 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Graph Foundation Models on Riemannian Graph-of-Graphs
May 11, 2026Graph foundation models (GFMs), pretrained on massive graph data, have transformed graph machine learning by supporting general-purpose reasoning across diverse graph tasks and domains. Existing GFMs pretrained with fixed-hop subgraph sampling impose a fixed receptive field, causing scale mismatch on diverse tasks, which often require heterogeneous and unknown structural contexts beyond a fixed sampling scale. We propose R-GFM, a Riemannian Graph-of-Graphs (GoG) based foundation model, that treats structural scale as a first-class citizen in modeling. R-GFM constructs a multi-scale GoG over-sampled subgraphs at different hop distances and learns geometry-adaptive representations from Riemannian manifolds. Theoretical analysis shows that R-GFM reduces structural domain generalization error compared to fixed-scale GFMs. Experiments on various datasets demonstrate that R-GFM achieves state-of-the-art performance, with up to a 49% relative improvement on downstream tasks. Our code is available at https://github.com/USTC-DataDarknessLab/R-GFM.
KG-ViP: Bridging Knowledge Grounding and Visual Perception in Multi-modal LLMs for Visual Question Answering
Jan 14, 2026Multi-modal Large Language Models (MLLMs) for Visual Question Answering (VQA) often suffer from dual limitations: knowledge hallucination and insufficient fine-grained visual perception. Crucially, we identify that commonsense graphs and scene graphs provide precisely complementary solutions to these respective deficiencies by providing rich external knowledge and capturing fine-grained visual details. However, prior works typically treat them in isolation, overlooking their synergistic potential. To bridge this gap, we propose KG-ViP, a unified framework that empowers MLLMs by fusing scene graphs and commonsense graphs. The core of the KG-ViP framework is a novel retrieval-and-fusion pipeline that utilizes the query as a semantic bridge to progressively integrate both graphs, synthesizing a unified structured context that facilitates reliable multi-modal reasoning. Extensive experiments on FVQA 2.0+ and MVQA benchmarks demonstrate that KG-ViP significantly outperforms existing VQA methods.
SkewRoute: Training-Free LLM Routing for Knowledge Graph Retrieval-Augmented Generation via Score Skewness of Retrieved Context
May 28, 2025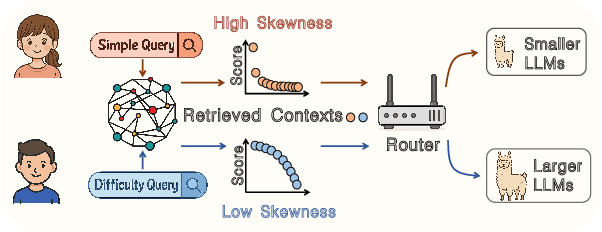
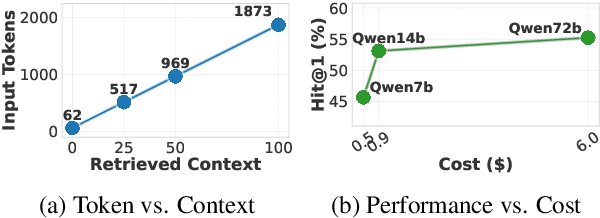

Large language models excel at many tasks but often incur high inference costs during deployment. To mitigate hallucination, many systems use a knowledge graph to enhance retrieval-augmented generation (KG-RAG). However, the large amount of retrieved knowledge contexts increase these inference costs further. A promising solution to balance performance and cost is LLM routing, which directs simple queries to smaller LLMs and complex ones to larger LLMs. However, no dedicated routing methods currently exist for RAG, and existing training-based routers face challenges scaling to this domain due to the need for extensive training data. We observe that the score distributions produced by the retrieval scorer strongly correlate with query difficulty. Based on this, we propose a novel, training-free routing framework, the first tailored to KG-RAG that effectively balances performance and cost in a plug-and-play manner. Experiments show our method reduces calls to larger LLMs by up to 50% without sacrificing response quality, demonstrating its potential for efficient and scalable LLM deployment.
