 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJANUS: A Lightweight Framework for Jailbreaking Text-to-Image Models via Distribution Optimization
Mar 22, 2026Text-to-image (T2I) models such as Stable Diffusion and DALLE remain susceptible to generating harmful or Not-Safe-For-Work (NSFW) content under jailbreak attacks despite deployed safety filters. Existing jailbreak attacks either rely on proxy-loss optimization instead of the true end-to-end objective, or depend on large-scale and costly RL-trained generators. Motivated by these limitations, we propose JANUS , a lightweight framework that formulates jailbreak as optimizing a structured prompt distribution under a black-box, end-to-end reward from the T2I system and its safety filters. JANUS replaces a high-capacity generator with a low-dimensional mixing policy over two semantically anchored prompt distributions, enabling efficient exploration while preserving the target semantics. On modern T2I models, we outperform state-of-the-art jailbreak methods, improving ASR-8 from 25.30% to 43.15% on Stable Diffusion 3.5 Large Turbo with consistently higher CLIP and NSFW scores. JANUS succeeds across both open-source and commercial models. These findings expose structural weaknesses in current T2I safety pipelines and motivate stronger, distribution-aware defenses. Warning: This paper contains model outputs that may be offensive.
Explainable Token-level Noise Filtering for LLM Fine-tuning Datasets
Feb 16, 2026Large Language Models (LLMs) have seen remarkable advancements, achieving state-of-the-art results in diverse applications. Fine-tuning, an important step for adapting LLMs to specific downstream tasks, typically involves further training on corresponding datasets. However, a fundamental discrepancy exists between current fine-tuning datasets and the token-level optimization mechanism of LLMs: most datasets are designed at the sentence-level, which introduces token-level noise, causing negative influence to final performance. In this paper, we propose XTF, an explainable token-level noise filtering framework. XTF decomposes the complex and subtle contributions of token-level data to the fine-tuning process into three distinct and explicit attributes (reasoning importance, knowledge novelty, and task relevance), which can be assessed using scoring methods, and then masks the gradients of selected noisy tokens accordingly to optimize the performance of fine-tuned LLMs. We conduct extensive experiments on three representative downstream tasks (math, code and medicine) across 7 mainstream LLMs. The results demonstrate that XTF can significantly improve downstream performance by up to 13.7% compared to regular fine-tuning. Our work highlights the importance of token-level dataset optimization, and demonstrates the potential of strategies based on attribute decomposition for explaining complex training mechanisms.
S2ST-Omni: An Efficient and Scalable Multilingual Speech-to-Speech Translation Framework via Seamlessly Speech-Text Alignment and Streaming Speech Decoder
Jun 16, 2025

Multilingual speech-to-speech translation (S2ST) aims to directly convert spoken utterances from multiple source languages into fluent and intelligible speech in a target language. Despite recent progress, several critical challenges persist: 1) achieving high-quality and low-latency S2ST remains a significant obstacle; 2) most existing S2ST methods rely heavily on large-scale parallel speech corpora, which are difficult and resource-intensive to obtain. To tackle these challenges, we introduce S2ST-Omni, a novel, efficient, and scalable framework tailored for multilingual speech-to-speech translation. To enable high-quality S2TT while mitigating reliance on large-scale parallel speech corpora, we leverage powerful pretrained models: Whisper for robust audio understanding and Qwen 3.0 for advanced text comprehension. A lightweight speech adapter is introduced to bridge the modality gap between speech and text representations, facilitating effective utilization of pretrained multimodal knowledge. To ensure both translation accuracy and real-time responsiveness, we adopt a streaming speech decoder in the TTS stage, which generates the target speech in an autoregressive manner. Extensive experiments conducted on the CVSS benchmark demonstrate that S2ST-Omni consistently surpasses several state-of-the-art S2ST baselines in translation quality, highlighting its effectiveness and superiority.
