 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward Culturally Aligned LLMs through Ontology-Guided Multi-Agent Reasoning
Jan 29, 2026Large Language Models (LLMs) increasingly support culturally sensitive decision making, yet often exhibit misalignment due to skewed pretraining data and the absence of structured value representations. Existing methods can steer outputs, but often lack demographic grounding and treat values as independent, unstructured signals, reducing consistency and interpretability. We propose OG-MAR, an Ontology-Guided Multi-Agent Reasoning framework. OG-MAR summarizes respondent-specific values from the World Values Survey (WVS) and constructs a global cultural ontology by eliciting relations over a fixed taxonomy via competency questions. At inference time, it retrieves ontology-consistent relations and demographically similar profiles to instantiate multiple value-persona agents, whose outputs are synthesized by a judgment agent that enforces ontology consistency and demographic proximity. Experiments on regional social-survey benchmarks across four LLM backbones show that OG-MAR improves cultural alignment and robustness over competitive baselines, while producing more transparent reasoning traces.
SPIO: Ensemble and Selective Strategies via LLM-Based Multi-Agent Planning in Automated Data Science
Mar 30, 2025



Large Language Models (LLMs) have revolutionized automated data analytics and machine learning by enabling dynamic reasoning and adaptability. While recent approaches have advanced multi-stage pipelines through multi-agent systems, they typically rely on rigid, single-path workflows that limit the exploration and integration of diverse strategies, often resulting in suboptimal predictions. To address these challenges, we propose SPIO (Sequential Plan Integration and Optimization), a novel framework that leverages LLM-driven decision-making to orchestrate multi-agent planning across four key modules: data preprocessing, feature engineering, modeling, and hyperparameter tuning. In each module, dedicated planning agents independently generate candidate strategies that cascade into subsequent stages, fostering comprehensive exploration. A plan optimization agent refines these strategies by suggesting several optimized plans. We further introduce two variants: SPIO-S, which selects a single best solution path as determined by the LLM, and SPIO-E, which selects the top k candidate plans and ensembles them to maximize predictive performance. Extensive experiments on Kaggle and OpenML datasets demonstrate that SPIO significantly outperforms state-of-the-art methods, providing a robust and scalable solution for automated data science task.
ValuesRAG: Enhancing Cultural Alignment Through Retrieval-Augmented Contextual Learning
Jan 02, 2025



Cultural values alignment in Large Language Models (LLMs) is a critical challenge due to their tendency to embed Western-centric biases from training data, leading to misrepresentations and fairness issues in cross-cultural contexts. Recent approaches, such as role-assignment and few-shot learning, often struggle with reliable cultural alignment as they heavily rely on pre-trained knowledge, lack scalability, and fail to capture nuanced cultural values effectively. To address these issues, we propose ValuesRAG, a novel and effective framework that applies Retrieval-Augmented Generation (RAG) with in-context learning to integrate cultural and demographic knowledge dynamically during text generation. Leveraging the World Values Survey (WVS) dataset, ValuesRAG first generates summaries of values for each individual. Subsequently, we curated several representative regional datasets to serve as test datasets and retrieve relevant summaries of values based on demographic features, followed by a reranking step to select the top-k relevant summaries. ValuesRAG consistently outperforms baseline methods, both in the main experiment and in the ablation study where only the values summary was provided, highlighting ValuesRAG's potential to foster culturally aligned AI systems and enhance the inclusivity of AI-driven applications.
Who Gets Recommended? Investigating Gender, Race, and Country Disparities in Paper Recommendations from Large Language Models
Dec 31, 2024



This paper investigates the performance of several representative large models in the tasks of literature recommendation and explores potential biases in research exposure. The results indicate that not only LLMs' overall recommendation accuracy remains limited but also the models tend to recommend literature with greater citation counts, later publication date, and larger author teams. Yet, in scholar recommendation tasks, there is no evidence that LLMs disproportionately recommend male, white, or developed-country authors, contrasting with patterns of known human biases.
Has China caught up to the US in AI research? An exploration of mimetic isomorphism as a model for late industrializers
Jul 11, 2023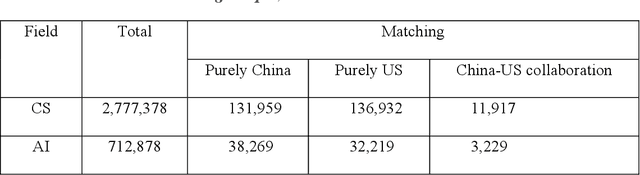