Lego Sketch: A Scalable Memory-augmented Neural Network for Sketching Data Streams
May 26, 2025Sketches, probabilistic structures for estimating item frequencies in infinite data streams with limited space, are widely used across various domains. Recent studies have shifted the focus from handcrafted sketches to neural sketches, leveraging memory-augmented neural networks (MANNs) to enhance the streaming compression capabilities and achieve better space-accuracy trade-offs.However, existing neural sketches struggle to scale across different data domains and space budgets due to inflexible MANN configurations. In this paper, we introduce a scalable MANN architecture that brings to life the {\it Lego sketch}, a novel sketch with superior scalability and accuracy. Much like assembling creations with modular Lego bricks, the Lego sketch dynamically coordinates multiple memory bricks to adapt to various space budgets and diverse data domains. Our theoretical analysis guarantees its high scalability and provides the first error bound for neural sketch. Furthermore, extensive experimental evaluations demonstrate that the Lego sketch exhibits superior space-accuracy trade-offs, outperforming existing handcrafted and neural sketches. Our code is available at https://github.com/FFY0/LegoSketch_ICML.
SDD-4DGS: Static-Dynamic Aware Decoupling in Gaussian Splatting for 4D Scene Reconstruction
Mar 12, 2025Dynamic and static components in scenes often exhibit distinct properties, yet most 4D reconstruction methods treat them indiscriminately, leading to suboptimal performance in both cases. This work introduces SDD-4DGS, the first framework for static-dynamic decoupled 4D scene reconstruction based on Gaussian Splatting. Our approach is built upon a novel probabilistic dynamic perception coefficient that is naturally integrated into the Gaussian reconstruction pipeline, enabling adaptive separation of static and dynamic components. With carefully designed implementation strategies to realize this theoretical framework, our method effectively facilitates explicit learning of motion patterns for dynamic elements while maintaining geometric stability for static structures. Extensive experiments on five benchmark datasets demonstrate that SDD-4DGS consistently outperforms state-of-the-art methods in reconstruction fidelity, with enhanced detail restoration for static structures and precise modeling of dynamic motions. The code will be released.
Path Pooling: Train-Free Structure Enhancement for Efficient Knowledge Graph Retrieval-Augmented Generation
Mar 07, 2025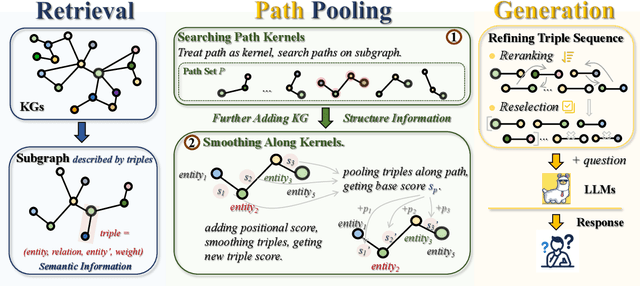
