 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeS2ST-Omni: An Efficient and Scalable Multilingual Speech-to-Speech Translation Framework via Seamlessly Speech-Text Alignment and Streaming Speech Decoder
Jun 16, 2025

Multilingual speech-to-speech translation (S2ST) aims to directly convert spoken utterances from multiple source languages into fluent and intelligible speech in a target language. Despite recent progress, several critical challenges persist: 1) achieving high-quality and low-latency S2ST remains a significant obstacle; 2) most existing S2ST methods rely heavily on large-scale parallel speech corpora, which are difficult and resource-intensive to obtain. To tackle these challenges, we introduce S2ST-Omni, a novel, efficient, and scalable framework tailored for multilingual speech-to-speech translation. To enable high-quality S2TT while mitigating reliance on large-scale parallel speech corpora, we leverage powerful pretrained models: Whisper for robust audio understanding and Qwen 3.0 for advanced text comprehension. A lightweight speech adapter is introduced to bridge the modality gap between speech and text representations, facilitating effective utilization of pretrained multimodal knowledge. To ensure both translation accuracy and real-time responsiveness, we adopt a streaming speech decoder in the TTS stage, which generates the target speech in an autoregressive manner. Extensive experiments conducted on the CVSS benchmark demonstrate that S2ST-Omni consistently surpasses several state-of-the-art S2ST baselines in translation quality, highlighting its effectiveness and superiority.
ClapFM-EVC: High-Fidelity and Flexible Emotional Voice Conversion with Dual Control from Natural Language and Speech
May 20, 2025



Despite great advances, achieving high-fidelity emotional voice conversion (EVC) with flexible and interpretable control remains challenging. This paper introduces ClapFM-EVC, a novel EVC framework capable of generating high-quality converted speech driven by natural language prompts or reference speech with adjustable emotion intensity. We first propose EVC-CLAP, an emotional contrastive language-audio pre-training model, guided by natural language prompts and categorical labels, to extract and align fine-grained emotional elements across speech and text modalities. Then, a FuEncoder with an adaptive intensity gate is presented to seamless fuse emotional features with Phonetic PosteriorGrams from a pre-trained ASR model. To further improve emotion expressiveness and speech naturalness, we propose a flow matching model conditioned on these captured features to reconstruct Mel-spectrogram of source speech. Subjective and objective evaluations validate the effectiveness of ClapFM-EVC.
Takin: A Cohort of Superior Quality Zero-shot Speech Generation Models
Sep 18, 2024



With the advent of the big data and large language model era, zero-shot personalized rapid customization has emerged as a significant trend. In this report, we introduce Takin AudioLLM, a series of techniques and models, mainly including Takin TTS, Takin VC, and Takin Morphing, specifically designed for audiobook production. These models are capable of zero-shot speech production, generating high-quality speech that is nearly indistinguishable from real human speech and facilitating individuals to customize the speech content according to their own needs. Specifically, we first introduce Takin TTS, a neural codec language model that builds upon an enhanced neural speech codec and a multi-task training framework, capable of generating high-fidelity natural speech in a zero-shot way. For Takin VC, we advocate an effective content and timbre joint modeling approach to improve the speaker similarity, while advocating for a conditional flow matching based decoder to further enhance its naturalness and expressiveness. Last, we propose the Takin Morphing system with highly decoupled and advanced timbre and prosody modeling approaches, which enables individuals to customize speech production with their preferred timbre and prosody in a precise and controllable manner. Extensive experiments validate the effectiveness and robustness of our Takin AudioLLM series models. For detailed demos, please refer to https://takinaudiollm.github.io.
PP-MeT: a Real-world Personalized Prompt based Meeting Transcription System
Sep 28, 2023



