 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStyle-Aligned Image Composition for Robust Detection of Abnormal Cells in Cytopathology
Jun 26, 2025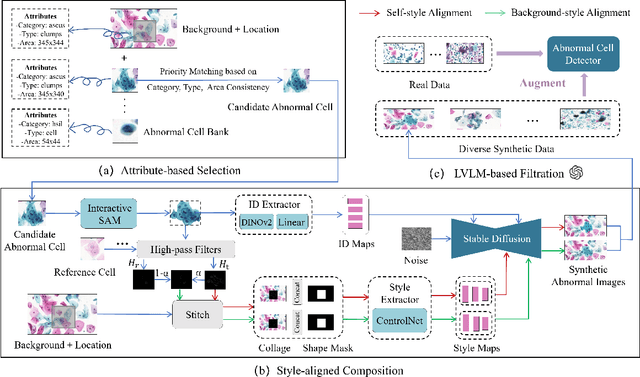
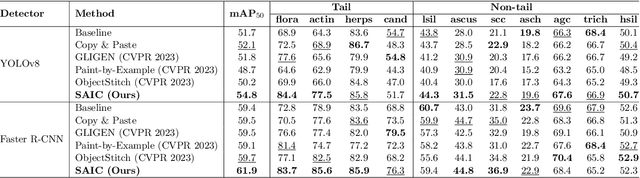
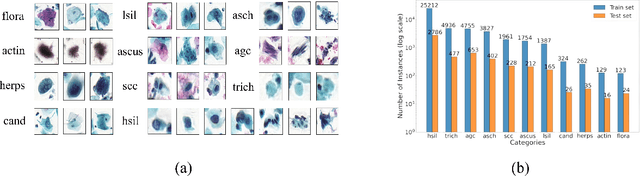

Challenges such as the lack of high-quality annotations, long-tailed data distributions, and inconsistent staining styles pose significant obstacles to training neural networks to detect abnormal cells in cytopathology robustly. This paper proposes a style-aligned image composition (SAIC) method that composes high-fidelity and style-preserved pathological images to enhance the effectiveness and robustness of detection models. Without additional training, SAIC first selects an appropriate candidate from the abnormal cell bank based on attribute guidance. Then, it employs a high-frequency feature reconstruction to achieve a style-aligned and high-fidelity composition of abnormal cells and pathological backgrounds. Finally, it introduces a large vision-language model to filter high-quality synthesis images. Experimental results demonstrate that incorporating SAIC-synthesized images effectively enhances the performance and robustness of abnormal cell detection for tail categories and styles, thereby improving overall detection performance. The comprehensive quality evaluation further confirms the generalizability and practicality of SAIC in clinical application scenarios. Our code will be released at https://github.com/Joey-Qi/SAIC.
Leveraging MIMIC Datasets for Better Digital Health: A Review on Open Problems, Progress Highlights, and Future Promises
Jun 15, 2025The Medical Information Mart for Intensive Care (MIMIC) datasets have become the Kernel of Digital Health Research by providing freely accessible, deidentified records from tens of thousands of critical care admissions, enabling a broad spectrum of applications in clinical decision support, outcome prediction, and healthcare analytics. Although numerous studies and surveys have explored the predictive power and clinical utility of MIMIC based models, critical challenges in data integration, representation, and interoperability remain underexplored. This paper presents a comprehensive survey that focuses uniquely on open problems. We identify persistent issues such as data granularity, cardinality limitations, heterogeneous coding schemes, and ethical constraints that hinder the generalizability and real-time implementation of machine learning models. We highlight key progress in dimensionality reduction, temporal modelling, causal inference, and privacy preserving analytics, while also outlining promising directions including hybrid modelling, federated learning, and standardized preprocessing pipelines. By critically examining these structural limitations and their implications, this survey offers actionable insights to guide the next generation of MIMIC powered digital health innovations.
