 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-grained Preference Optimization Improves Zero-shot Text-to-Speech
Paper and Code
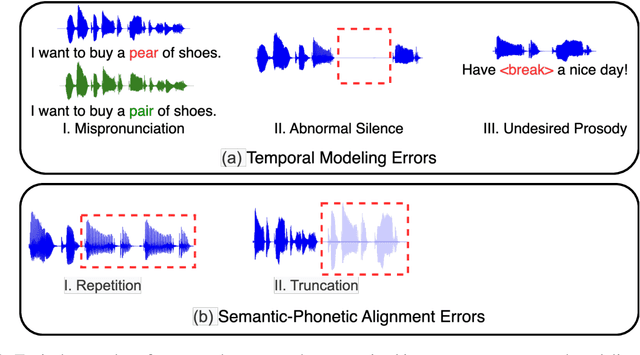
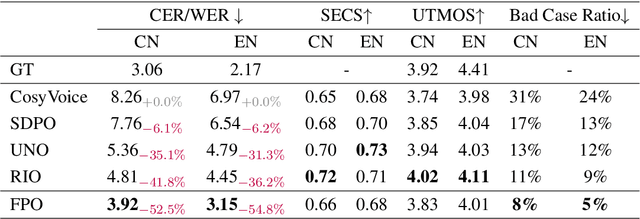
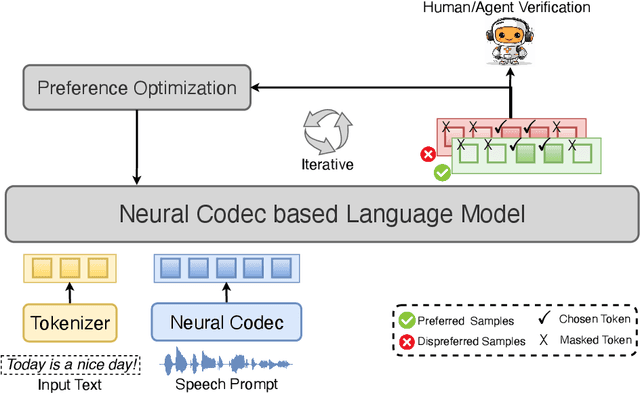
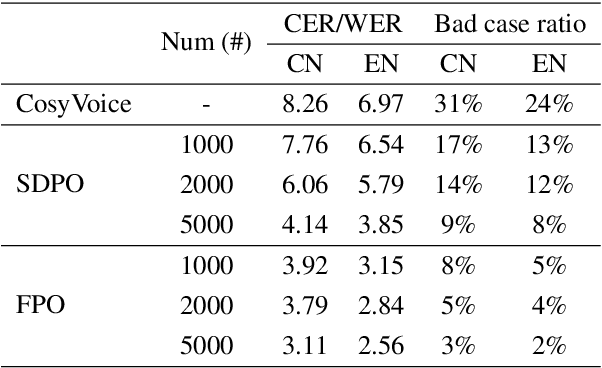
Integrating human feedback to align text-to-speech (TTS) system outputs with human preferences has proven to be an effective approach for enhancing the robustness of language model-based TTS systems. Current approaches primarily focus on using preference data annotated at the utterance level. However, frequent issues that affect the listening experience often only arise in specific segments of audio samples, while other segments are well-generated. In this study, we propose a fine-grained preference optimization approach (FPO) to enhance the robustness of TTS systems. FPO focuses on addressing localized issues in generated samples rather than uniformly optimizing the entire utterance. Specifically, we first analyze the types of issues in generated samples, categorize them into two groups, and propose a selective training loss strategy to optimize preferences based on fine-grained labels for each issue type. Experimental results show that FPO enhances the robustness of zero-shot TTS systems by effectively addressing local issues, significantly reducing the bad case ratio, and improving intelligibility. Furthermore, FPO exhibits superior data efficiency compared with baseline systems, achieving similar performance with fewer training samples.