 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding and Preventing Entropy Collapse in RLVR with On-Policy Entropy Flow Optimization
May 12, 2026Reinforcement learning with verifiable rewards (RLVR) has become an effective paradigm for improving the reasoning ability of large language models. However, widely used RLVR algorithms, such as GRPO, often suffer from entropy collapse, leading to premature determinism and unstable optimization. Existing remedies, including entropy regularization and ratio-based clipping heuristics, either control entropy in a coarse-grained manner or rely on approximate on-policy training. In this paper, we revisit entropy collapse from a token-level entropy flow perspective. Our analysis reveals that entropy-decreasing tokens consistently outweigh entropy-increasing ones, resulting in a severely imbalanced entropy flow. This perspective provides a unified explanation of entropy collapse in existing RLVR algorithms and highlights the importance of balancing entropy dynamics. Motivated by this analysis, we propose On-Policy Entropy Flow Optimization (OPEFO), an adaptive entropy flow balancing mechanism that rescales entropy-increasing and entropy-decreasing updates according to their contributions to entropy change, while remaining strict on-policy. Experiments on six mathematical reasoning benchmarks demonstrate that OPEFO improves training stability and final performance. We will release the code and models upon publication.
Automated Thematic Analysis for Clinical Qualitative Data: Iterative Codebook Refinement with Full Provenance
Mar 09, 2026Thematic analysis (TA) is widely used in health research to extract patterns from patient interviews, yet manual TA faces challenges in scalability and reproducibility. LLM-based automation can help, but existing approaches produce codebooks with limited generalizability and lack analytic auditability. We present an automated TA framework combining iterative codebook refinement with full provenance tracking. Evaluated on five corpora spanning clinical interviews, social media, and public transcripts, the framework achieves the highest composite quality score on four of five datasets compared to six baselines. Iterative refinement yields statistically significant improvements on four datasets with large effect sizes, driven by gains in code reusability and distributional consistency while preserving descriptive quality. On two clinical corpora (pediatric cardiology), generated themes align with expert-annotated themes.
SCOPE: Compress Mathematical Reasoning Steps for Efficient Automated Process Annotation
May 20, 2025



Process Reward Models (PRMs) have demonstrated promising results in mathematical reasoning, but existing process annotation approaches, whether through human annotations or Monte Carlo simulations, remain computationally expensive. In this paper, we introduce Step COmpression for Process Estimation (SCOPE), a novel compression-based approach that significantly reduces annotation costs. We first translate natural language reasoning steps into code and normalize them through Abstract Syntax Tree, then merge equivalent steps to construct a prefix tree. Unlike simulation-based methods that waste numerous samples on estimation, SCOPE leverages a compression-based prefix tree where each root-to-leaf path serves as a training sample, reducing the complexity from $O(NMK)$ to $O(N)$. We construct a large-scale dataset containing 196K samples with only 5% of the computational resources required by previous methods. Empirical results demonstrate that PRMs trained on our dataset consistently outperform existing automated annotation approaches on both Best-of-N strategy and ProcessBench.
TAMA: A Human-AI Collaborative Thematic Analysis Framework Using Multi-Agent LLMs for Clinical Interviews
Mar 26, 2025Thematic analysis (TA) is a widely used qualitative approach for uncovering latent meanings in unstructured text data. TA provides valuable insights in healthcare but is resource-intensive. Large Language Models (LLMs) have been introduced to perform TA, yet their applications in healthcare remain unexplored. Here, we propose TAMA: A Human-AI Collaborative Thematic Analysis framework using Multi-Agent LLMs for clinical interviews. We leverage the scalability and coherence of multi-agent systems through structured conversations between agents and coordinate the expertise of cardiac experts in TA. Using interview transcripts from parents of children with Anomalous Aortic Origin of a Coronary Artery (AAOCA), a rare congenital heart disease, we demonstrate that TAMA outperforms existing LLM-assisted TA approaches, achieving higher thematic hit rate, coverage, and distinctiveness. TAMA demonstrates strong potential for automated TA in clinical settings by leveraging multi-agent LLM systems with human-in-the-loop integration by enhancing quality while significantly reducing manual workload.
Full-Step-DPO: Self-Supervised Preference Optimization with Step-wise Rewards for Mathematical Reasoning
Feb 20, 2025Direct Preference Optimization (DPO) often struggles with long-chain mathematical reasoning. Existing approaches, such as Step-DPO, typically improve this by focusing on the first erroneous step in the reasoning chain. However, they overlook all other steps and rely heavily on humans or GPT-4 to identify erroneous steps. To address these issues, we propose Full-Step-DPO, a novel DPO framework tailored for mathematical reasoning. Instead of optimizing only the first erroneous step, it leverages step-wise rewards from the entire reasoning chain. This is achieved by training a self-supervised process reward model, which automatically scores each step, providing rewards while avoiding reliance on external signals. Furthermore, we introduce a novel step-wise DPO loss, which dynamically updates gradients based on these step-wise rewards. This endows stronger reasoning capabilities to language models. Extensive evaluations on both in-domain and out-of-domain mathematical reasoning benchmarks across various base language models, demonstrate that Full-Step-DPO achieves superior performance compared to state-of-the-art baselines.
As Simple as Fine-tuning: LLM Alignment via Bidirectional Negative Feedback Loss
Oct 07, 2024



