 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Bioinspired Underwater Robot with a Latch-Mediated Soft Bistable Mechanism
May 26, 2026Underwater robotics has advanced significantly over recent decades. however, the development of miniaturized underwater robots remains limited by low energy densities of traditional power sources. Nature offers compelling solutions-organisms like mantis shrimps and fleas utilize latch-mediated spring actuation (LaMSA) systems that achieve rapid movements through a decoupled energy storage and release mechanism. Despite extensive studies of LaMSA, replicating such rapid, asymmetric actuation within simple, compact structures remains challenging. In this work, we introduce a bioinspired, soft bistable actuator with an integrated latch mechanism that enables asymmetric energy input and release using a single motor. Coupled with fin structures, this design facilitates efficient underwater propulsion and maneuverability. Experimental results demonstrate stable periodic flapping, precise steering, and a maximum thrust of 0.528 N, impulse of 0.147 Ns, and vertical displacement of 30 mm. By modulating fin angles, the robot achieves versatile motions, including vertical ascent, diagonal forward movement, and lateral translation. This study presents a novel, energy-efficient approach for controlling motion in compact underwater robots, paving the way for advanced biomimetic designs with potential applications in exploration, environmental monitoring, and inspection.
From Flat Logs to Causal Graphs: Hierarchical Failure Attribution for LLM-based Multi-Agent Systems
Feb 27, 2026LLM-powered Multi-Agent Systems (MAS) have demonstrated remarkable capabilities in complex domains but suffer from inherent fragility and opaque failure mechanisms. Existing failure attribution methods, whether relying on direct prompting, costly replays, or supervised fine-tuning, typically treat execution logs as flat sequences. This linear perspective fails to disentangle the intricate causal links inherent to MAS, leading to weak observability and ambiguous responsibility boundaries. To address these challenges, we propose CHIEF, a novel framework that transforms chaotic trajectories into a structured hierarchical causal graph. It then employs hierarchical oracle-guided backtracking to efficiently prune the search space via sybthesized virtual oracles. Finally, it implements counterfactual attribution via a progressive causal screening strategy to rigorously distinguish true root causes from propagated symptoms. Experiments on Who&When benchmark show that CHIEF outperforms eight strong and state-of-the-art baselines on both agent- and step-level accuracy. Ablation studies further confirm the critical role of each proposed module.
S-GRec: Personalized Semantic-Aware Generative Recommendation with Asymmetric Advantage
Feb 12, 2026Generative recommendation models sequence generation to produce items end-to-end, but training from behavioral logs often provides weak supervision on underlying user intent. Although Large Language Models (LLMs) offer rich semantic priors that could supply such supervision, direct adoption in industrial recommendation is hindered by two obstacles: semantic signals can conflict with platform business objectives, and LLM inference is prohibitively expensive at scale. This paper presents S-GRec, a semantic-aware framework that decouples an online lightweight generator from an offline LLM-based semantic judge for train-time supervision. S-GRec introduces a two-stage Personalized Semantic Judge (PSJ) that produces interpretable aspect evidence and learns user-conditional aggregation from pairwise feedback, yielding stable semantic rewards. To prevent semantic supervision from deviating from business goals, Asymmetric Advantage Policy Optimization (A2PO) anchors optimization on business rewards (e.g., eCPM) and injects semantic advantages only when they are consistent. Extensive experiments on public benchmarks and a large-scale production system validate both effectiveness and scalability, including statistically significant gains in CTR and a 1.19\% lift in GMV in online A/B tests, without requiring real-time LLM inference.
Particle Hit Clustering and Identification Using Point Set Transformers in Liquid Argon Time Projection Chambers
Apr 11, 2025Liquid argon time projection chambers are often used in neutrino physics and dark-matter searches because of their high spatial resolution. The images generated by these detectors are extremely sparse, as the energy values detected by most of the detector are equal to 0, meaning that despite their high resolution, most of the detector is unused in a particular interaction. Instead of representing all of the empty detections, the interaction is usually stored as a sparse matrix, a list of detection locations paired with their energy values. Traditional machine learning methods that have been applied to particle reconstruction such as convolutional neural networks (CNNs), however, cannot operate over data stored in this way and therefore must have the matrix fully instantiated as a dense matrix. Operating on dense matrices requires a lot of memory and computation time, in contrast to directly operating on the sparse matrix. We propose a machine learning model using a point set neural network that operates over a sparse matrix, greatly improving both processing speed and accuracy over methods that instantiate the dense matrix, as well as over other methods that operate over sparse matrices. Compared to competing state-of-the-art methods, our method improves classification performance by 14%, segmentation performance by more than 22%, while taking 80% less time and using 66% less memory. Compared to state-of-the-art CNN methods, our method improves classification performance by more than 86%, segmentation performance by more than 71%, while reducing runtime by 91% and reducing memory usage by 61%.