ClapFM-EVC: High-Fidelity and Flexible Emotional Voice Conversion with Dual Control from Natural Language and Speech
May 20, 2025



Despite great advances, achieving high-fidelity emotional voice conversion (EVC) with flexible and interpretable control remains challenging. This paper introduces ClapFM-EVC, a novel EVC framework capable of generating high-quality converted speech driven by natural language prompts or reference speech with adjustable emotion intensity. We first propose EVC-CLAP, an emotional contrastive language-audio pre-training model, guided by natural language prompts and categorical labels, to extract and align fine-grained emotional elements across speech and text modalities. Then, a FuEncoder with an adaptive intensity gate is presented to seamless fuse emotional features with Phonetic PosteriorGrams from a pre-trained ASR model. To further improve emotion expressiveness and speech naturalness, we propose a flow matching model conditioned on these captured features to reconstruct Mel-spectrogram of source speech. Subjective and objective evaluations validate the effectiveness of ClapFM-EVC.
GDI-Bench: A Benchmark for General Document Intelligence with Vision and Reasoning Decoupling
Apr 30, 2025The rapid advancement of multimodal large language models (MLLMs) has profoundly impacted the document domain, creating a wide array of application scenarios. This progress highlights the need for a comprehensive benchmark to evaluate these models' capabilities across various document-specific tasks. However, existing benchmarks often fail to locate specific model weaknesses or guide systematic improvements. To bridge this gap, we introduce a General Document Intelligence Benchmark (GDI-Bench), featuring 1.9k images across 9 key scenarios and 19 document-specific tasks. By decoupling visual complexity and reasoning complexity, the GDI-Bench structures graded tasks that allow performance assessment by difficulty, aiding in model weakness identification and optimization guidance. We evaluate the GDI-Bench on various open-source and closed-source models, conducting decoupled analyses in the visual and reasoning domains. For instance, the GPT-4o model excels in reasoning tasks but exhibits limitations in visual capabilities. To address the diverse tasks and domains in the GDI-Bench, we propose a GDI Model that mitigates the issue of catastrophic forgetting during the supervised fine-tuning (SFT) process through a intelligence-preserving training strategy. Our model achieves state-of-the-art performance on previous benchmarks and the GDI-Bench. Both our benchmark and model will be open source.
TrustGeoGen: Scalable and Formal-Verified Data Engine for Trustworthy Multi-modal Geometric Problem Solving
Apr 22, 2025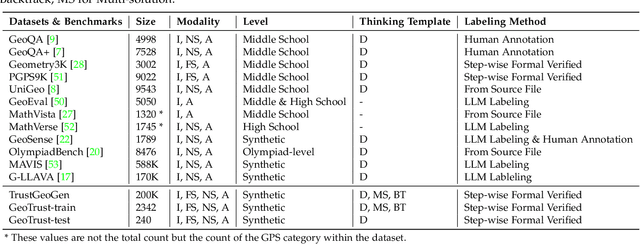
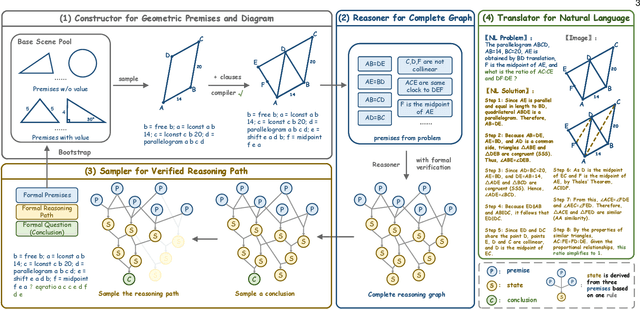
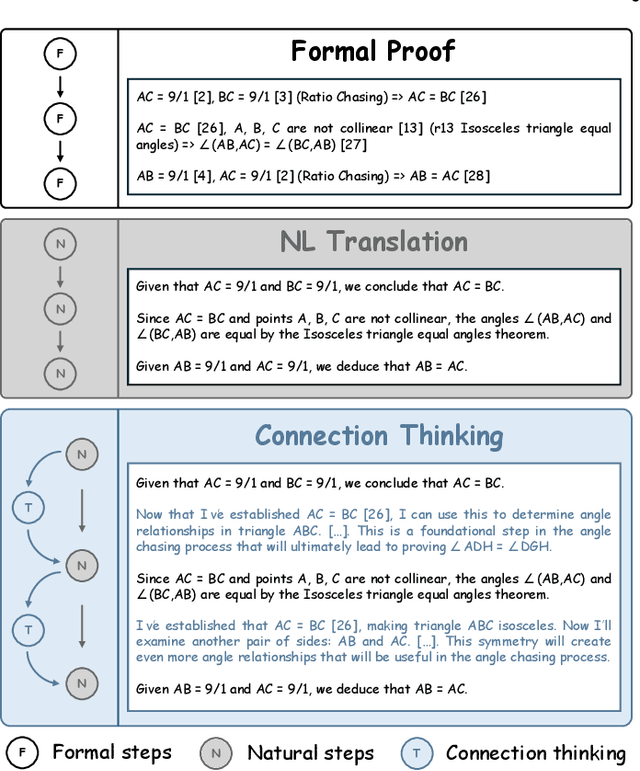
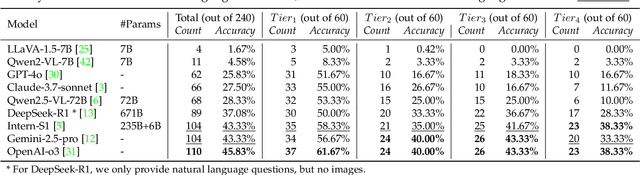