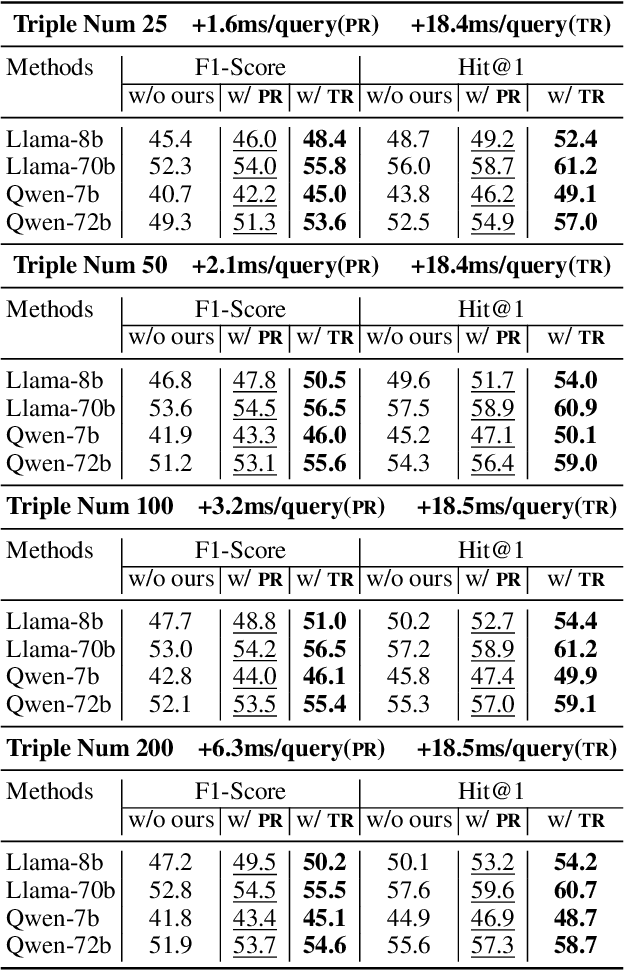
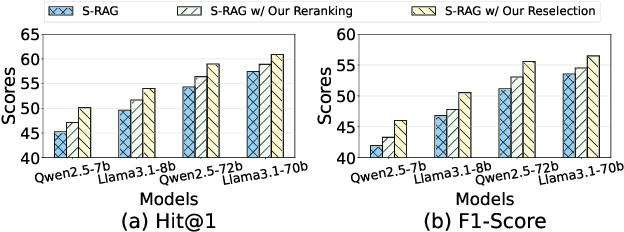

Although Large Language Models achieve strong success in many tasks, they still suffer from hallucinations and knowledge deficiencies in real-world applications. Many knowledge graph-based retrieval-augmented generation (KG-RAG) methods enhance the quality and credibility of LLMs by leveraging structure and semantic information in KGs as external knowledge bases. However, these methods struggle to effectively incorporate structure information, either incurring high computational costs or underutilizing available knowledge. Inspired by smoothing operations in graph representation learning, we propose path pooling, a simple, train-free strategy that introduces structure information through a novel path-centric pooling operation. It seamlessly integrates into existing KG-RAG methods in a plug-and-play manner, enabling richer structure information utilization. Extensive experiments demonstrate that incorporating the path pooling into the state-of-the-art KG-RAG method consistently improves performance across various settings while introducing negligible additional cost. Code is coming soon at https://github.com/hrwang00/path-pooling.
Identify Critical KV Cache in LLM Inference from an Output Perturbation Perspective
Feb 06, 2025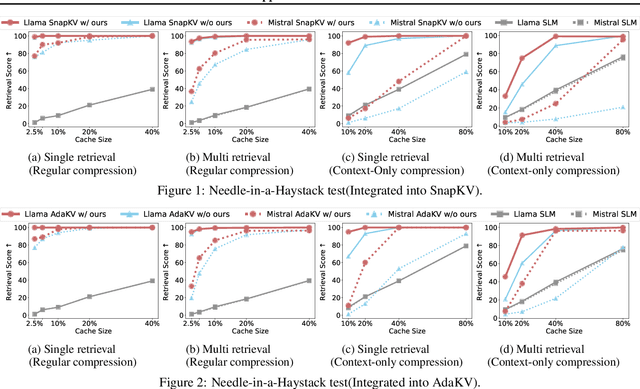
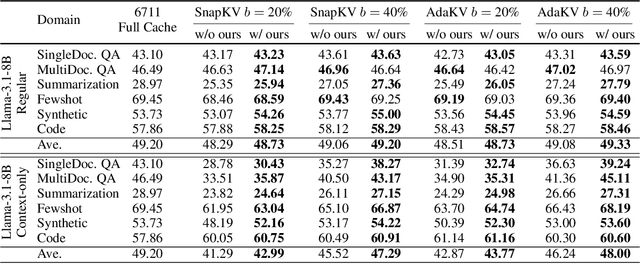
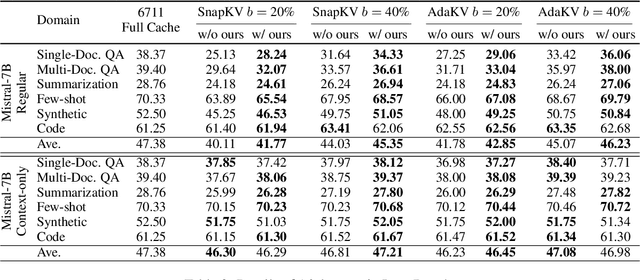
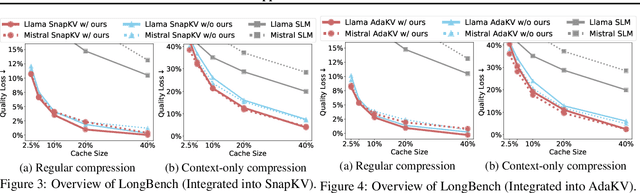
Large language models have revolutionized natural language processing but face significant challenges of high storage and runtime costs, due to the transformer architecture's reliance on self-attention, particularly the large Key-Value (KV) cache for long-sequence inference. Recent efforts to reduce KV cache size by pruning less critical entries based on attention weights remain empirical and lack formal grounding. This paper presents a formal study on identifying critical KV cache entries by analyzing attention output perturbation. Our analysis reveals that, beyond attention weights, the value states within KV entries and pretrained parameter matrices are also crucial. Based on this, we propose a perturbation-constrained selection algorithm that optimizes the worst-case output perturbation to identify critical entries. Evaluations on the Needle-in-a-Haystack test and Longbench benchmark show our algorithm enhances state-of-the-art cache eviction methods. Further empirical analysis confirms that our algorithm achieves lower output perturbations in over 92% attention heads in Llama model, thereby providing a significant improvement over existing methods.