Benchmarking Reasoning Robustness in Large Language Models
Mar 06, 2025Despite the recent success of large language models (LLMs) in reasoning such as DeepSeek, we for the first time identify a key dilemma in reasoning robustness and generalization: significant performance degradation on novel or incomplete data, suggesting a reliance on memorized patterns rather than systematic reasoning. Our closer examination reveals four key unique limitations underlying this issue:(1) Positional bias--models favor earlier queries in multi-query inputs but answering the wrong one in the latter (e.g., GPT-4o's accuracy drops from 75.8 percent to 72.8 percent); (2) Instruction sensitivity--performance declines by 5.0 to 7.5 percent in the Qwen2.5 Series and by 5.0 percent in DeepSeek-V3 with auxiliary guidance; (3) Numerical fragility--value substitution sharply reduces accuracy (e.g., GPT-4o drops from 97.5 percent to 82.5 percent, GPT-o1-mini drops from 97.5 percent to 92.5 percent); and (4) Memory dependence--models resort to guesswork when missing critical data. These findings further highlight the reliance on heuristic recall over rigorous logical inference, demonstrating challenges in reasoning robustness. To comprehensively investigate these robustness challenges, this paper introduces a novel benchmark, termed as Math-RoB, that exploits hallucinations triggered by missing information to expose reasoning gaps. This is achieved by an instruction-based approach to generate diverse datasets that closely resemble training distributions, facilitating a holistic robustness assessment and advancing the development of more robust reasoning frameworks. Bad character(s) in field Abstract.
Graph-Augmented Reasoning: Evolving Step-by-Step Knowledge Graph Retrieval for LLM Reasoning
Mar 03, 2025



Recent large language model (LLM) reasoning, despite its success, suffers from limited domain knowledge, susceptibility to hallucinations, and constrained reasoning depth, particularly in small-scale models deployed in resource-constrained environments. This paper presents the first investigation into integrating step-wise knowledge graph retrieval with step-wise reasoning to address these challenges, introducing a novel paradigm termed as graph-augmented reasoning. Our goal is to enable frozen, small-scale LLMs to retrieve and process relevant mathematical knowledge in a step-wise manner, enhancing their problem-solving abilities without additional training. To this end, we propose KG-RAR, a framework centered on process-oriented knowledge graph construction, a hierarchical retrieval strategy, and a universal post-retrieval processing and reward model (PRP-RM) that refines retrieved information and evaluates each reasoning step. Experiments on the Math500 and GSM8K benchmarks across six models demonstrate that KG-RAR yields encouraging results, achieving a 20.73\% relative improvement with Llama-3B on Math500.
Random Forest-of-Thoughts: Uncertainty-aware Reasoning for Computational Social Science
Feb 26, 2025



Social surveys in computational social science are well-designed by elaborate domain theories that can effectively reflect the interviewee's deep thoughts without concealing their true feelings. The candidate questionnaire options highly depend on the interviewee's previous answer, which results in the complexity of social survey analysis, the time, and the expertise required. The ability of large language models (LLMs) to perform complex reasoning is well-enhanced by prompting learning such as Chain-of-thought (CoT) but still confined to left-to-right decision-making processes or limited paths during inference. This means they can fall short in problems that require exploration and uncertainty searching. In response, a novel large language model prompting method, called Random Forest of Thoughts (RFoT), is proposed for generating uncertainty reasoning to fit the area of computational social science. The RFoT allows LLMs to perform deliberate decision-making by generating diverse thought space and randomly selecting the sub-thoughts to build the forest of thoughts. It can extend the exploration and prediction of overall performance, benefiting from the extensive research space of response. The method is applied to optimize computational social science analysis on two datasets covering a spectrum of social survey analysis problems. Our experiments show that RFoT significantly enhances language models' abilities on two novel social survey analysis problems requiring non-trivial reasoning.
GeoX: Geometric Problem Solving Through Unified Formalized Vision-Language Pre-training
Dec 16, 2024



Despite their proficiency in general tasks, Multi-modal Large Language Models (MLLMs) struggle with automatic Geometry Problem Solving (GPS), which demands understanding diagrams, interpreting symbols, and performing complex reasoning. This limitation arises from their pre-training on natural images and texts, along with the lack of automated verification in the problem-solving process. Besides, current geometric specialists are limited by their task-specific designs, making them less effective for broader geometric problems. To this end, we present GeoX, a multi-modal large model focusing on geometric understanding and reasoning tasks. Given the significant differences between geometric diagram-symbol and natural image-text, we introduce unimodal pre-training to develop a diagram encoder and symbol decoder, enhancing the understanding of geometric images and corpora. Furthermore, we introduce geometry-language alignment, an effective pre-training paradigm that bridges the modality gap between unimodal geometric experts. We propose a Generator-And-Sampler Transformer (GS-Former) to generate discriminative queries and eliminate uninformative representations from unevenly distributed geometric signals. Finally, GeoX benefits from visual instruction tuning, empowering it to take geometric images and questions as input and generate verifiable solutions. Experiments show that GeoX outperforms both generalists and geometric specialists on publicly recognized benchmarks, such as GeoQA, UniGeo, Geometry3K, and PGPS9k.