Mathematical geometric problem solving (GPS) often requires effective integration of multimodal information and verifiable logical coherence. Despite the fast development of large language models in general problem solving, it remains unresolved regarding with both methodology and benchmarks, especially given the fact that exiting synthetic GPS benchmarks are often not self-verified and contain noise and self-contradicted information due to the illusion of LLMs. In this paper, we propose a scalable data engine called TrustGeoGen for problem generation, with formal verification to provide a principled benchmark, which we believe lays the foundation for the further development of methods for GPS. The engine synthesizes geometric data through four key innovations: 1) multimodal-aligned generation of diagrams, textual descriptions, and stepwise solutions; 2) formal verification ensuring rule-compliant reasoning paths; 3) a bootstrapping mechanism enabling complexity escalation via recursive state generation and 4) our devised GeoExplore series algorithms simultaneously produce multi-solution variants and self-reflective backtracking traces. By formal logical verification, TrustGeoGen produces GeoTrust-200K dataset with guaranteed modality integrity, along with GeoTrust-test testset. Experiments reveal the state-of-the-art models achieve only 49.17\% accuracy on GeoTrust-test, demonstrating its evaluation stringency. Crucially, models trained on GeoTrust achieve OOD generalization on GeoQA, significantly reducing logical inconsistencies relative to pseudo-label annotated by OpenAI-o1. Our code is available at https://github.com/Alpha-Innovator/TrustGeoGen
Fine-grained Preference Optimization Improves Zero-shot Text-to-Speech
Feb 05, 2025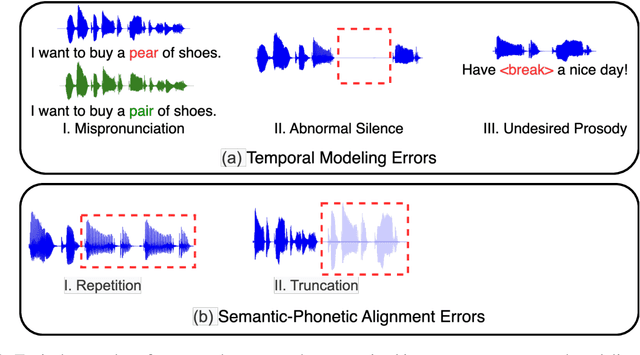
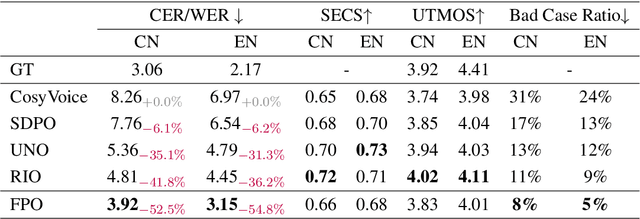
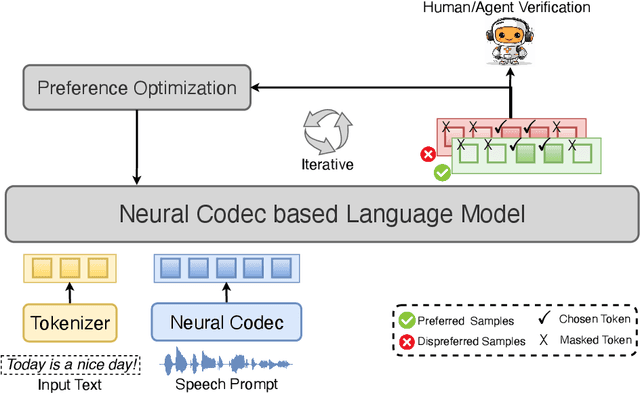
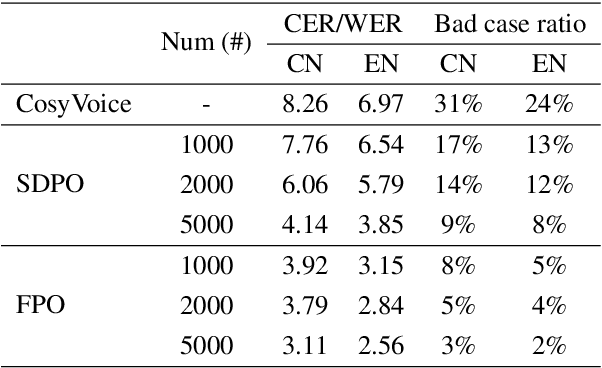
Integrating human feedback to align text-to-speech (TTS) system outputs with human preferences has proven to be an effective approach for enhancing the robustness of language model-based TTS systems. Current approaches primarily focus on using preference data annotated at the utterance level. However, frequent issues that affect the listening experience often only arise in specific segments of audio samples, while other segments are well-generated. In this study, we propose a fine-grained preference optimization approach (FPO) to enhance the robustness of TTS systems. FPO focuses on addressing localized issues in generated samples rather than uniformly optimizing the entire utterance. Specifically, we first analyze the types of issues in generated samples, categorize them into two groups, and propose a selective training loss strategy to optimize preferences based on fine-grained labels for each issue type. Experimental results show that FPO enhances the robustness of zero-shot TTS systems by effectively addressing local issues, significantly reducing the bad case ratio, and improving intelligibility. Furthermore, FPO exhibits superior data efficiency compared with baseline systems, achieving similar performance with fewer training samples.
GeoX: Geometric Problem Solving Through Unified Formalized Vision-Language Pre-training
Dec 16, 2024