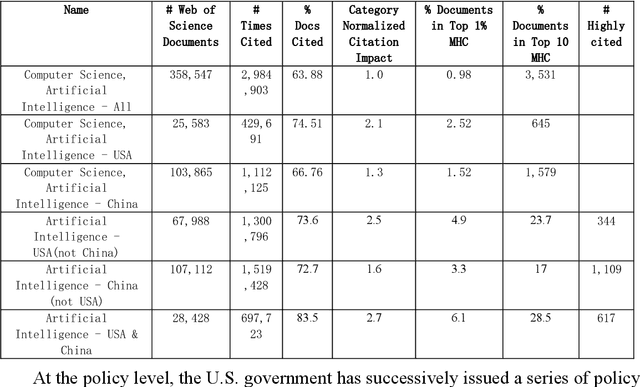

Artificial Intelligence (AI), a cornerstone of 21st-century technology, has seen remarkable growth in China. In this paper, we examine China's AI development process, demonstrating that it is characterized by rapid learning and differentiation, surpassing the export-oriented growth propelled by Foreign Direct Investment seen in earlier Asian industrializers. Our data indicates that China currently leads the USA in the volume of AI-related research papers. However, when we delve into the quality of these papers based on specific metrics, the USA retains a slight edge. Nevertheless, the pace and scale of China's AI development remain noteworthy. We attribute China's accelerated AI progress to several factors, including global trends favoring open access to algorithms and research papers, contributions from China's broad diaspora and returnees, and relatively lax data protection policies. In the vein of our research, we have developed a novel measure for gauging China's imitation of US research. Our analysis shows that by 2018, the time lag between China and the USA in addressing AI research topics had evaporated. This finding suggests that China has effectively bridged a significant knowledge gap and could potentially be setting out on an independent research trajectory. While this study compares China and the USA exclusively, it's important to note that research collaborations between these two nations have resulted in more highly cited work than those produced by either country independently. This underscores the power of international cooperation in driving scientific progress in AI.
Exploring the Distribution Regularities of User Attention and Sentiment toward Product Aspects in Online Reviews
Sep 08, 2022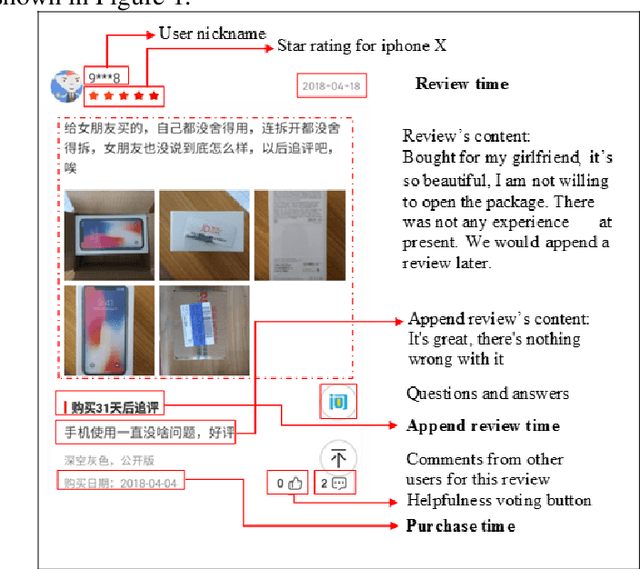