MathLearner: A Large Language Model Agent Framework for Learning to Solve Mathematical Problems
Aug 03, 2024



With the development of artificial intelligence (AI), large language models (LLM) are widely used in many fields. However, the reasoning ability of LLM is still very limited when it comes to mathematical reasoning. Mathematics plays an important role in all aspects of human society and is a technical guarantee in the fields of healthcare, transport and aerospace, for this reason, the development of AI big language models in the field of mathematics has great potential significance. To improve the mathematical reasoning ability of large language models, we proposed an agent framework for learning to solve mathematical problems based on inductive reasoning. By emulating the human learning process of generalization of learned information and effective application of previous knowledge in new reasoning tasks, this framework has great performance in the mathematical reasoning process. It improves global accuracy over the baseline method (chain-of-thought) by 20.96% and solves 17.54% of the mathematical problems that the baseline cannot solve. Benefiting from the efficient RETRIEVAL method, our model improves the ability of large language models to efficiently use external knowledge, i.e., the mathematical computation of the model can be based on written procedures. In education, our model can be used as a personalised learning aid, thus reducing the inequality of educational resources.
DocGenome: An Open Large-scale Scientific Document Benchmark for Training and Testing Multi-modal Large Language Models
Jun 17, 2024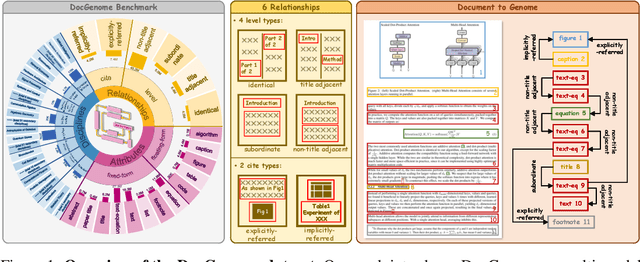
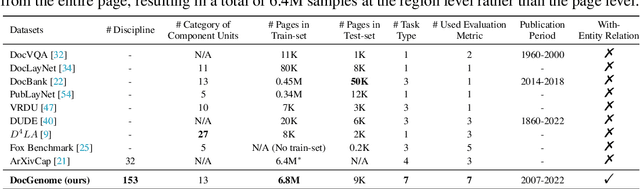
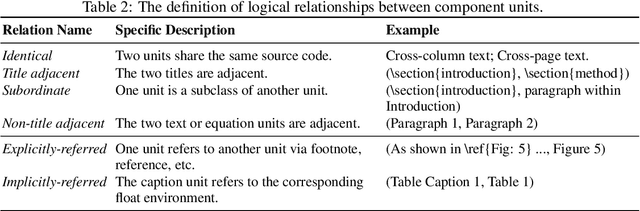
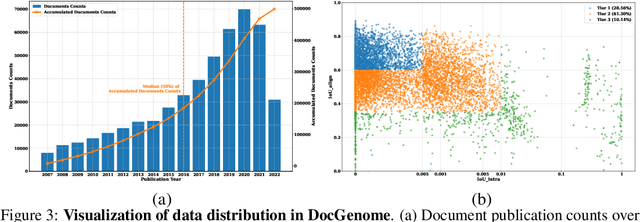
Scientific documents record research findings and valuable human knowledge, comprising a vast corpus of high-quality data. Leveraging multi-modality data extracted from these documents and assessing large models' abilities to handle scientific document-oriented tasks is therefore meaningful. Despite promising advancements, large models still perform poorly on multi-page scientific document extraction and understanding tasks, and their capacity to process within-document data formats such as charts and equations remains under-explored. To address these issues, we present DocGenome, a structured document benchmark constructed by annotating 500K scientific documents from 153 disciplines in the arXiv open-access community, using our custom auto-labeling pipeline. DocGenome features four key characteristics: 1) Completeness: It is the first dataset to structure data from all modalities including 13 layout attributes along with their LaTeX source codes. 2) Logicality: It provides 6 logical relationships between different entities within each scientific document. 3) Diversity: It covers various document-oriented tasks, including document classification, visual grounding, document layout detection, document transformation, open-ended single-page QA and multi-page QA. 4) Correctness: It undergoes rigorous quality control checks conducted by a specialized team. We conduct extensive experiments to demonstrate the advantages of DocGenome and objectively evaluate the performance of large models on our benchmark.