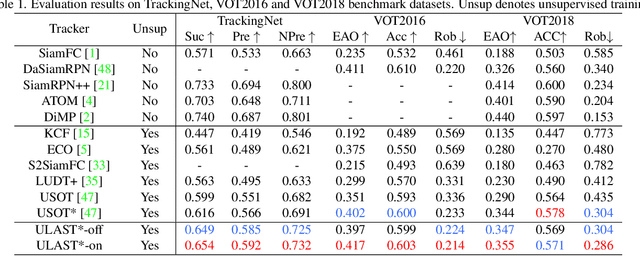
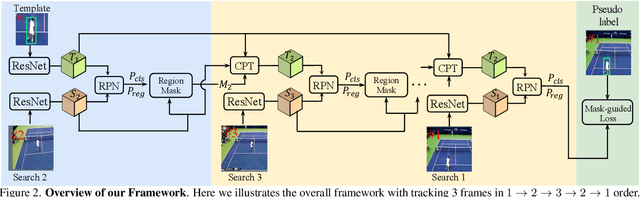
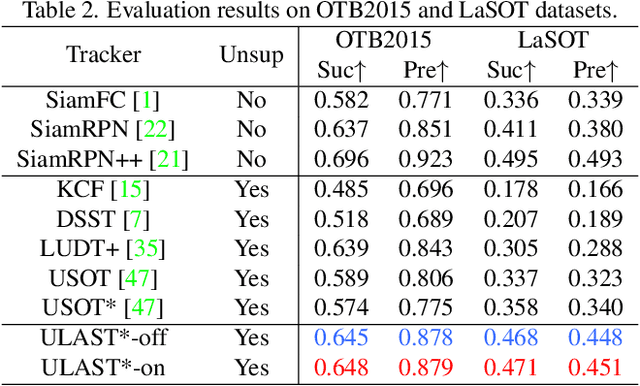
Unsupervised learning has been popular in various computer vision tasks, including visual object tracking. However, prior unsupervised tracking approaches rely heavily on spatial supervision from template-search pairs and are still unable to track objects with strong variation over a long time span. As unlimited self-supervision signals can be obtained by tracking a video along a cycle in time, we investigate evolving a Siamese tracker by tracking videos forward-backward. We present a novel unsupervised tracking framework, in which we can learn temporal correspondence both on the classification branch and regression branch. Specifically, to propagate reliable template feature in the forward propagation process so that the tracker can be trained in the cycle, we first propose a consistency propagation transformation. We then identify an ill-posed penalty problem in conventional cycle training in backward propagation process. Thus, a differentiable region mask is proposed to select features as well as to implicitly penalize tracking errors on intermediate frames. Moreover, since noisy labels may degrade training, we propose a mask-guided loss reweighting strategy to assign dynamic weights based on the quality of pseudo labels. In extensive experiments, our tracker outperforms preceding unsupervised methods by a substantial margin, performing on par with supervised methods on large-scale datasets such as TrackingNet and LaSOT. Code is available at https://github.com/FlorinShum/ULAST.
