 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge4th Workshop on Maritime Computer Vision (MaCVi): Challenge Overview
Apr 14, 2026The 4th Workshop on Maritime Computer Vision (MaCVi) is organized as part of CVPR 2026. This edition features five benchmark challenges with emphasis on both predictive accuracy and embedded real-time feasibility. This report summarizes the MaCVi 2026 challenge setup, evaluation protocols, datasets, and benchmark tracks, and presents quantitative results, qualitative comparisons, and cross-challenge analyses of emerging method trends. We also include technical reports from top-performing teams to highlight practical design choices and lessons learned across the benchmark suite. Datasets, leaderboards, and challenge resources are available at https://macvi.org/workshop/cvpr26.
VA-FastNavi-MARL: Real-Time Robot Control with Multimedia-Driven Meta-Reinforcement Learning
Apr 05, 2026Interpreting dynamic, heterogeneous multimedia commands with real-time responsiveness is critical for Human-Robot Interaction. We present VA-FastNavi-MARL, a framework that aligns asynchronous audio-visual inputs into a unified latent representation. By treating diverse instructions as a distribution of navigable goals via Meta-Reinforcement Learning, our method enables rapid adaptation to unseen directives with negligible inference overhead. Unlike approaches bottlenecked by heavy sensory processing, our modality-agnostic stream ensures seamless, low-latency control. Validation on a multi-arm workspace confirms that VA-FastNavi-MARL significantly outperforms baselines in sample efficiency and maintains robust, real-time execution even under noisy multimedia streams.
* Accepted to the 2026 IEEE International Conference on Multimedia and Expo (ICME 2026)
Milestones over Outcome: Unlocking Geometric Reasoning with Sub-Goal Verifiable Reward
Jan 08, 2026Multimodal Large Language Models (MLLMs) struggle with complex geometric reasoning, largely because "black box" outcome-based supervision fails to distinguish between lucky guesses and rigorous deduction. To address this, we introduce a paradigm shift towards subgoal-level evaluation and learning. We first construct GeoGoal, a benchmark synthesized via a rigorous formal verification data engine, which converts abstract proofs into verifiable numeric subgoals. This structure reveals a critical divergence between reasoning quality and outcome accuracy. Leveraging this, we propose the Sub-Goal Verifiable Reward (SGVR) framework, which replaces sparse signals with dense rewards based on the Skeleton Rate. Experiments demonstrate that SGVR not only enhances geometric performance (+9.7%) but also exhibits strong generalization, transferring gains to general math (+8.0%) and other general reasoning tasks (+2.8%), demonstrating broad applicability across diverse domains.
GeoBench: Rethinking Multimodal Geometric Problem-Solving via Hierarchical Evaluation
Dec 30, 2025Geometric problem solving constitutes a critical branch of mathematical reasoning, requiring precise analysis of shapes and spatial relationships. Current evaluations of geometric reasoning in vision-language models (VLMs) face limitations, including the risk of test data contamination from textbook-based benchmarks, overemphasis on final answers over reasoning processes, and insufficient diagnostic granularity. To address these issues, we present GeoBench, a hierarchical benchmark featuring four reasoning levels in geometric problem-solving: Visual Perception, Goal-Oriented Planning, Rigorous Theorem Application, and Self-Reflective Backtracking. Through six formally verified tasks generated via TrustGeoGen, we systematically assess capabilities ranging from attribute extraction to logical error correction. Experiments reveal that while reasoning models like OpenAI-o3 outperform general MLLMs, performance declines significantly with increasing task complexity. Key findings demonstrate that sub-goal decomposition and irrelevant premise filtering critically influence final problem-solving accuracy, whereas Chain-of-Thought prompting unexpectedly degrades performance in some tasks. These findings establish GeoBench as a comprehensive benchmark while offering actionable guidelines for developing geometric problem-solving systems.
AttnCache: Accelerating Self-Attention Inference for LLM Prefill via Attention Cache
Oct 29, 2025



Large Language Models (LLMs) are widely used in generative applications such as chatting, code generation, and reasoning. However, many realworld workloads such as classification, question answering, recommendation, and text embedding rely solely on the prefill stage of inference, where the model encodes input sequences without performing autoregressive decoding. In these prefill only scenarios, the self-attention computation becomes the primary performance bottleneck due to its quadratic complexity with respect to sequence length. In this paper, we observe that semantically different sentences often produce similar attention maps across layers and heads. Building on this insight, we propose AttnCache, a framework that accelerates the prefill stage of LLM inference by retrieving and reusing similar attention maps. Based on an attention map memorization database, AttnCache employs efficient caching and similarity search techniques to identify and reuse pre-cached attention maps during inference, thereby reducing the computational overhead of self-attention. Experimental results show that AttnCache achieves an average of 1.2x end-to-end and 2x attention speedup on CPU, and 1.6x end-to-end and 3x attention speedup on GPU, with negligible accuracy degradation.