SkewRoute: Training-Free LLM Routing for Knowledge Graph Retrieval-Augmented Generation via Score Skewness of Retrieved Context
May 28, 2025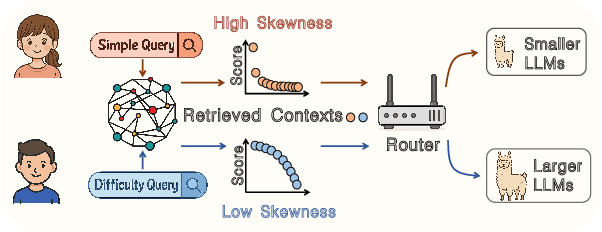
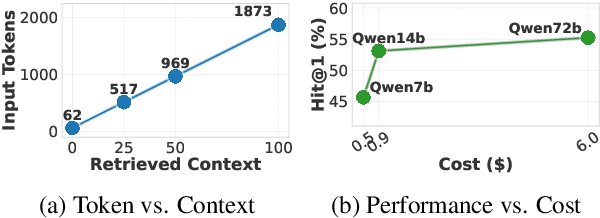

Large language models excel at many tasks but often incur high inference costs during deployment. To mitigate hallucination, many systems use a knowledge graph to enhance retrieval-augmented generation (KG-RAG). However, the large amount of retrieved knowledge contexts increase these inference costs further. A promising solution to balance performance and cost is LLM routing, which directs simple queries to smaller LLMs and complex ones to larger LLMs. However, no dedicated routing methods currently exist for RAG, and existing training-based routers face challenges scaling to this domain due to the need for extensive training data. We observe that the score distributions produced by the retrieval scorer strongly correlate with query difficulty. Based on this, we propose a novel, training-free routing framework, the first tailored to KG-RAG that effectively balances performance and cost in a plug-and-play manner. Experiments show our method reduces calls to larger LLMs by up to 50% without sacrificing response quality, demonstrating its potential for efficient and scalable LLM deployment.
Lego Sketch: A Scalable Memory-augmented Neural Network for Sketching Data Streams
May 26, 2025Sketches, probabilistic structures for estimating item frequencies in infinite data streams with limited space, are widely used across various domains. Recent studies have shifted the focus from handcrafted sketches to neural sketches, leveraging memory-augmented neural networks (MANNs) to enhance the streaming compression capabilities and achieve better space-accuracy trade-offs.However, existing neural sketches struggle to scale across different data domains and space budgets due to inflexible MANN configurations. In this paper, we introduce a scalable MANN architecture that brings to life the {\it Lego sketch}, a novel sketch with superior scalability and accuracy. Much like assembling creations with modular Lego bricks, the Lego sketch dynamically coordinates multiple memory bricks to adapt to various space budgets and diverse data domains. Our theoretical analysis guarantees its high scalability and provides the first error bound for neural sketch. Furthermore, extensive experimental evaluations demonstrate that the Lego sketch exhibits superior space-accuracy trade-offs, outperforming existing handcrafted and neural sketches. Our code is available at https://github.com/FFY0/LegoSketch_ICML.