Direct Preference Optimization (DPO) has emerged as a more computationally efficient alternative to Reinforcement Learning from Human Feedback (RLHF) with Proximal Policy Optimization (PPO), eliminating the need for reward models and online sampling. Despite these benefits, DPO and its variants remain sensitive to hyper-parameters and prone to instability, particularly on mathematical datasets. We argue that these issues arise from the unidirectional likelihood-derivative negative feedback inherent in the log-likelihood loss function. To address this, we propose a novel LLM alignment loss that establishes a stable Bidirectional Negative Feedback (BNF) during optimization. Our proposed BNF loss eliminates the need for pairwise contrastive losses and does not require any extra tunable hyper-parameters or pairwise preference data, streamlining the alignment pipeline to be as simple as supervised fine-tuning. We conduct extensive experiments across two challenging QA benchmarks and four reasoning benchmarks. The experimental results show that BNF achieves comparable performance to the best methods on QA benchmarks, while its performance decrease on the four reasoning benchmarks is significantly lower compared to the best methods, thus striking a better balance between value alignment and reasoning ability. In addition, we further validate the performance of BNF on non-pairwise datasets, and conduct in-depth analysis of log-likelihood and logit shifts across different preference optimization methods.
Negation Triplet Extraction with Syntactic Dependency and Semantic Consistency
Apr 15, 2024



Previous works of negation understanding mainly focus on negation cue detection and scope resolution, without identifying negation subject which is also significant to the downstream tasks. In this paper, we propose a new negation triplet extraction (NTE) task which aims to extract negation subject along with negation cue and scope. To achieve NTE, we devise a novel Syntax&Semantic-Enhanced Negation Extraction model, namely SSENE, which is built based on a generative pretrained language model (PLM) {of Encoder-Decoder architecture} with a multi-task learning framework. Specifically, the given sentence's syntactic dependency tree is incorporated into the PLM's encoder to discover the correlations between the negation subject, cue and scope. Moreover, the semantic consistency between the sentence and the extracted triplet is ensured by an auxiliary task learning. Furthermore, we have constructed a high-quality Chinese dataset NegComment based on the users' reviews from the real-world platform of Meituan, upon which our evaluations show that SSENE achieves the best NTE performance compared to the baselines. Our ablation and case studies also demonstrate that incorporating the syntactic information helps the PLM's recognize the distant dependency between the subject and cue, and the auxiliary task learning is helpful to extract the negation triplets with more semantic consistency.
Don't Forget Your Reward Values: Language Model Alignment via Value-based Calibration
Feb 25, 2024