FRAG: A Flexible Modular Framework for Retrieval-Augmented Generation based on Knowledge Graphs
Jan 17, 2025



To mitigate the hallucination and knowledge deficiency in large language models (LLMs), Knowledge Graph (KG)-based Retrieval-Augmented Generation (RAG) has shown promising potential by utilizing KGs as external resource to enhance LLMs reasoning.However, existing KG-RAG approaches struggle with a trade-off between flexibility and retrieval quality.Modular methods prioritize flexibility by avoiding the use of KG-fine-tuned models during retrieval, leading to fixed retrieval strategies and suboptimal retrieval quality.Conversely, coupled methods embed KG information within models to improve retrieval quality, but at the expense of flexibility.In this paper, we propose a novel flexible modular KG-RAG framework, termed FRAG, which synergizes the advantages of both approaches.FRAG estimates the hop range of reasoning paths based solely on the query and classify it as either simple or complex.To match the complexity of the query, tailored pipelines are applied to ensure efficient and accurate reasoning path retrieval, thus fostering the final reasoning process.By using the query text instead of the KG to infer the structural information of reasoning paths and employing adaptable retrieval strategies, FRAG improves retrieval quality while maintaining flexibility.Moreover, FRAG does not require extra LLMs fine-tuning or calls, significantly boosting efficiency and conserving resources.Extensive experiments show that FRAG achieves state-of-the-art performance with high efficiency and low resource consumption.
Prototype-based Optimal Transport for Out-of-Distribution Detection
Oct 10, 2024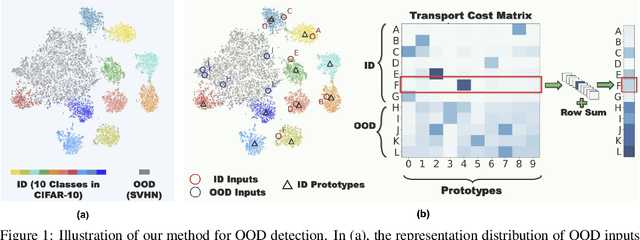
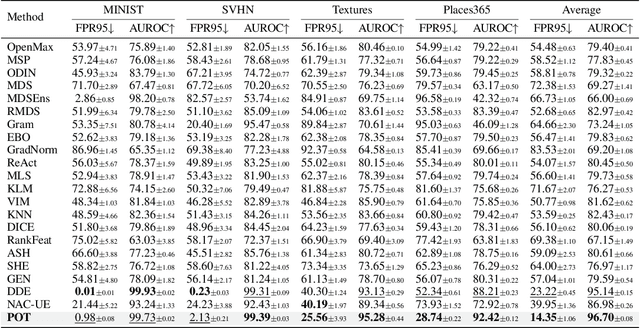

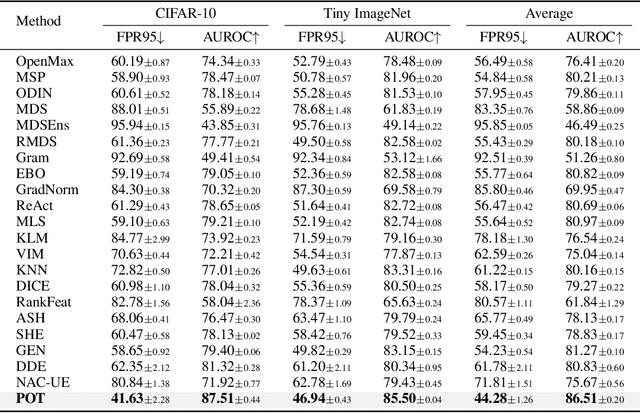
Detecting Out-of-Distribution (OOD) inputs is crucial for improving the reliability of deep neural networks in the real-world deployment. In this paper, inspired by the inherent distribution shift between ID and OOD data, we propose a novel method that leverages optimal transport to measure the distribution discrepancy between test inputs and ID prototypes. The resulting transport costs are used to quantify the individual contribution of each test input to the overall discrepancy, serving as a desirable measure for OOD detection. To address the issue that solely relying on the transport costs to ID prototypes is inadequate for identifying OOD inputs closer to ID data, we generate virtual outliers to approximate the OOD region via linear extrapolation. By combining the transport costs to ID prototypes with the costs to virtual outliers, the detection of OOD data near ID data is emphasized, thereby enhancing the distinction between ID and OOD inputs. Experiments demonstrate the superiority of our method over state-of-the-art methods.
