 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeS2ST-Omni: An Efficient and Scalable Multilingual Speech-to-Speech Translation Framework via Seamlessly Speech-Text Alignment and Streaming Speech Decoder
Jun 16, 2025

Multilingual speech-to-speech translation (S2ST) aims to directly convert spoken utterances from multiple source languages into fluent and intelligible speech in a target language. Despite recent progress, several critical challenges persist: 1) achieving high-quality and low-latency S2ST remains a significant obstacle; 2) most existing S2ST methods rely heavily on large-scale parallel speech corpora, which are difficult and resource-intensive to obtain. To tackle these challenges, we introduce S2ST-Omni, a novel, efficient, and scalable framework tailored for multilingual speech-to-speech translation. To enable high-quality S2TT while mitigating reliance on large-scale parallel speech corpora, we leverage powerful pretrained models: Whisper for robust audio understanding and Qwen 3.0 for advanced text comprehension. A lightweight speech adapter is introduced to bridge the modality gap between speech and text representations, facilitating effective utilization of pretrained multimodal knowledge. To ensure both translation accuracy and real-time responsiveness, we adopt a streaming speech decoder in the TTS stage, which generates the target speech in an autoregressive manner. Extensive experiments conducted on the CVSS benchmark demonstrate that S2ST-Omni consistently surpasses several state-of-the-art S2ST baselines in translation quality, highlighting its effectiveness and superiority.
ClapFM-EVC: High-Fidelity and Flexible Emotional Voice Conversion with Dual Control from Natural Language and Speech
May 20, 2025



Despite great advances, achieving high-fidelity emotional voice conversion (EVC) with flexible and interpretable control remains challenging. This paper introduces ClapFM-EVC, a novel EVC framework capable of generating high-quality converted speech driven by natural language prompts or reference speech with adjustable emotion intensity. We first propose EVC-CLAP, an emotional contrastive language-audio pre-training model, guided by natural language prompts and categorical labels, to extract and align fine-grained emotional elements across speech and text modalities. Then, a FuEncoder with an adaptive intensity gate is presented to seamless fuse emotional features with Phonetic PosteriorGrams from a pre-trained ASR model. To further improve emotion expressiveness and speech naturalness, we propose a flow matching model conditioned on these captured features to reconstruct Mel-spectrogram of source speech. Subjective and objective evaluations validate the effectiveness of ClapFM-EVC.
Fine-grained Preference Optimization Improves Zero-shot Text-to-Speech
Feb 05, 2025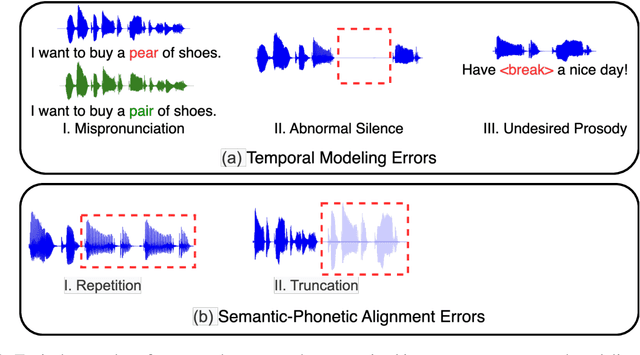