Social Robots for People with Dementia: A Literature Review on Deception from Design to Perception
Jul 01, 2025As social robots increasingly enter dementia care, concerns about deception, intentional or not, are gaining attention. Yet, how robotic design cues might elicit misleading perceptions in people with dementia, and how these perceptions arise, remains insufficiently understood. In this scoping review, we examined 26 empirical studies on interactions between people with dementia and physical social robots. We identify four key design cue categories that may influence deceptive impressions: cues resembling physiological signs (e.g., simulated breathing), social intentions (e.g., playful movement), familiar beings (e.g., animal-like form and sound), and, to a lesser extent, cues that reveal artificiality. Thematic analysis of user responses reveals that people with dementia often attribute biological, social, and mental capacities to robots, dynamically shifting between awareness and illusion. These findings underscore the fluctuating nature of ontological perception in dementia contexts. Existing definitions of robotic deception often rest on philosophical or behaviorist premises, but rarely engage with the cognitive mechanisms involved. We propose an empirically grounded definition: robotic deception occurs when Type 1 (automatic, heuristic) processing dominates over Type 2 (deliberative, analytic) reasoning, leading to misinterpretation of a robot's artificial nature. This dual-process perspective highlights the ethical complexity of social robots in dementia care and calls for design approaches that are not only engaging, but also epistemically respectful.
Serving Large Language Models on Huawei CloudMatrix384
Jun 15, 2025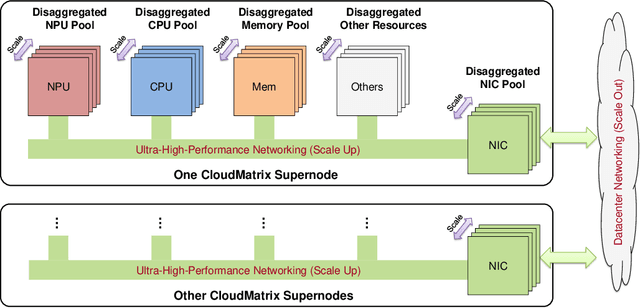
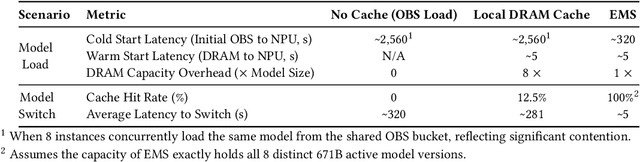
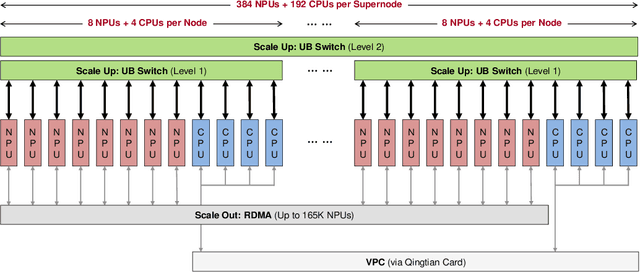
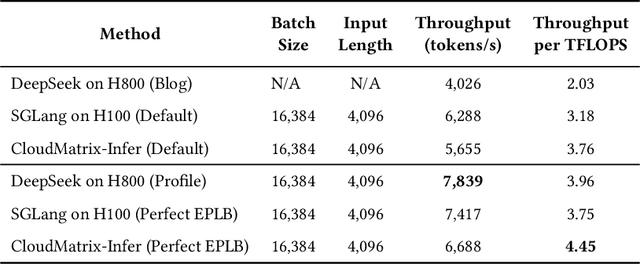
The rapid evolution of large language models (LLMs), driven by growing parameter scales, adoption of mixture-of-experts (MoE) architectures, and expanding context lengths, imposes unprecedented demands on AI infrastructure. Traditional AI clusters face limitations in compute intensity, memory bandwidth, inter-chip communication, and latency, compounded by variable workloads and strict service-level objectives. Addressing these issues requires fundamentally redesigned hardware-software integration. This paper introduces Huawei CloudMatrix, a next-generation AI datacenter architecture, realized in the production-grade CloudMatrix384 supernode. It integrates 384 Ascend 910C NPUs and 192 Kunpeng CPUs interconnected via an ultra-high-bandwidth Unified Bus (UB) network, enabling direct all-to-all communication and dynamic pooling of resources. These features optimize performance for communication-intensive operations, such as large-scale MoE expert parallelism and distributed key-value cache access. To fully leverage CloudMatrix384, we propose CloudMatrix-Infer, an advanced LLM serving solution incorporating three core innovations: a peer-to-peer serving architecture that independently scales prefill, decode, and caching; a large-scale expert parallelism strategy supporting EP320 via efficient UB-based token dispatch; and hardware-aware optimizations including specialized operators, microbatch-based pipelining, and INT8 quantization. Evaluation with the DeepSeek-R1 model shows CloudMatrix-Infer achieves state-of-the-art efficiency: prefill throughput of 6,688 tokens/s per NPU and decode throughput of 1,943 tokens/s per NPU (<50 ms TPOT). It effectively balances throughput and latency, sustaining 538 tokens/s even under stringent 15 ms latency constraints, while INT8 quantization maintains model accuracy across benchmarks.
