 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructural Controllability of Large-Scale Hypergraphs
Mar 20, 2026Controlling real-world networked systems, including ecological, biomedical, and engineered networks that exhibit higher-order interactions, remains challenging due to inherent nonlinearities and large system scales. Despite extensive studies on graph controllability, the controllability properties of hypergraphs remain largely underdeveloped. Existing results focus primarily on exact controllability, which is often impractical for large-scale hypergraphs. In this article, we develop a structural controllability framework for hypergraphs by modeling hypergraph dynamics as polynomial dynamical systems. In particular, we extend classical notions of accessibility and dilation from linear graph-based systems to polynomial hypergraph dynamics and establish a hypergraph-based criterion under which the topology guarantees satisfaction of classical Lie-algebraic and Kalman-type rank conditions for almost all parameter choices. We further derive a topology-based lower bound on the minimum number of driver nodes required for structural controllability and leverage this bound to design a scalable driver node selection algorithm combining dilation-aware initialization via maximum matching with greedy accessibility expansion. We demonstrate the effectiveness and scalability of the proposed framework through numerical experiments on hypergraphs with tens to thousands of nodes and higher-order interactions.
SCOPE: Compress Mathematical Reasoning Steps for Efficient Automated Process Annotation
May 20, 2025



Process Reward Models (PRMs) have demonstrated promising results in mathematical reasoning, but existing process annotation approaches, whether through human annotations or Monte Carlo simulations, remain computationally expensive. In this paper, we introduce Step COmpression for Process Estimation (SCOPE), a novel compression-based approach that significantly reduces annotation costs. We first translate natural language reasoning steps into code and normalize them through Abstract Syntax Tree, then merge equivalent steps to construct a prefix tree. Unlike simulation-based methods that waste numerous samples on estimation, SCOPE leverages a compression-based prefix tree where each root-to-leaf path serves as a training sample, reducing the complexity from $O(NMK)$ to $O(N)$. We construct a large-scale dataset containing 196K samples with only 5% of the computational resources required by previous methods. Empirical results demonstrate that PRMs trained on our dataset consistently outperform existing automated annotation approaches on both Best-of-N strategy and ProcessBench.
Efficient Process Reward Model Training via Active Learning