Backbone is All Your Need: A Simplified Architecture for Visual Object Tracking
Mar 10, 2022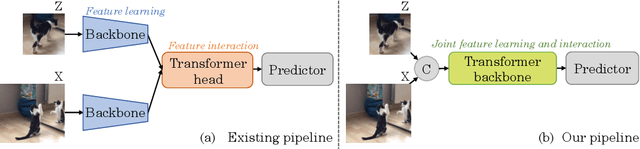
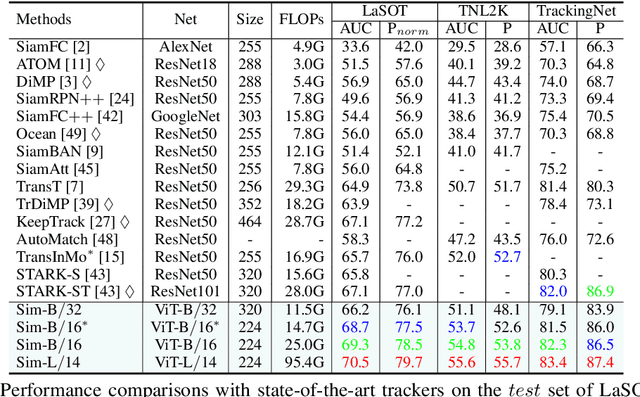
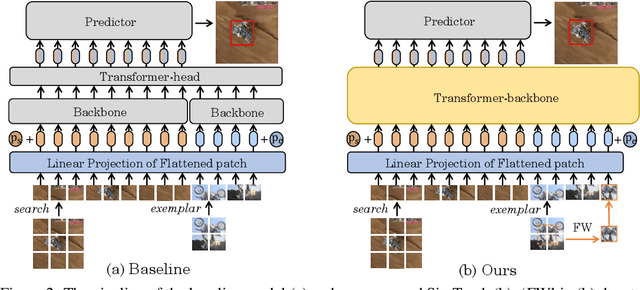
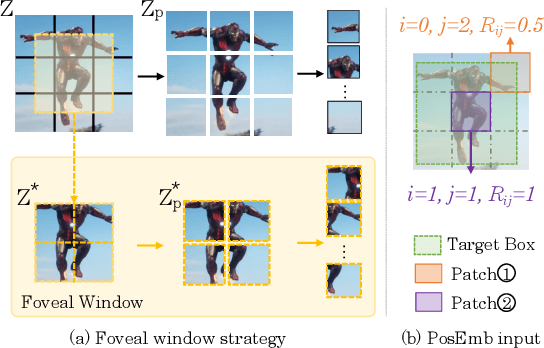
Exploiting a general-purpose neural architecture to replace hand-wired designs or inductive biases has recently drawn extensive interest. However, existing tracking approaches rely on customized sub-modules and need prior knowledge for architecture selection, hindering the tracking development in a more general system. This paper presents a Simplified Tracking architecture (SimTrack) by leveraging a transformer backbone for joint feature extraction and interaction. Unlike existing Siamese trackers, we serialize the input images and concatenate them directly before the one-branch backbone. Feature interaction in the backbone helps to remove well-designed interaction modules and produce a more efficient and effective framework. To reduce the information loss from down-sampling in vision transformers, we further propose a foveal window strategy, providing more diverse input patches with acceptable computational costs. Our SimTrack improves the baseline with 2.5%/2.6% AUC gains on LaSOT/TNL2K and gets results competitive with other specialized tracking algorithms without bells and whistles.
Higher Performance Visual Tracking with Dual-Modal Localization
Mar 18, 2021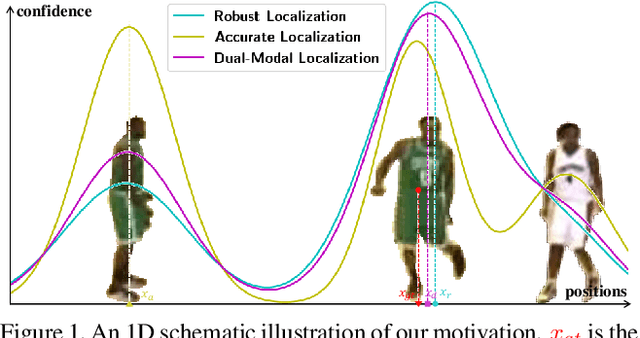

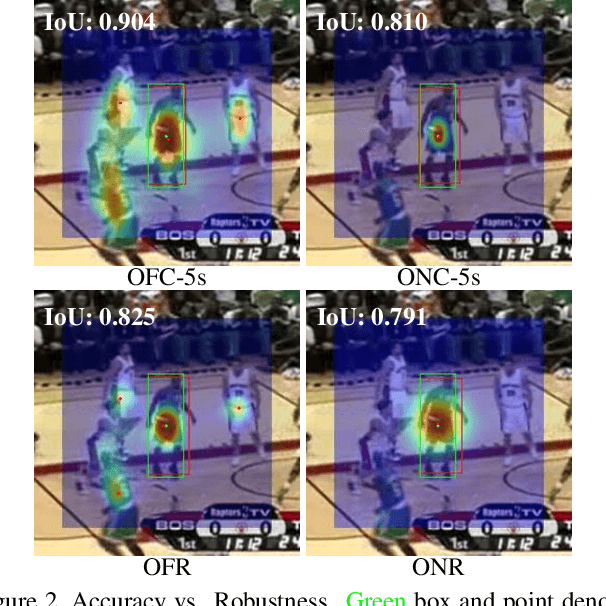
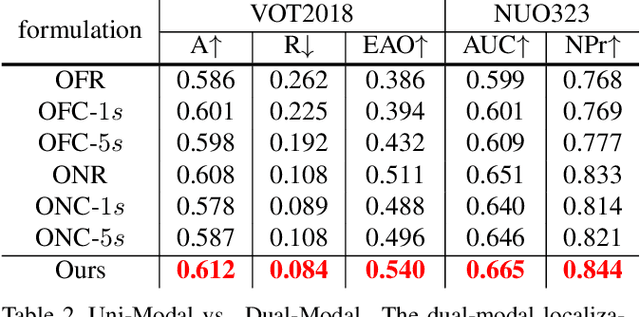
Visual Object Tracking (VOT) has synchronous needs for both robustness and accuracy. While most existing works fail to operate simultaneously on both, we investigate in this work the problem of conflicting performance between accuracy and robustness. We first conduct a systematic comparison among existing methods and analyze their restrictions in terms of accuracy and robustness. Specifically, 4 formulations-offline classification (OFC), offline regression (OFR), online classification (ONC), and online regression (ONR)-are considered, categorized by the existence of online update and the types of