Today's Cat Is Tomorrow's Dog: Accounting for Time-Based Changes in the Labels of ML Vulnerability Detection Approaches
Jun 13, 2025Vulnerability datasets used for ML testing implicitly contain retrospective information. When tested on the field, one can only use the labels available at the time of training and testing (e.g. seen and assumed negatives). As vulnerabilities are discovered across calendar time, labels change and past performance is not necessarily aligned with future performance. Past works only considered the slices of the whole history (e.g. DiverseVUl) or individual differences between releases (e.g. Jimenez et al. ESEC/FSE 2019). Such approaches are either too optimistic in training (e.g. the whole history) or too conservative (e.g. consecutive releases). We propose a method to restructure a dataset into a series of datasets in which both training and testing labels change to account for the knowledge available at the time. If the model is actually learning, it should improve its performance over time as more data becomes available and data becomes more stable, an effect that can be checked with the Mann-Kendall test. We validate our methodology for vulnerability detection with 4 time-based datasets (3 projects from BigVul dataset + Vuldeepecker's NVD) and 5 ML models (Code2Vec, CodeBERT, LineVul, ReGVD, and Vuldeepecker). In contrast to the intuitive expectation (more retrospective information, better performance), the trend results show that performance changes inconsistently across the years, showing that most models are not learning.
SkewRoute: Training-Free LLM Routing for Knowledge Graph Retrieval-Augmented Generation via Score Skewness of Retrieved Context
May 28, 2025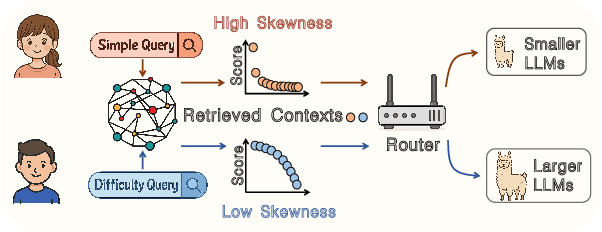
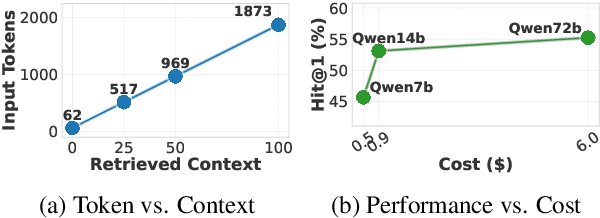

Large language models excel at many tasks but often incur high inference costs during deployment. To mitigate hallucination, many systems use a knowledge graph to enhance retrieval-augmented generation (KG-RAG). However, the large amount of retrieved knowledge contexts increase these inference costs further. A promising solution to balance performance and cost is LLM routing, which directs simple queries to smaller LLMs and complex ones to larger LLMs. However, no dedicated routing methods currently exist for RAG, and existing training-based routers face challenges scaling to this domain due to the need for extensive training data. We observe that the score distributions produced by the retrieval scorer strongly correlate with query difficulty. Based on this, we propose a novel, training-free routing framework, the first tailored to KG-RAG that effectively balances performance and cost in a plug-and-play manner. Experiments show our method reduces calls to larger LLMs by up to 50% without sacrificing response quality, demonstrating its potential for efficient and scalable LLM deployment.
Lego Sketch: A Scalable Memory-augmented Neural Network for Sketching Data Streams
May 26, 2025Sketches, probabilistic structures for estimating item frequencies in infinite data streams with limited space, are widely used across various domains. Recent studies have shifted the focus from handcrafted sketches to neural sketches, leveraging memory-augmented neural networks (MANNs) to enhance the streaming compression capabilities and achieve better space-accuracy trade-offs.However, existing neural sketches struggle to scale across different data domains and space budgets due to inflexible MANN configurations. In this paper, we introduce a scalable MANN architecture that brings to life the {\it Lego sketch}, a novel sketch with superior scalability and accuracy. Much like assembling creations with modular Lego bricks, the Lego sketch dynamically coordinates multiple memory bricks to adapt to various space budgets and diverse data domains. Our theoretical analysis guarantees its high scalability and provides the first error bound for neural sketch. Furthermore, extensive experimental evaluations demonstrate that the Lego sketch exhibits superior space-accuracy trade-offs, outperforming existing handcrafted and neural sketches. Our code is available at https://github.com/FFY0/LegoSketch_ICML.