Apr 14, 2025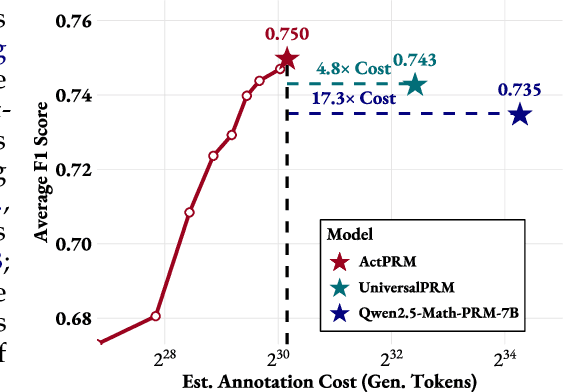
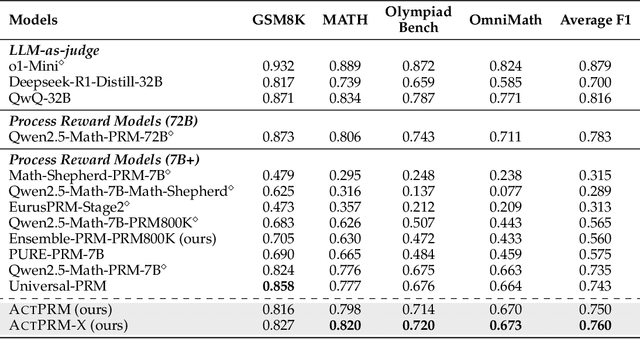
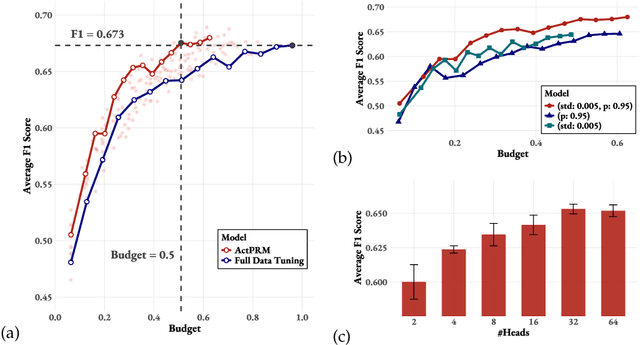
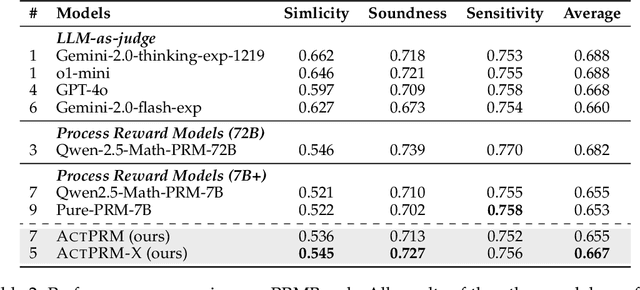
Process Reward Models (PRMs) provide step-level supervision to large language models (LLMs), but scaling up training data annotation remains challenging for both humans and LLMs. To address this limitation, we propose an active learning approach, ActPRM, which proactively selects the most uncertain samples for training, substantially reducing labeling costs. During training, we use the PRM to estimate uncertainty after the forward pass, retaining only highly uncertain data. A capable yet costly reasoning model then labels this data. Then we compute the loss with respect to the labels and update the PRM's weights. We compare ActPRM vs. vanilla fine-tuning, on a pool-based active learning setting, demonstrating that ActPRM reduces 50% annotation, but achieving the comparable or even better performance. Beyond annotation efficiency, we further advance the actively trained PRM by filtering over 1M+ math reasoning trajectories with ActPRM, retaining 60% of the data. A subsequent training on this selected dataset yields a new state-of-the-art (SOTA) PRM on ProcessBench (75.0%) and PRMBench (65.5%) compared with same sized models.
Full-Step-DPO: Self-Supervised Preference Optimization with Step-wise Rewards for Mathematical Reasoning
Feb 20, 2025Direct Preference Optimization (DPO) often struggles with long-chain mathematical reasoning. Existing approaches, such as Step-DPO, typically improve this by focusing on the first erroneous step in the reasoning chain. However, they overlook all other steps and rely heavily on humans or GPT-4 to identify erroneous steps. To address these issues, we propose Full-Step-DPO, a novel DPO framework tailored for mathematical reasoning. Instead of optimizing only the first erroneous step, it leverages step-wise rewards from the entire reasoning chain. This is achieved by training a self-supervised process reward model, which automatically scores each step, providing rewards while avoiding reliance on external signals. Furthermore, we introduce a novel step-wise DPO loss, which dynamically updates gradients based on these step-wise rewards. This endows stronger reasoning capabilities to language models. Extensive evaluations on both in-domain and out-of-domain mathematical reasoning benchmarks across various base language models, demonstrate that Full-Step-DPO achieves superior performance compared to state-of-the-art baselines.
Sailor2: Sailing in South-East Asia with Inclusive Multilingual LLMs
Feb 18, 2025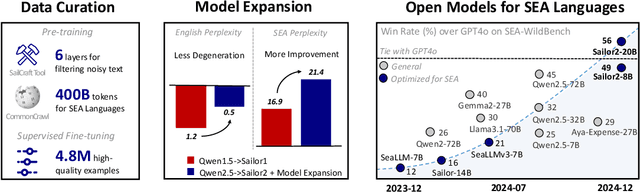
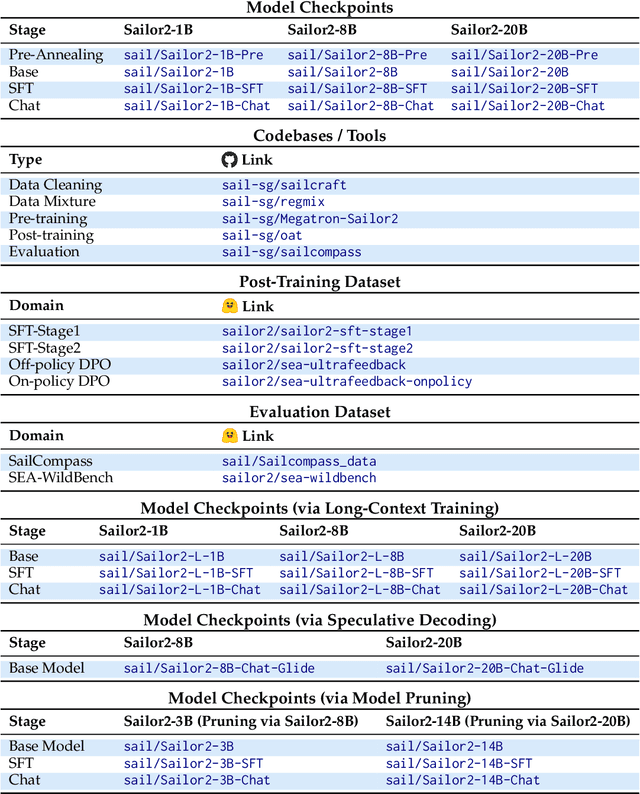