Despite their proficiency in general tasks, Multi-modal Large Language Models (MLLMs) struggle with automatic Geometry Problem Solving (GPS), which demands understanding diagrams, interpreting symbols, and performing complex reasoning. This limitation arises from their pre-training on natural images and texts, along with the lack of automated verification in the problem-solving process. Besides, current geometric specialists are limited by their task-specific designs, making them less effective for broader geometric problems. To this end, we present GeoX, a multi-modal large model focusing on geometric understanding and reasoning tasks. Given the significant differences between geometric diagram-symbol and natural image-text, we introduce unimodal pre-training to develop a diagram encoder and symbol decoder, enhancing the understanding of geometric images and corpora. Furthermore, we introduce geometry-language alignment, an effective pre-training paradigm that bridges the modality gap between unimodal geometric experts. We propose a Generator-And-Sampler Transformer (GS-Former) to generate discriminative queries and eliminate uninformative representations from unevenly distributed geometric signals. Finally, GeoX benefits from visual instruction tuning, empowering it to take geometric images and questions as input and generate verifiable solutions. Experiments show that GeoX outperforms both generalists and geometric specialists on publicly recognized benchmarks, such as GeoQA, UniGeo, Geometry3K, and PGPS9k.
StableVC: Style Controllable Zero-Shot Voice Conversion with Conditional Flow Matching
Dec 10, 2024



Zero-shot voice conversion (VC) aims to transfer the timbre from the source speaker to an arbitrary unseen speaker while preserving the original linguistic content. Despite recent advancements in zero-shot VC using language model-based or diffusion-based approaches, several challenges remain: 1) current approaches primarily focus on adapting timbre from unseen speakers and are unable to transfer style and timbre to different unseen speakers independently; 2) these approaches often suffer from slower inference speeds due to the autoregressive modeling methods or the need for numerous sampling steps; 3) the quality and similarity of the converted samples are still not fully satisfactory. To address these challenges, we propose a style controllable zero-shot VC approach named StableVC, which aims to transfer timbre and style from source speech to different unseen target speakers. Specifically, we decompose speech into linguistic content, timbre, and style, and then employ a conditional flow matching module to reconstruct the high-quality mel-spectrogram based on these decomposed features. To effectively capture timbre and style in a zero-shot manner, we introduce a novel dual attention mechanism with an adaptive gate, rather than using conventional feature concatenation. With this non-autoregressive design, StableVC can efficiently capture the intricate timbre and style from different unseen speakers and generate high-quality speech significantly faster than real-time. Experiments demonstrate that our proposed StableVC outperforms state-of-the-art baseline systems in zero-shot VC and achieves flexible control over timbre and style from different unseen speakers. Moreover, StableVC offers approximately 25x and 1.65x faster sampling compared to autoregressive and diffusion-based baselines.