supervision signal. To account for the problem, we resort to the idea of ensemble and propose a dual-modal framework for target localization, consisting of robust localization suppressing distractors via ONR and the accurate localization attending to the target center precisely via OFC. To yield a final representation (i.e, bounding box), we propose a simple but effective score voting strategy to involve adjacent predictions such that the final representation does not commit to a single location. Operating beyond the real-time demand, our proposed method is further validated on 8 datasets-VOT2018, VOT2019, OTB2015, NFS, UAV123, LaSOT, TrackingNet, and GOT-10k, achieving state-of-the-art performance.
STUaNet: Understanding uncertainty in spatiotemporal collective human mobility
Feb 09, 2021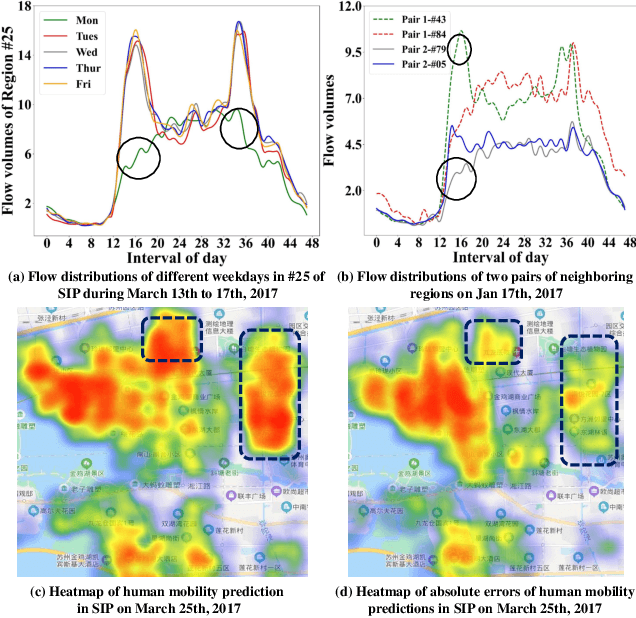
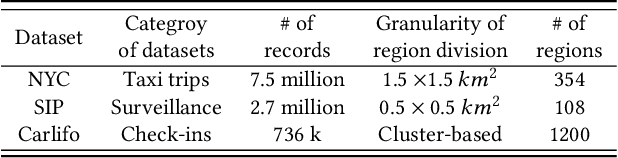
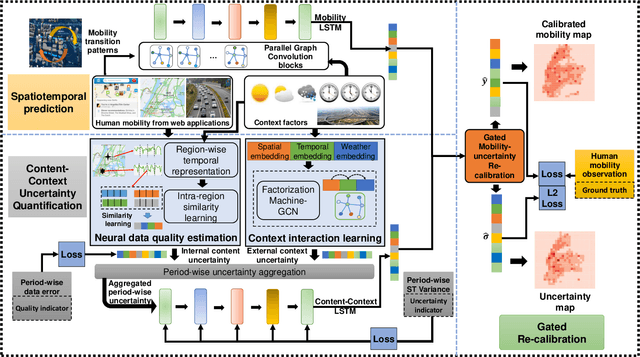
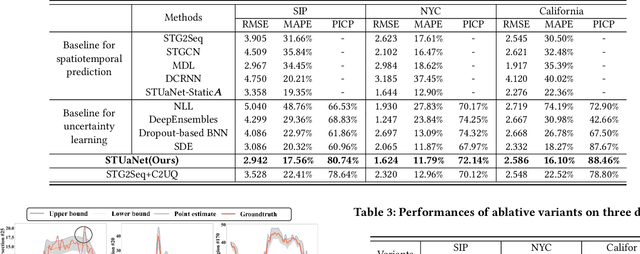
The high dynamics and heterogeneous interactions in the complicated urban systems have raised the issue of uncertainty quantification in spatiotemporal human mobility, to support critical decision-makings in risk-aware web applications such as urban event prediction where fluctuations are of significant interests. Given the fact that uncertainty quantifies the potential variations around prediction results, traditional learning schemes always lack uncertainty labels, and conventional uncertainty quantification approaches mostly rely upon statistical estimations with Bayesian Neural Networks or ensemble methods. However, they have never involved any spatiotemporal evolution of uncertainties under various contexts, and also have kept suffering from the poor efficiency of statistical uncertainty estimation while training models with multiple times. To provide high-quality uncertainty quantification for spatiotemporal forecasting, we propose an uncertainty learning mechanism to simultaneously estimate internal data quality and quantify external uncertainty regarding various contextual interactions. To address the issue of lacking labels of uncertainty, we propose a hierarchical data turbulence