 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKG-ViP: Bridging Knowledge Grounding and Visual Perception in Multi-modal LLMs for Visual Question Answering
Jan 14, 2026Multi-modal Large Language Models (MLLMs) for Visual Question Answering (VQA) often suffer from dual limitations: knowledge hallucination and insufficient fine-grained visual perception. Crucially, we identify that commonsense graphs and scene graphs provide precisely complementary solutions to these respective deficiencies by providing rich external knowledge and capturing fine-grained visual details. However, prior works typically treat them in isolation, overlooking their synergistic potential. To bridge this gap, we propose KG-ViP, a unified framework that empowers MLLMs by fusing scene graphs and commonsense graphs. The core of the KG-ViP framework is a novel retrieval-and-fusion pipeline that utilizes the query as a semantic bridge to progressively integrate both graphs, synthesizing a unified structured context that facilitates reliable multi-modal reasoning. Extensive experiments on FVQA 2.0+ and MVQA benchmarks demonstrate that KG-ViP significantly outperforms existing VQA methods.
FRAG: A Flexible Modular Framework for Retrieval-Augmented Generation based on Knowledge Graphs
Jan 17, 2025



To mitigate the hallucination and knowledge deficiency in large language models (LLMs), Knowledge Graph (KG)-based Retrieval-Augmented Generation (RAG) has shown promising potential by utilizing KGs as external resource to enhance LLMs reasoning.However, existing KG-RAG approaches struggle with a trade-off between flexibility and retrieval quality.Modular methods prioritize flexibility by avoiding the use of KG-fine-tuned models during retrieval, leading to fixed retrieval strategies and suboptimal retrieval quality.Conversely, coupled methods embed KG information within models to improve retrieval quality, but at the expense of flexibility.In this paper, we propose a novel flexible modular KG-RAG framework, termed FRAG, which synergizes the advantages of both approaches.FRAG estimates the hop range of reasoning paths based solely on the query and classify it as either simple or complex.To match the complexity of the query, tailored pipelines are applied to ensure efficient and accurate reasoning path retrieval, thus fostering the final reasoning process.By using the query text instead of the KG to infer the structural information of reasoning paths and employing adaptable retrieval strategies, FRAG improves retrieval quality while maintaining flexibility.Moreover, FRAG does not require extra LLMs fine-tuning or calls, significantly boosting efficiency and conserving resources.Extensive experiments show that FRAG achieves state-of-the-art performance with high efficiency and low resource consumption.
Prototype-based Optimal Transport for Out-of-Distribution Detection
Oct 10, 2024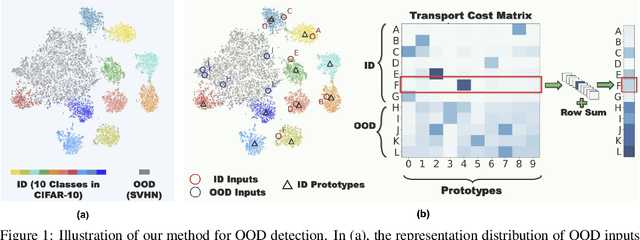
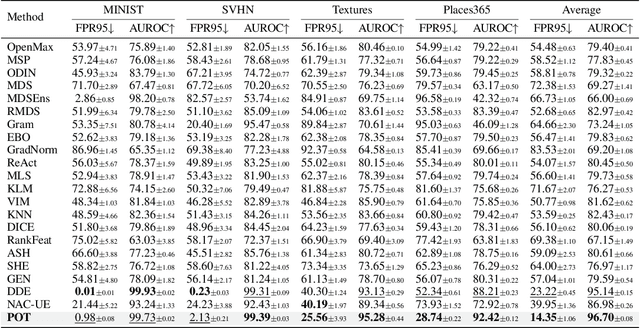

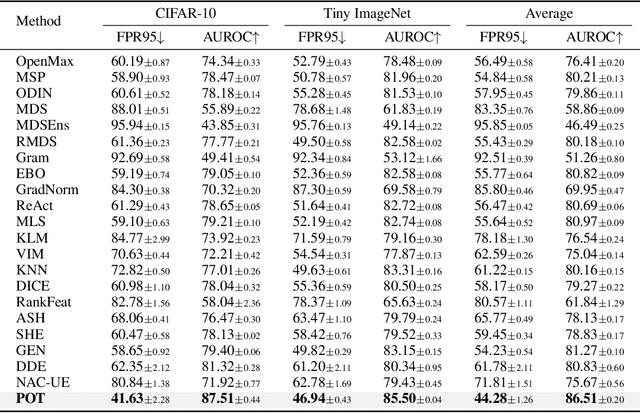
Detecting Out-of-Distribution (OOD) inputs is crucial for improving the reliability of deep neural networks in the real-world deployment. In this paper, inspired by the inherent distribution shift between ID and OOD data, we propose a novel method that leverages optimal transport to measure the distribution discrepancy between test inputs and ID prototypes. The resulting transport costs are used to quantify the individual contribution of each test input to the overall discrepancy, serving as a desirable measure for OOD detection. To address the issue that solely relying on the transport costs to ID prototypes is inadequate for identifying OOD inputs closer to ID data, we generate virtual outliers to approximate the OOD region via linear extrapolation. By combining the transport costs to ID prototypes with the costs to virtual outliers, the detection of OOD data near ID data is emphasized, thereby enhancing the distinction between ID and OOD inputs. Experiments demonstrate the superiority of our method over state-of-the-art methods.
Detecting Out-of-Distribution Samples via Conditional Distribution Entropy with Optimal Transport
Jan 22, 2024When deploying a trained machine learning model in the real world, it is inevitable to receive inputs from out-of-distribution (OOD) sources. For instance, in continual learning settings, it is common to encounter OOD samples due to the non-stationarity of a domain. More generally, when we have access to a set of test inputs, the existing rich line of OOD detection solutions, especially the recent promise of distance-based methods, falls short in effectively utilizing the distribution information from training samples and test inputs. In this paper, we argue that empirical probability distributions that incorporate geometric information from both training samples and test inputs can be highly beneficial for OOD detection in the presence of test inputs available. To address this, we propose to model OOD detection as a discrete optimal transport problem. Within the framework of optimal transport, we propose a novel score function known as the \emph{conditional distribution entropy} to quantify the uncertainty of a test input being an OOD sample. Our proposal inherits the merits of certain distance-based methods while eliminating the reliance on distribution assumptions, a-prior knowledge, and specific training mechanisms. Extensive experiments conducted on benchmark datasets demonstrate that our method outperforms its competitors in OOD detection.