While Reinforcement Learning from Human Feedback (RLHF) significantly enhances the generation quality of Large Language Models (LLMs), recent studies have raised concerns regarding the complexity and instability associated with the Proximal Policy Optimization (PPO) algorithm, proposing a series of order-based calibration methods as viable alternatives. This paper delves further into current order-based methods, examining their inefficiencies in utilizing reward values and addressing misalignment issues. Building upon these findings, we propose a novel \textbf{V}alue-based \textbf{C}ali\textbf{B}ration (VCB) method to better align LLMs with human preferences. Experimental results demonstrate that VCB surpasses existing alignment methods on AI assistant and summarization datasets, providing impressive generalizability, robustness, and stability in diverse settings.
Exploiting Duality in Open Information Extraction with Predicate Prompt
Jan 20, 2024Open information extraction (OpenIE) aims to extract the schema-free triplets in the form of (\emph{subject}, \emph{predicate}, \emph{object}) from a given sentence. Compared with general information extraction (IE), OpenIE poses more challenges for the IE models, {especially when multiple complicated triplets exist in a sentence. To extract these complicated triplets more effectively, in this paper we propose a novel generative OpenIE model, namely \emph{DualOIE}, which achieves a dual task at the same time as extracting some triplets from the sentence, i.e., converting the triplets into the sentence.} Such dual task encourages the model to correctly recognize the structure of the given sentence and thus is helpful to extract all potential triplets from the sentence. Specifically, DualOIE extracts the triplets in two steps: 1) first extracting a sequence of all potential predicates, 2) then using the predicate sequence as a prompt to induce the generation of triplets. Our experiments on two benchmarks and our dataset constructed from Meituan demonstrate that DualOIE achieves the best performance among the state-of-the-art baselines. Furthermore, the online A/B test on Meituan platform shows that 0.93\% improvement of QV-CTR and 0.56\% improvement of UV-CTR have been obtained when the triplets extracted by DualOIE were leveraged in Meituan's search system.
Team Power and Hierarchy: Understanding Team Success
Aug 09, 2021
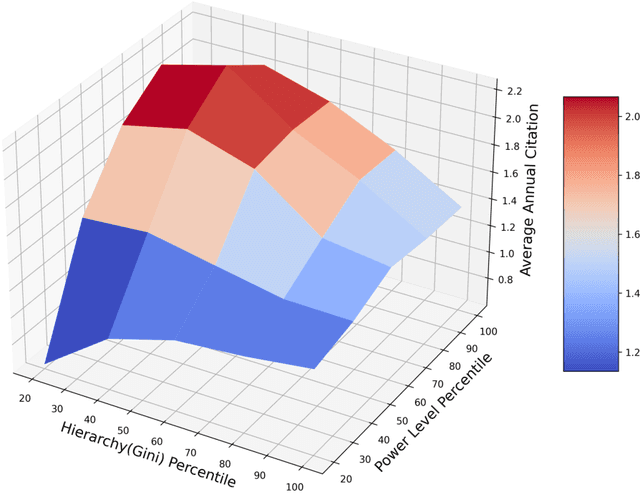

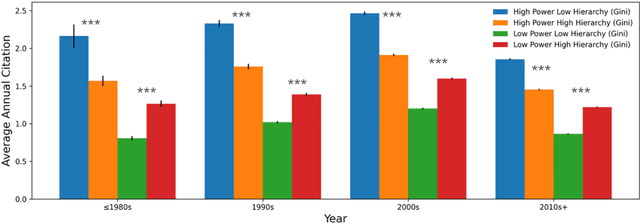
Teamwork is cooperative, participative and power sharing. In science of science, few studies have looked at the impact of team collaboration from the perspective of team power and hierarchy. This research examines in depth the relationships between team power and team success in the field of Computer Science (CS) using the DBLP dataset. Team power and hierarchy are measured using academic age and team success is quantified by citation. By analyzing 4,106,995 CS teams, we find that high power teams with flat structure have the best performance. On the contrary, low-power teams with hierarchical structure is a facilitator of team performance. These results are consistent across different time periods and team sizes.