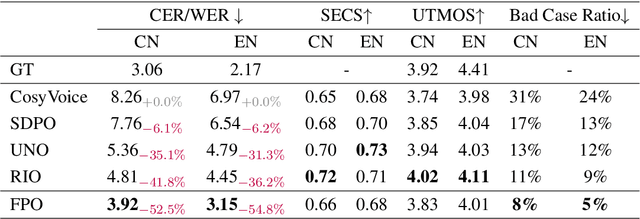
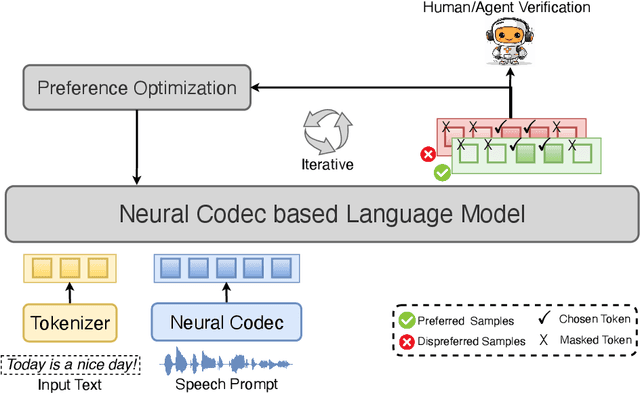
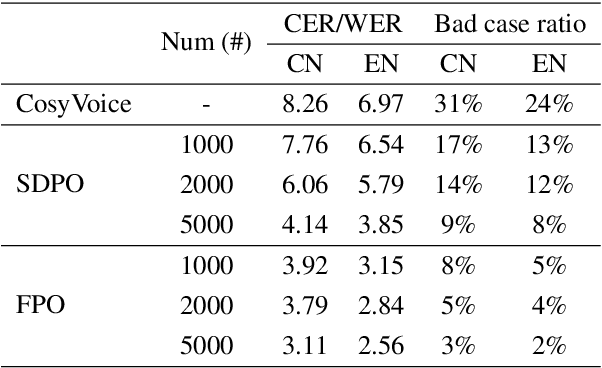
Integrating human feedback to align text-to-speech (TTS) system outputs with human preferences has proven to be an effective approach for enhancing the robustness of language model-based TTS systems. Current approaches primarily focus on using preference data annotated at the utterance level. However, frequent issues that affect the listening experience often only arise in specific segments of audio samples, while other segments are well-generated. In this study, we propose a fine-grained preference optimization approach (FPO) to enhance the robustness of TTS systems. FPO focuses on addressing localized issues in generated samples rather than uniformly optimizing the entire utterance. Specifically, we first analyze the types of issues in generated samples, categorize them into two groups, and propose a selective training loss strategy to optimize preferences based on fine-grained labels for each issue type. Experimental results show that FPO enhances the robustness of zero-shot TTS systems by effectively addressing local issues, significantly reducing the bad case ratio, and improving intelligibility. Furthermore, FPO exhibits superior data efficiency compared with baseline systems, achieving similar performance with fewer training samples.
CTEFM-VC: Zero-Shot Voice Conversion Based on Content-Aware Timbre Ensemble Modeling and Flow Matching
Nov 04, 2024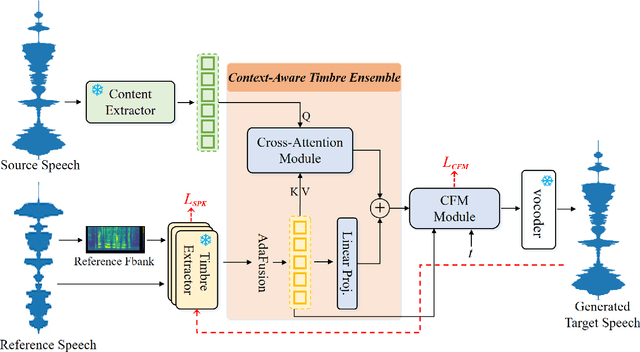
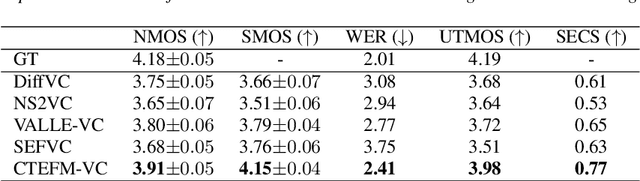
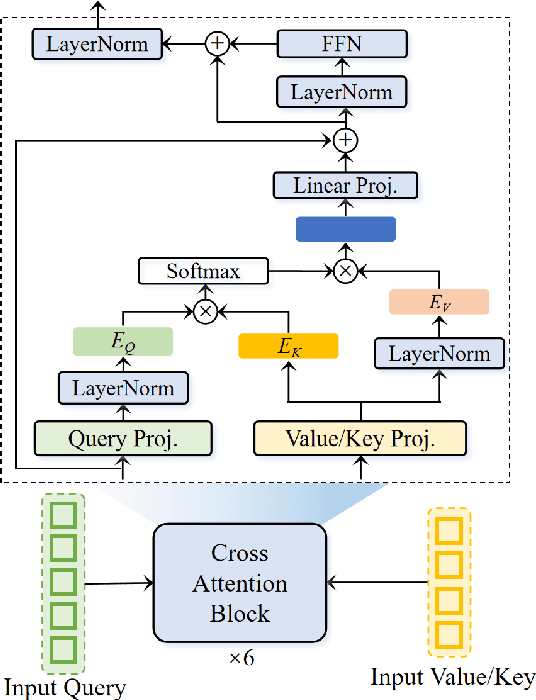
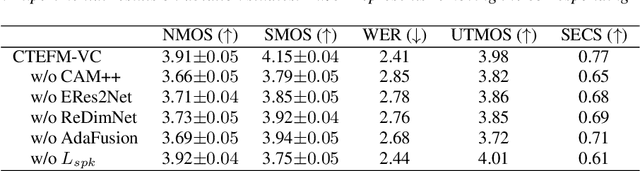
Zero-shot voice conversion (VC) aims to transform the timbre of a source speaker into any previously unseen target speaker, while preserving the original linguistic content. Despite notable progress, attaining a degree of speaker similarity and naturalness on par with ground truth recordings continues to pose great challenge. In this paper, we propose CTEFM-VC, a zero-shot VC framework that leverages Content-aware Timbre Ensemble modeling and Flow Matching. Specifically, CTEFM-VC disentangles utterances into linguistic content and timbre representations, subsequently utilizing a conditional flow matching model and a vocoder to reconstruct the mel-spectrogram and waveform. To enhance its timbre modeling capability and the naturalness of generated speech, we propose a context-aware timbre ensemble modeling approach that adaptively integrates diverse speaker verification embeddings and enables the joint utilization of linguistic and timbre features through a cross-attention module. Experiments show that our CTEFM-VC system surpasses state-of-the-art VC methods in both speaker similarity and naturalness by at least 18.5% and 7.0%.
Takin-ADA: Emotion Controllable Audio-Driven Animation with Canonical and Landmark Loss Optimization