Sailor2 is a family of cutting-edge multilingual language models for South-East Asian (SEA) languages, available in 1B, 8B, and 20B sizes to suit diverse applications. Building on Qwen2.5, Sailor2 undergoes continuous pre-training on 500B tokens (400B SEA-specific and 100B replay tokens) to support 13 SEA languages while retaining proficiency in Chinese and English. Sailor2-20B model achieves a 50-50 win rate against GPT-4o across SEA languages. We also deliver a comprehensive cookbook on how to develop the multilingual model in an efficient manner, including five key aspects: data curation, pre-training, post-training, model customization and evaluation. We hope that Sailor2 model (Apache 2.0 license) will drive language development in the SEA region, and Sailor2 cookbook will inspire researchers to build more inclusive LLMs for other under-served languages.
As Simple as Fine-tuning: LLM Alignment via Bidirectional Negative Feedback Loss
Oct 07, 2024



Direct Preference Optimization (DPO) has emerged as a more computationally efficient alternative to Reinforcement Learning from Human Feedback (RLHF) with Proximal Policy Optimization (PPO), eliminating the need for reward models and online sampling. Despite these benefits, DPO and its variants remain sensitive to hyper-parameters and prone to instability, particularly on mathematical datasets. We argue that these issues arise from the unidirectional likelihood-derivative negative feedback inherent in the log-likelihood loss function. To address this, we propose a novel LLM alignment loss that establishes a stable Bidirectional Negative Feedback (BNF) during optimization. Our proposed BNF loss eliminates the need for pairwise contrastive losses and does not require any extra tunable hyper-parameters or pairwise preference data, streamlining the alignment pipeline to be as simple as supervised fine-tuning. We conduct extensive experiments across two challenging QA benchmarks and four reasoning benchmarks. The experimental results show that BNF achieves comparable performance to the best methods on QA benchmarks, while its performance decrease on the four reasoning benchmarks is significantly lower compared to the best methods, thus striking a better balance between value alignment and reasoning ability. In addition, we further validate the performance of BNF on non-pairwise datasets, and conduct in-depth analysis of log-likelihood and logit shifts across different preference optimization methods.
HiLight: Technical Report on the Motern AI Video Language Model
Jul 11, 2024


This technical report presents the implementation of a state-of-the-art video encoder for video-text modal alignment and a video conversation framework called HiLight, which features dual visual towers. The work is divided into two main parts: 1.alignment of video and text modalities; 2.convenient and efficient way to interact with users. Our goal is to address the task of video comprehension in the context of billiards. The report includes a discussion of the concepts and the final solution developed during the task's implementation.
A Survey on Temporal Knowledge Graph: Representation Learning and Applications
Mar 02, 2024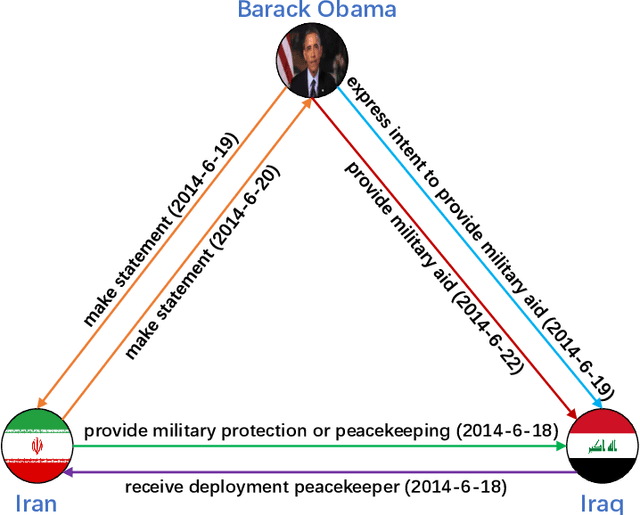
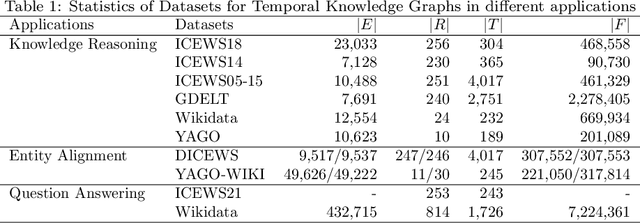
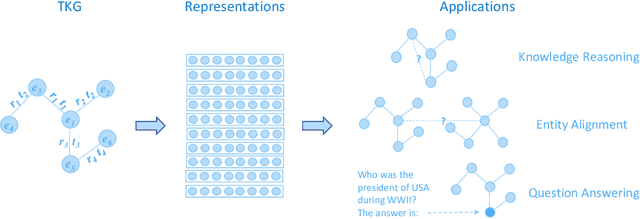