GraphInsight: Unlocking Insights in Large Language Models for Graph Structure Understanding
Sep 05, 2024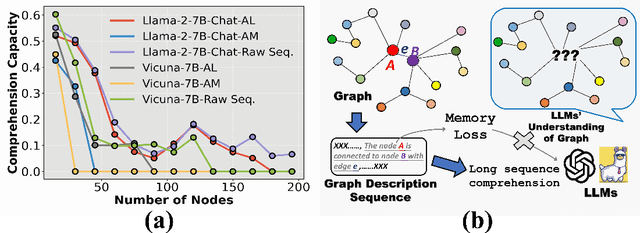
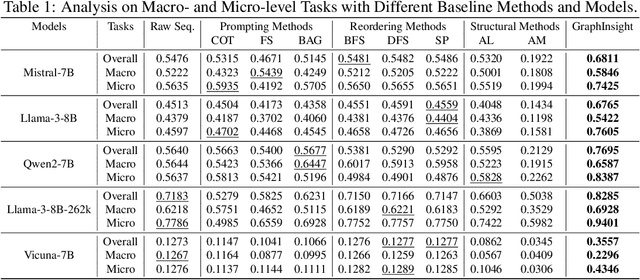
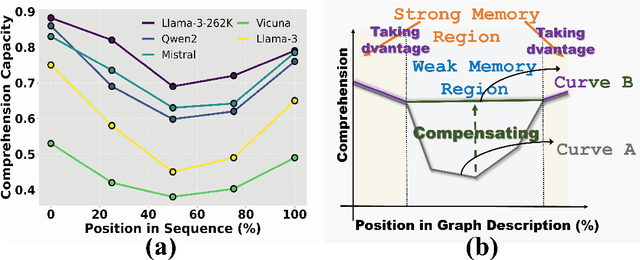
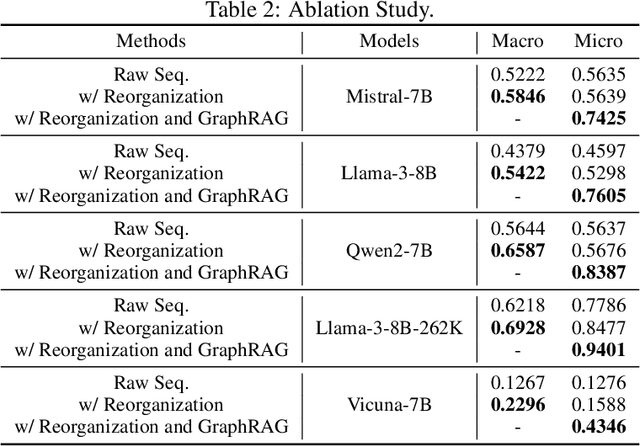
Although Large Language Models (LLMs) have demonstrated potential in processing graphs, they struggle with comprehending graphical structure information through prompts of graph description sequences, especially as the graph size increases. We attribute this challenge to the uneven memory performance of LLMs across different positions in graph description sequences, known as ''positional biases''. To address this, we propose GraphInsight, a novel framework aimed at improving LLMs' comprehension of both macro- and micro-level graphical information. GraphInsight is grounded in two key strategies: 1) placing critical graphical information in positions where LLMs exhibit stronger memory performance, and 2) investigating a lightweight external knowledge base for regions with weaker memory performance, inspired by retrieval-augmented generation (RAG). Moreover, GraphInsight explores integrating these two strategies into LLM agent processes for composite graph tasks that require multi-step reasoning. Extensive empirical studies on benchmarks with a wide range of evaluation tasks show that GraphInsight significantly outperforms all other graph description methods (e.g., prompting techniques and reordering strategies) in understanding graph structures of varying sizes.