Oct 18, 2024Existing audio-driven facial animation methods face critical challenges, including expression leakage, ineffective subtle expression transfer, and imprecise audio-driven synchronization. We discovered that these issues stem from limitations in motion representation and the lack of fine-grained control over facial expressions. To address these problems, we present Takin-ADA, a novel two-stage approach for real-time audio-driven portrait animation. In the first stage, we introduce a specialized loss function that enhances subtle expression transfer while reducing unwanted expression leakage. The second stage utilizes an advanced audio processing technique to improve lip-sync accuracy. Our method not only generates precise lip movements but also allows flexible control over facial expressions and head motions. Takin-ADA achieves high-resolution (512x512) facial animations at up to 42 FPS on an RTX 4090 GPU, outperforming existing commercial solutions. Extensive experiments demonstrate that our model significantly surpasses previous methods in video quality, facial dynamics realism, and natural head movements, setting a new benchmark in the field of audio-driven facial animation.
Takin-VC: Zero-shot Voice Conversion via Jointly Hybrid Content and Memory-Augmented Context-Aware Timbre Modeling
Oct 02, 2024



Zero-shot voice conversion (VC) aims to transform the source speaker timbre into an arbitrary unseen one without altering the original speech content.While recent advancements in zero-shot VC methods have shown remarkable progress, there still remains considerable potential for improvement in terms of improving speaker similarity and speech naturalness.In this paper, we propose Takin-VC, a novel zero-shot VC framework based on jointly hybrid content and memory-augmented context-aware timbre modeling to tackle this challenge. Specifically, an effective hybrid content encoder, guided by neural codec training, that leverages quantized features from pre-trained WavLM and HybridFormer is first presented to extract the linguistic content of the source speech. Subsequently, we introduce an advanced cross-attention-based context-aware timbre modeling approach that learns the fine-grained, semantically associated target timbre features. To further enhance both speaker similarity and real-time performance, we utilize a conditional flow matching model to reconstruct the Mel-spectrogram of the source speech. Additionally, we advocate an efficient memory-augmented module designed to generate high-quality conditional target inputs for the flow matching process, thereby improving the overall performance of the proposed system. Experimental results demonstrate that the proposed Takin-VC method surpasses state-of-the-art zero-shot VC systems, delivering superior performance in terms of both speech naturalness and speaker similarity.