Path Pooling: Train-Free Structure Enhancement for Efficient Knowledge Graph Retrieval-Augmented Generation
Mar 07, 2025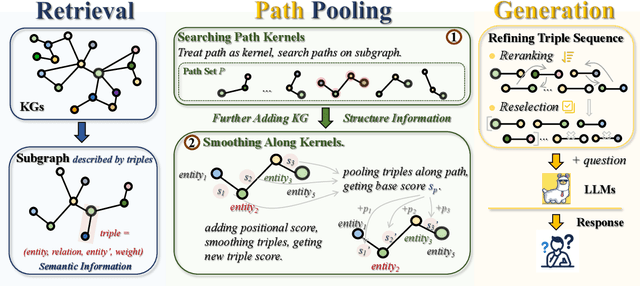
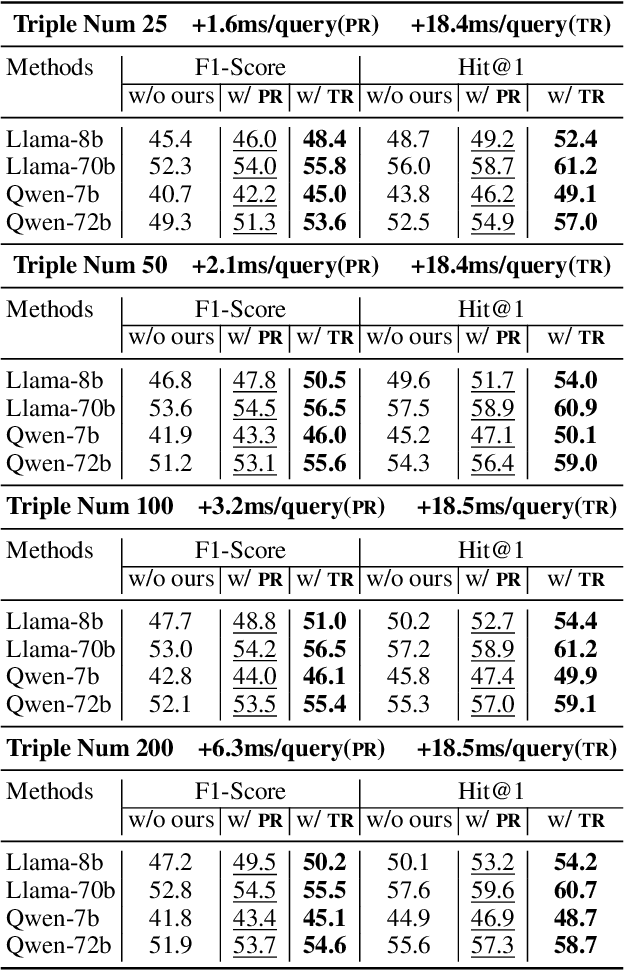
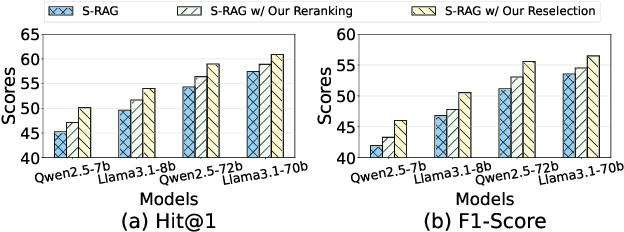

Although Large Language Models achieve strong success in many tasks, they still suffer from hallucinations and knowledge deficiencies in real-world applications. Many knowledge graph-based retrieval-augmented generation (KG-RAG) methods enhance the quality and credibility of LLMs by leveraging structure and semantic information in KGs as external knowledge bases. However, these methods struggle to effectively incorporate structure information, either incurring high computational costs or underutilizing available knowledge. Inspired by smoothing operations in graph representation learning, we propose path pooling, a simple, train-free strategy that introduces structure information through a novel path-centric pooling operation. It seamlessly integrates into existing KG-RAG methods in a plug-and-play manner, enabling richer structure information utilization. Extensive experiments demonstrate that incorporating the path pooling into the state-of-the-art KG-RAG method consistently improves performance across various settings while introducing negligible additional cost. Code is coming soon at https://github.com/hrwang00/path-pooling.