Speaker-attributed automatic speech recognition (SA-ASR) improves the accuracy and applicability of multi-speaker ASR systems in real-world scenarios by assigning speaker labels to transcribed texts. However, SA-ASR poses unique challenges due to factors such as speaker overlap, speaker variability, background noise, and reverberation. In this study, we propose PP-MeT system, a real-world personalized prompt based meeting transcription system, which consists of a clustering system, target-speaker voice activity detection (TS-VAD), and TS-ASR. Specifically, we utilize target-speaker embedding as a prompt in TS-VAD and TS-ASR modules in our proposed system. In constrast with previous system, we fully leverage pre-trained models for system initialization, thereby bestowing our approach with heightened generalizability and precision. Experiments on M2MeT2.0 Challenge dataset show that our system achieves a cp-CER of 11.27% on the test set, ranking first in both fixed and open training conditions.
PromptVC: Flexible Stylistic Voice Conversion in Latent Space Driven by Natural Language Prompts
Sep 17, 2023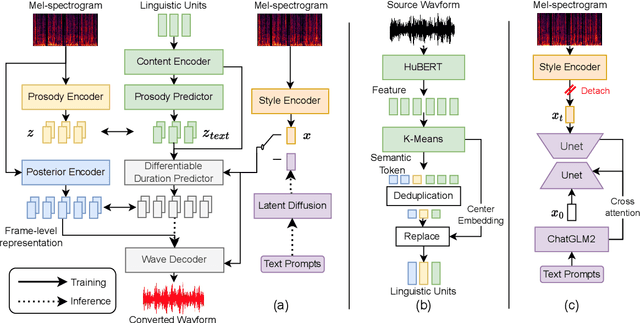

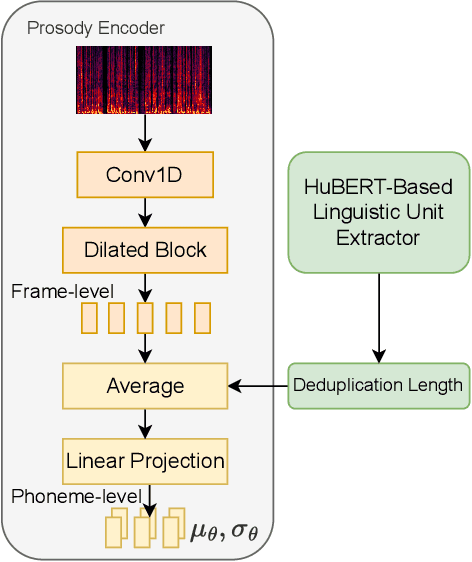
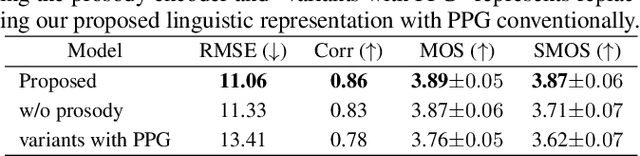
Style voice conversion aims to transform the style of source speech to a desired style according to real-world application demands. However, the current style voice conversion approach relies on pre-defined labels or reference speech to control the conversion process, which leads to limitations in style diversity or falls short in terms of the intuitive and interpretability of style representation. In this study, we propose PromptVC, a novel style voice conversion approach that employs a latent diffusion model to generate a style vector driven by natural language prompts. Specifically, the style vector is extracted by a style encoder during training, and then the latent diffusion model is trained independently to sample the style vector from noise, with this process being conditioned on natural language prompts. To improve style expressiveness, we leverage HuBERT to extract discrete tokens and replace them with the K-Means center embedding to serve as the linguistic content, which minimizes residual style information. Additionally, we deduplicate the same discrete token and employ a differentiable duration predictor to re-predict the duration of each token, which can adapt the duration of the same linguistic content to different styles. The subjective and objective evaluation results demonstrate the effectiveness of our proposed system.
GEmo-CLAP: Gender-Attribute-Enhanced Contrastive Language-Audio Pretraining for Speech Emotion Recognition
Jun 16, 2023



Contrastive learning based pretraining methods have recently exhibited impressive success in diverse fields. In this paper, we propose GEmo-CLAP, a kind of efficient gender-attribute-enhanced contrastive language-audio pretraining (CLAP) model for speech emotion recognition. To be specific, we first build an effective emotion CLAP model Emo-CLAP for emotion recognition, utilizing various self-supervised learning based pre-trained models. Then, considering the importance of the gender attribute in speech emotion modeling, two GEmo-CLAP approaches are further proposed to integrate the emotion and gender information of speech signals, forming more reasonable objectives. Extensive experiments on the IEMOCAP corpus demonstrate that our proposed two GEmo-CLAP approaches consistently outperform the baseline Emo-CLAP with different pre-trained models, while also achieving superior recognition performance compared with other state-of-the-art methods.