Takin: A Cohort of Superior Quality Zero-shot Speech Generation Models
Sep 18, 2024



With the advent of the big data and large language model era, zero-shot personalized rapid customization has emerged as a significant trend. In this report, we introduce Takin AudioLLM, a series of techniques and models, mainly including Takin TTS, Takin VC, and Takin Morphing, specifically designed for audiobook production. These models are capable of zero-shot speech production, generating high-quality speech that is nearly indistinguishable from real human speech and facilitating individuals to customize the speech content according to their own needs. Specifically, we first introduce Takin TTS, a neural codec language model that builds upon an enhanced neural speech codec and a multi-task training framework, capable of generating high-fidelity natural speech in a zero-shot way. For Takin VC, we advocate an effective content and timbre joint modeling approach to improve the speaker similarity, while advocating for a conditional flow matching based decoder to further enhance its naturalness and expressiveness. Last, we propose the Takin Morphing system with highly decoupled and advanced timbre and prosody modeling approaches, which enables individuals to customize speech production with their preferred timbre and prosody in a precise and controllable manner. Extensive experiments validate the effectiveness and robustness of our Takin AudioLLM series models. For detailed demos, please refer to https://takinaudiollm.github.io.
Improving Cross-lingual Speech Synthesis with Triplet Training Scheme
Feb 22, 2022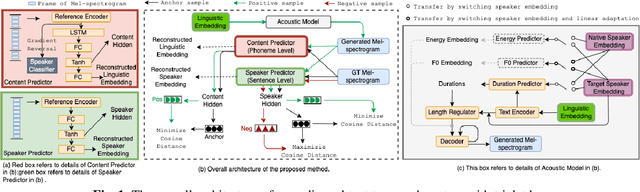
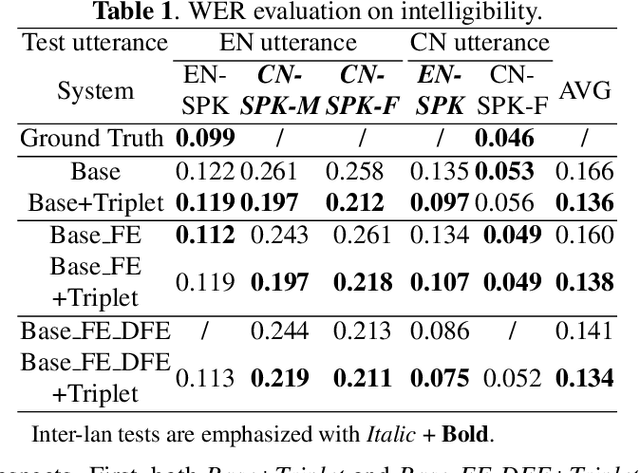
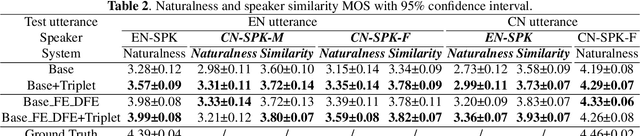
Recent advances in cross-lingual text-to-speech (TTS) made it possible to synthesize speech in a language foreign to a monolingual speaker. However, there is still a large gap between the pronunciation of generated cross-lingual speech and that of native speakers in terms of naturalness and intelligibility. In this paper, a triplet training scheme is proposed to enhance the cross-lingual pronunciation by allowing previously unseen content and speaker combinations to be seen during training. Proposed method introduces an extra fine-tune stage with triplet loss during training, which efficiently draws the pronunciation of the synthesized foreign speech closer to those from the native anchor speaker, while preserving the non-native speaker's timbre. Experiments are conducted based on a state-of-the-art baseline cross-lingual TTS system and its enhanced variants. All the objective and subjective evaluations show the proposed method brings significant improvement in both intelligibility and naturalness of the synthesized cross-lingual speech.