Identify Critical KV Cache in LLM Inference from an Output Perturbation Perspective
Feb 06, 2025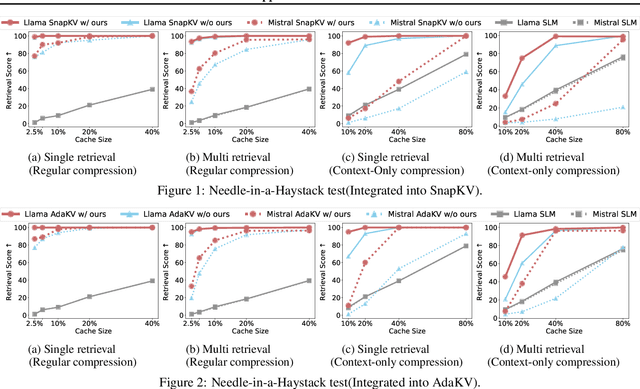
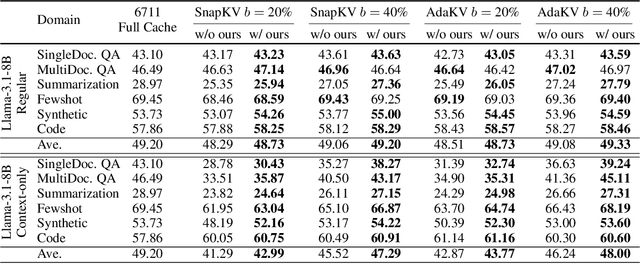
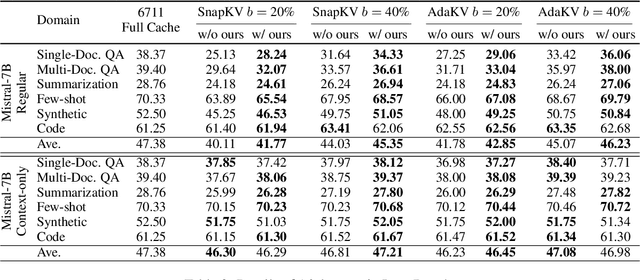
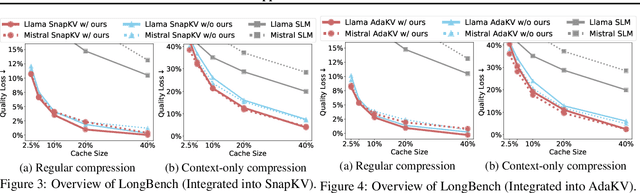
Large language models have revolutionized natural language processing but face significant challenges of high storage and runtime costs, due to the transformer architecture's reliance on self-attention, particularly the large Key-Value (KV) cache for long-sequence inference. Recent efforts to reduce KV cache size by pruning less critical entries based on attention weights remain empirical and lack formal grounding. This paper presents a formal study on identifying critical KV cache entries by analyzing attention output perturbation. Our analysis reveals that, beyond attention weights, the value states within KV entries and pretrained parameter matrices are also crucial. Based on this, we propose a perturbation-constrained selection algorithm that optimizes the worst-case output perturbation to identify critical entries. Evaluations on the Needle-in-a-Haystack test and Longbench benchmark show our algorithm enhances state-of-the-art cache eviction methods. Further empirical analysis confirms that our algorithm achieves lower output perturbations in over 92% attention heads in Llama model, thereby providing a significant improvement over existing methods.
FRAG: A Flexible Modular Framework for Retrieval-Augmented Generation based on Knowledge Graphs
Jan 17, 2025



To mitigate the hallucination and knowledge deficiency in large language models (LLMs), Knowledge Graph (KG)-based Retrieval-Augmented Generation (RAG) has shown promising potential by utilizing KGs as external resource to enhance LLMs reasoning.However, existing KG-RAG approaches struggle with a trade-off between flexibility and retrieval quality.Modular methods prioritize flexibility by avoiding the use of KG-fine-tuned models during retrieval, leading to fixed retrieval strategies and suboptimal retrieval quality.Conversely, coupled methods embed KG information within models to improve retrieval quality, but at the expense of flexibility.In this paper, we propose a novel flexible modular KG-RAG framework, termed FRAG, which synergizes the advantages of both approaches.FRAG estimates the hop range of reasoning paths based solely on the query and classify it as either simple or complex.To match the complexity of the query, tailored pipelines are applied to ensure efficient and accurate reasoning path retrieval, thus fostering the final reasoning process.By using the query text instead of the KG to infer the structural information of reasoning paths and employing adaptable retrieval strategies, FRAG improves retrieval quality while maintaining flexibility.Moreover, FRAG does not require extra LLMs fine-tuning or calls, significantly boosting efficiency and conserving resources.Extensive experiments show that FRAG achieves state-of-the-art performance with high efficiency and low resource consumption.