Knowledge graphs have garnered significant research attention and are widely used to enhance downstream applications. However, most current studies mainly focus on static knowledge graphs, whose facts do not change with time, and disregard their dynamic evolution over time. As a result, temporal knowledge graphs have attracted more attention because a large amount of structured knowledge exists only within a specific period. Knowledge graph representation learning aims to learn low-dimensional vector embeddings for entities and relations in a knowledge graph. The representation learning of temporal knowledge graphs incorporates time information into the standard knowledge graph framework and can model the dynamics of entities and relations over time. In this paper, we conduct a comprehensive survey of temporal knowledge graph representation learning and its applications. We begin with an introduction to the definitions, datasets, and evaluation metrics for temporal knowledge graph representation learning. Next, we propose a taxonomy based on the core technologies of temporal knowledge graph representation learning methods, and provide an in-depth analysis of different methods in each category. Finally, we present various downstream applications related to the temporal knowledge graphs. In the end, we conclude the paper and have an outlook on the future research directions in this area.
Temporal Knowledge Graph Completion with Time-sensitive Relations in Hypercomplex Space
Mar 02, 2024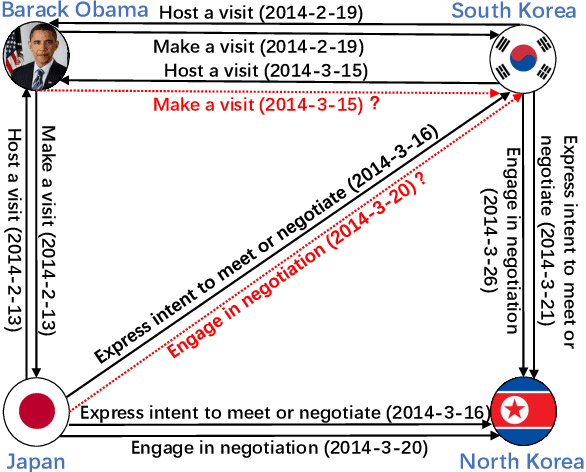

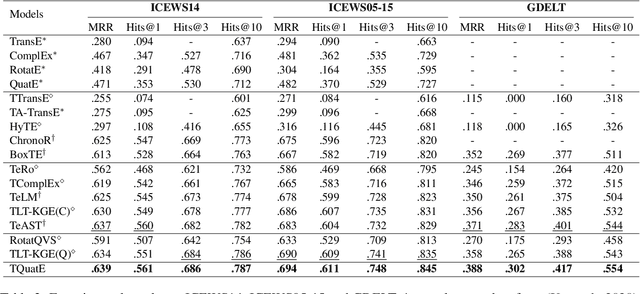
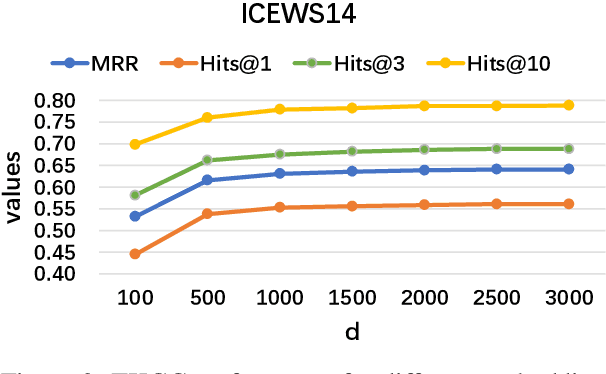
Temporal knowledge graph completion (TKGC) aims to fill in missing facts within a given temporal knowledge graph at a specific time. Existing methods, operating in real or complex spaces, have demonstrated promising performance in this task. This paper advances beyond conventional approaches by introducing more expressive quaternion representations for TKGC within hypercomplex space. Unlike existing quaternion-based methods, our study focuses on capturing time-sensitive relations rather than time-aware entities. Specifically, we model time-sensitive relations through time-aware rotation and periodic time translation, effectively capturing complex temporal variability. Furthermore, we theoretically demonstrate our method's capability to model symmetric, asymmetric, inverse, compositional, and evolutionary relation patterns. Comprehensive experiments on public datasets validate that our proposed approach achieves state-of-the-art performance in the field of TKGC.
Don't Forget Your Reward Values: Language Model Alignment via Value-based Calibration
Feb 25, 2024



While Reinforcement Learning from Human Feedback (RLHF) significantly enhances the generation quality of Large Language Models (LLMs), recent studies have raised concerns regarding the complexity and instability associated with the Proximal Policy Optimization (PPO) algorithm, proposing a series of order-based calibration methods as viable alternatives. This paper delves further into current order-based methods, examining their inefficiencies in utilizing reward values and addressing misalignment issues. Building upon these findings, we propose a novel \textbf{V}alue-based \textbf{C}ali\textbf{B}ration (VCB) method to better align LLMs with human preferences. Experimental results demonstrate that VCB surpasses existing alignment methods on AI assistant and summarization datasets, providing impressive generalizability, robustness, and stability in diverse settings.