scheme where we can actively inject controllable uncertainty for guidance, and hence provide insights to both uncertainty quantification and weak supervised learning. Finally, we re-calibrate and boost the prediction performance by devising a gated-based bridge to adaptively leverage the learned uncertainty into predictions. Extensive experiments on three real-world spatiotemporal mobility sets have corroborated the superiority of our proposed model in terms of both forecasting and uncertainty quantification.
Learning Collision-Free Space Detection from Stereo Images: Homography Matrix Brings Better Data Augmentation
Dec 14, 2020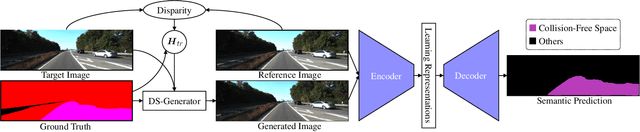
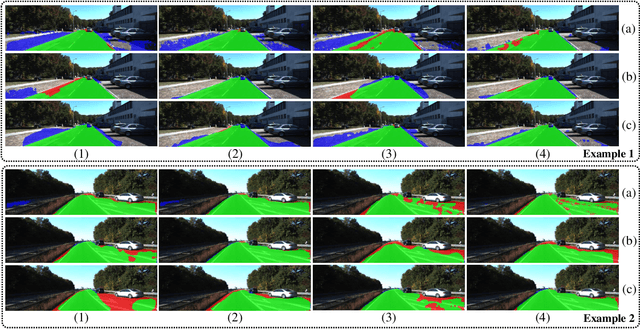

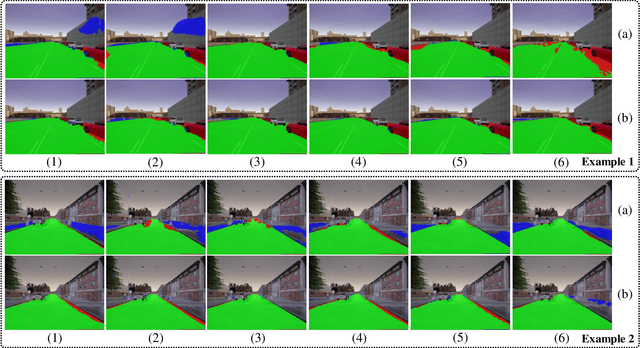
Collision-free space detection is a critical component of autonomous vehicle perception. The state-of-the-art algorithms are typically based on supervised learning. The performance of such approaches is always dependent on the quality and amount of labeled training data. Additionally, it remains an open challenge to train deep convolutional neural networks (DCNNs) using only a small quantity of training samples. Therefore, this paper mainly explores an effective training data augmentation approach that can be employed to improve the overall DCNN performance, when additional images captured from different views are available. Due to the fact that the pixels of the collision-free space (generally regarded as a planar surface) between two images captured from different views can be associated by a homography matrix, the scenario of the target image can be transformed into the reference view. This provides a simple but effective way of generating training data from additional multi-view images. Extensive experimental results, conducted with six state-of-the-art semantic segmentation DCNNs on three datasets, demonstrate the effectiveness of our proposed training data augmentation algorithm for enhancing collision-free space detection performance. When validated on the KITTI road benchmark, our approach provides the best results for stereo vision-based collision-free space detection.