LACOSTE: Exploiting stereo and temporal contexts for surgical instrument segmentation
Sep 14, 2024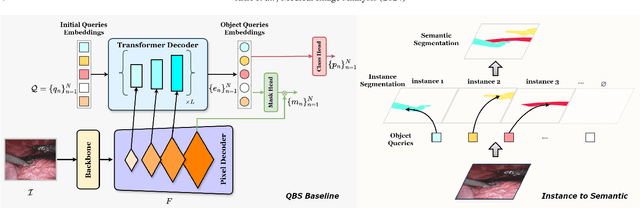
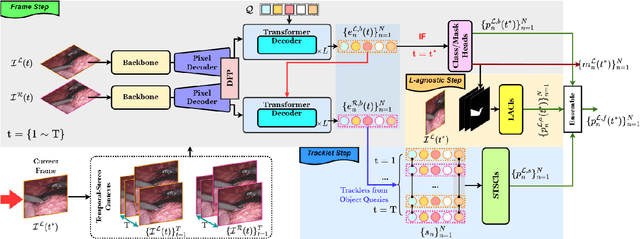
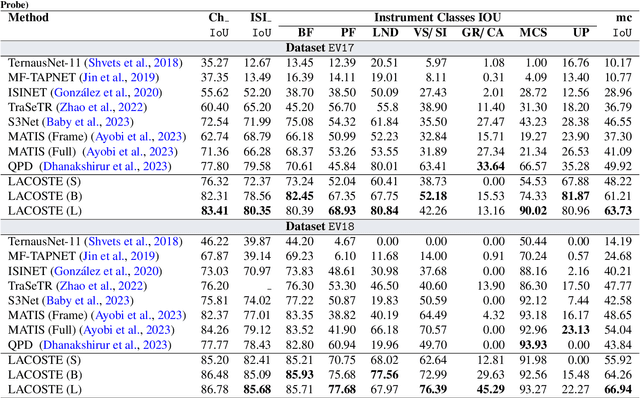
Surgical instrument segmentation is instrumental to minimally invasive surgeries and related applications. Most previous methods formulate this task as single-frame-based instance segmentation while ignoring the natural temporal and stereo attributes of a surgical video. As a result, these methods are less robust against the appearance variation through temporal motion and view change. In this work, we propose a novel LACOSTE model that exploits Location-Agnostic COntexts in Stereo and TEmporal images for improved surgical instrument segmentation. Leveraging a query-based segmentation model as core, we design three performance-enhancing modules. Firstly, we design a disparity-guided feature propagation module to enhance depth-aware features explicitly. To generalize well for even only a monocular video, we apply a pseudo stereo scheme to generate complementary right images. Secondly, we propose a stereo-temporal set classifier, which aggregates stereo-temporal contexts in a universal way for making a consolidated prediction and mitigates transient failures. Finally, we propose a location-agnostic classifier to decouple the location bias from mask prediction and enhance the feature semantics. We extensively validate our approach on three public surgical video datasets, including two benchmarks from EndoVis Challenges and one real radical prostatectomy surgery dataset GraSP. Experimental results demonstrate the promising performances of our method, which consistently achieves comparable or favorable results with previous state-of-the-art approaches.
