 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePromptVC: Flexible Stylistic Voice Conversion in Latent Space Driven by Natural Language Prompts
Paper and Code
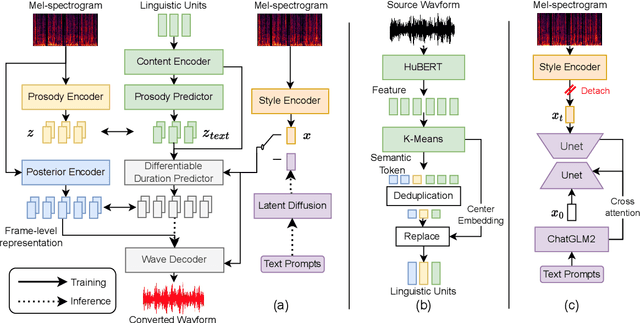

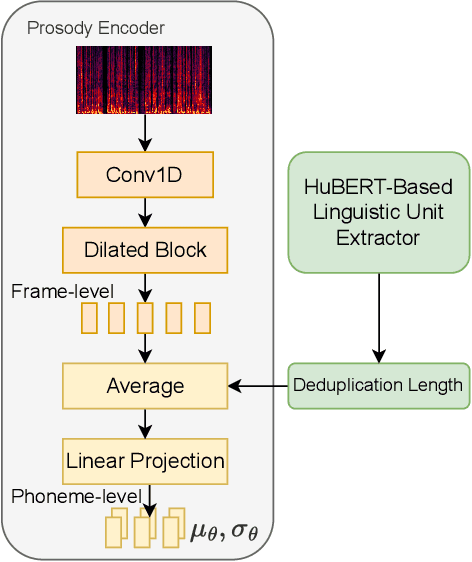
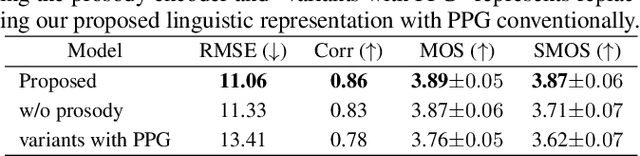
Style voice conversion aims to transform the style of source speech to a desired style according to real-world application demands. However, the current style voice conversion approach relies on pre-defined labels or reference speech to control the conversion process, which leads to limitations in style diversity or falls short in terms of the intuitive and interpretability of style representation. In this study, we propose PromptVC, a novel style voice conversion approach that employs a latent diffusion model to generate a style vector driven by natural language prompts. Specifically, the style vector is extracted by a style encoder during training, and then the latent diffusion model is trained independently to sample the style vector from noise, with this process being conditioned on natural language prompts. To improve style expressiveness, we leverage HuBERT to extract discrete tokens and replace them with the K-Means center embedding to serve as the linguistic content, which minimizes residual style information. Additionally, we deduplicate the same discrete token and employ a differentiable duration predictor to re-predict the duration of each token, which can adapt the duration of the same linguistic content to different styles. The subjective and objective evaluation results demonstrate the effectiveness of our proposed system.