 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDet-SAM2:Technical Report on the Self-Prompting Segmentation Framework Based on Segment Anything Model 2
Dec 02, 2024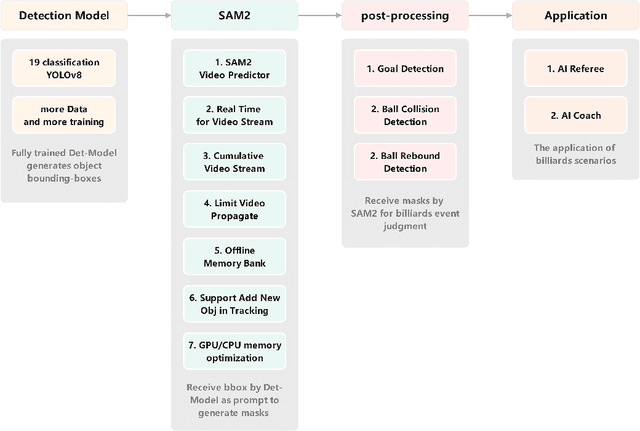

Segment Anything Model 2 (SAM2) demonstrates exceptional performance in video segmentation and refinement of segmentation results. We anticipate that it can further evolve to achieve higher levels of automation for practical applications. Building upon SAM2, we conducted a series of practices that ultimately led to the development of a fully automated pipeline, termed Det-SAM2, in which object prompts are automatically generated by a detection model to facilitate inference and refinement by SAM2. This pipeline enables inference on infinitely long video streams with constant VRAM and RAM usage, all while preserving the same efficiency and accuracy as the original SAM2. This technical report focuses on the construction of the overall Det-SAM2 framework and the subsequent engineering optimization applied to SAM2. We present a case demonstrating an application built on the Det-SAM2 framework: AI refereeing in a billiards scenario, derived from our business context. The project at \url{https://github.com/motern88/Det-SAM2}.
MathLearner: A Large Language Model Agent Framework for Learning to Solve Mathematical Problems
Aug 03, 2024



With the development of artificial intelligence (AI), large language models (LLM) are widely used in many fields. However, the reasoning ability of LLM is still very limited when it comes to mathematical reasoning. Mathematics plays an important role in all aspects of human society and is a technical guarantee in the fields of healthcare, transport and aerospace, for this reason, the development of AI big language models in the field of mathematics has great potential significance. To improve the mathematical reasoning ability of large language models, we proposed an agent framework for learning to solve mathematical problems based on inductive reasoning. By emulating the human learning process of generalization of learned information and effective application of previous knowledge in new reasoning tasks, this framework has great performance in the mathematical reasoning process. It improves global accuracy over the baseline method (chain-of-thought) by 20.96% and solves 17.54% of the mathematical problems that the baseline cannot solve. Benefiting from the efficient RETRIEVAL method, our model improves the ability of large language models to efficiently use external knowledge, i.e., the mathematical computation of the model can be based on written procedures. In education, our model can be used as a personalised learning aid, thus reducing the inequality of educational resources.
HiLight: Technical Report on the Motern AI Video Language Model
Jul 11, 2024


This technical report presents the implementation of a state-of-the-art video encoder for video-text modal alignment and a video conversation framework called HiLight, which features dual visual towers. The work is divided into two main parts: 1.alignment of video and text modalities; 2.convenient and efficient way to interact with users. Our goal is to address the task of video comprehension in the context of billiards. The report includes a discussion of the concepts and the final solution developed during the task's implementation.