Long-tailed multi-label classification with noisy label of thoracic diseases from chest X-ray
Nov 29, 2023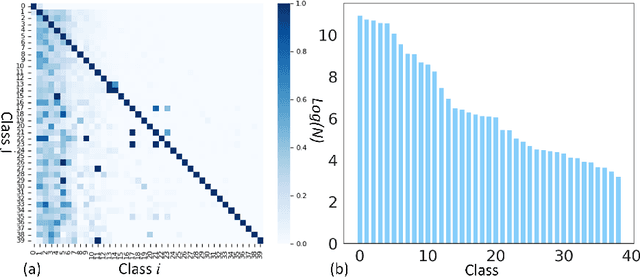
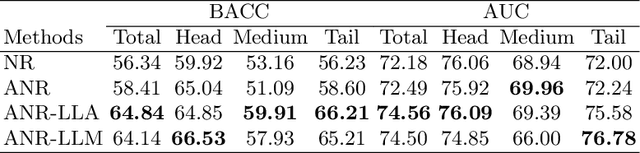
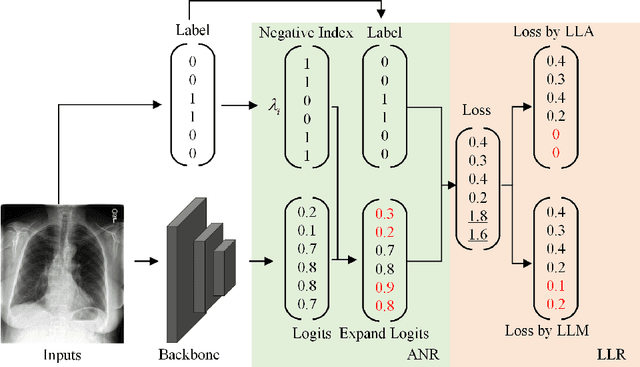
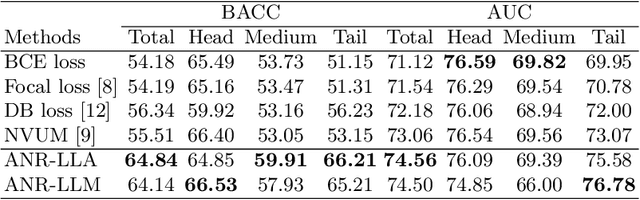
Chest X-rays (CXR) often reveal rare diseases, demanding precise diagnosis. However, current computer-aided diagnosis (CAD) methods focus on common diseases, leading to inadequate detection of rare conditions due to the absence of comprehensive datasets. To overcome this, we present a novel benchmark for long-tailed multi-label classification in CXRs, encapsulating both common and rare thoracic diseases. Our approach includes developing the "LTML-MIMIC-CXR" dataset, an augmentation of MIMIC-CXR with 26 additional rare diseases. We propose a baseline method for this classification challenge, integrating adaptive negative regularization to address negative logits' over-suppression in tail classes, and a large loss reconsideration strategy for correcting noisy labels from automated annotations. Our evaluation on LTML-MIMIC-CXR demonstrates significant advancements in rare disease detection. This work establishes a foundation for robust CAD methods, achieving a balance in identifying a spectrum of thoracic diseases in CXRs. Access to our code and dataset is provided at:https://github.com/laihaoran/LTML-MIMIC-CXR.
Rethinking Semi-Supervised Medical Image Segmentation: A Variance-Reduction Perspective
Feb 07, 2023



For medical image segmentation, contrastive learning is the dominant practice to improve the quality of visual representations by contrasting semantically similar and dissimilar pairs of samples. This is enabled by the observation that without accessing ground truth label, negative examples with truly dissimilar anatomical features, if sampled, can significantly improve the performance. In reality, however, these samples may come from similar anatomical features and the models may struggle to distinguish the minority tail-class samples, making the tail classes more prone to misclassification, both of which typically lead to model collapse. In this paper, we propose ARCO, a semi-supervised contrastive learning (CL) framework with stratified group sampling theory in medical image segmentation. In particular, we first propose building ARCO through the concept of variance-reduced estimation, and show that certain variance-reduction techniques are particularly beneficial in medical image segmentation tasks with extremely limited labels. Furthermore, we theoretically prove these sampling techniques are universal in variance reduction. Finally, we experimentally validate our approaches on three benchmark datasets with different label settings, and our methods consistently outperform state-of-the-art semi- and fully-supervised methods. Additionally, we augment the CL frameworks with these sampling techniques and demonstrate significant gains over previous methods. We believe our work is an important step towards semi-supervised medical image segmentation by quantifying the limitation of current self-supervision objectives for accomplishing medical image analysis tasks.