ORBBuf: A Robust Buffering Method for Collaborative Visual SLAM
Oct 28, 2020

Collaborative simultaneous localization and mapping (SLAM) approaches provide a solution for autonomous robots based on embedded devices. On the other hand, visual SLAM systems rely on correlations between visual frames. As a result, the loss of visual frames from an unreliable wireless network can easily damage the results of collaborative visual SLAM systems. From our experiment, a loss of less than 1 second of data can lead to the failure of visual SLAM algorithms. We present a novel buffering method, ORBBuf, to reduce the impact of data loss on collaborative visual SLAM systems. We model the buffering problem into an optimization problem. We use an efficient greedy-like algorithm, and our buffering method drops the frame that results in the least loss to the quality of the SLAM results. We implement our ORBBuf method on ROS, a widely used middleware framework. Through an extensive evaluation on real-world scenarios and tens of gigabytes of datasets, we demonstrate that our ORBBuf method can be applied to different algorithms, different sensor data (both monocular images and stereo images), different scenes (both indoor and outdoor), and different network environments (both WiFi networks and 4G networks). Experimental results show that the network interruptions indeed affect the SLAM results, and our ORBBuf method can reduce the RMSE up to 50 times.
Autonomous UAV Landing System Based on Visual Navigation
Oct 29, 2019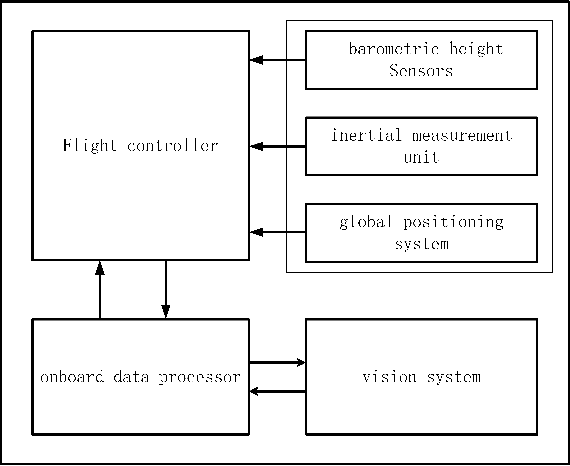

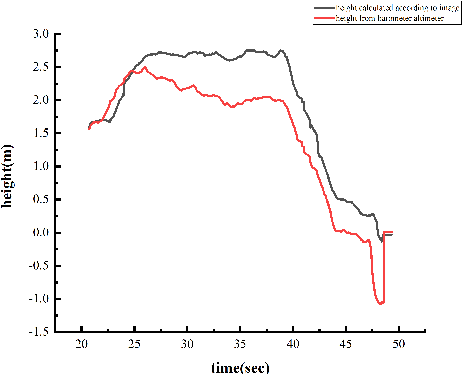
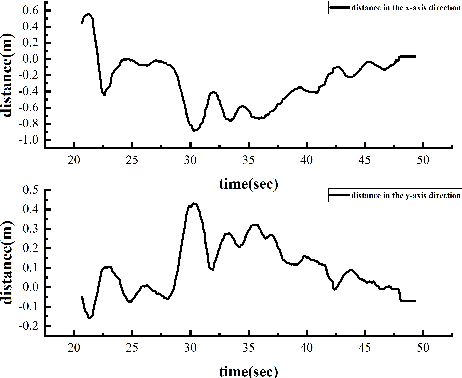
In this paper, we present an autonomous unmanned aerial vehicle (UAV) landing system based on visual navigation. We design the landmark as a topological pattern in order to enable the UAV to distinguish the landmark from the environment easily. In addition, a dynamic thresholding method is developed for image binarization to improve detection efficiency. The relative distance in the horizontal plane is calculated according to effective image information, and the relative height is obtained using a linear interpolation method. The landing experiments are performed on a static and a moving platform, respectively. The experimental results illustrate that our proposed landing system performs robustly and accurately.