OmniDocBench: Benchmarking Diverse PDF Document Parsing with Comprehensive Annotations
Dec 10, 2024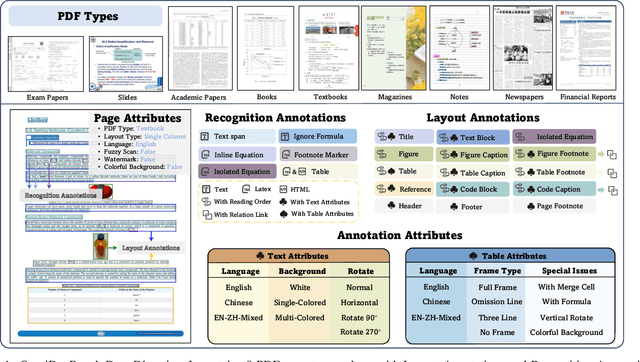
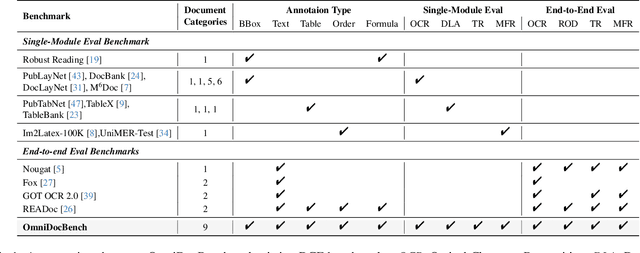
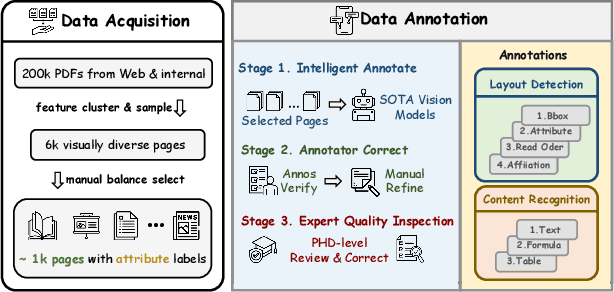
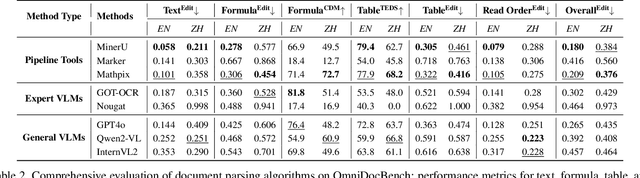
Document content extraction is crucial in computer vision, especially for meeting the high-quality data needs of large language models (LLMs) and retrieval-augmented generation (RAG) technologies. However, current document parsing methods suffer from significant limitations in terms of diversity and comprehensive evaluation. To address these challenges, we introduce OmniDocBench, a novel multi-source benchmark designed to advance automated document content extraction. OmniDocBench includes a meticulously curated and annotated high-quality evaluation dataset comprising nine diverse document types, such as academic papers, textbooks, slides, among others. Our benchmark provides a flexible and comprehensive evaluation framework with 19 layout category labels and 14 attribute labels, enabling multi-level assessments across entire datasets, individual modules, or specific data types. Using OmniDocBench, we perform an exhaustive comparative analysis of existing modular pipelines and multimodal end-to-end methods, highlighting their limitations in handling document diversity and ensuring fair evaluation. OmniDocBench establishes a robust, diverse, and fair evaluation standard for the document content extraction field, offering crucial insights for future advancements and fostering the development of document parsing technologies. The codes and dataset is available in https://github.com/opendatalab/OmniDocBench.