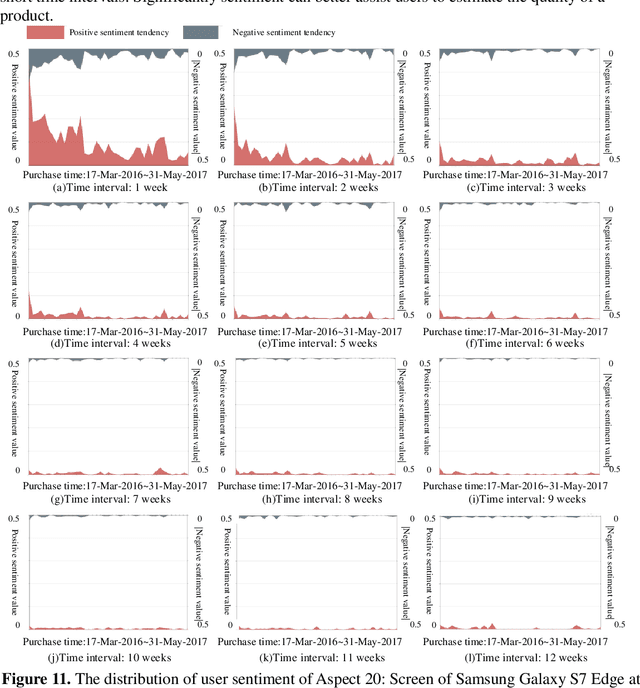
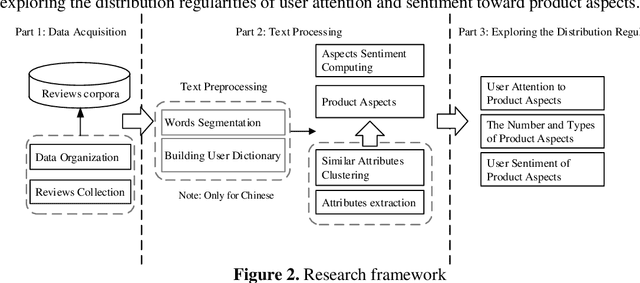
[Purpose] To better understand the online reviews and help potential consumers, businessmen, and product manufacturers effectively obtain users' evaluation on product aspects, this paper explores the distribution regularities of user attention and sentiment toward product aspects from the temporal perspective of online reviews. [Design/methodology/approach] Temporal characteristics of online reviews (purchase time, review time, and time intervals between purchase time and review time), similar attributes clustering, and attribute-level sentiment computing technologies are employed based on more than 340k smartphone reviews of three products from JD.COM (a famous online shopping platform in China) to explore the distribution regularities of user attention and sentiment toward product aspects in this article. [Findings] The empirical results show that a power-law distribution can fit user attention to product aspects, and the reviews posted in short time intervals contain more product aspects. Besides, the results show that the values of user sentiment of product aspects are significantly higher/lower in short time intervals which contribute to judging the advantages and weaknesses of a product. [Research limitations] The paper can't acquire online reviews for more products with temporal characteristics to verify the findings because of the restriction on reviews crawling by the shopping platforms. [Originality/value] This work reveals the distribution regularities of user attention and sentiment toward product aspects, which is of great significance in assisting decision-making, optimizing review presentation, and improving the shopping experience.
The Gene of Scientific Success
Feb 17, 2022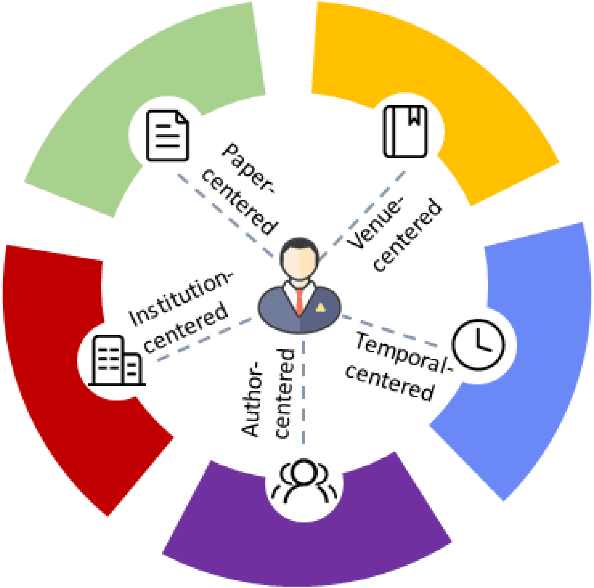


This paper elaborates how to identify and evaluate causal factors to improve scientific impact. Currently, analyzing scientific impact can be beneficial to various academic activities including funding application, mentor recommendation, and discovering potential cooperators etc. It is universally acknowledged that high-impact scholars often have more opportunities to receive awards as an encouragement for their hard working. Therefore, scholars spend great efforts in making scientific achievements and improving scientific impact during their academic life. However, what are the determinate factors that control scholars' academic success? The answer to this question can help scholars conduct their research more efficiently. Under this consideration, our paper presents and analyzes the causal factors that are crucial for scholars' academic success. We first propose five major factors including article-centered factors, author-centered factors, venue-centered factors, institution-centered factors, and temporal factors. Then, we apply recent advanced machine learning algorithms and jackknife method to assess the importance of each causal factor. Our empirical results show that author-centered and article-centered factors have the highest relevancy to scholars' future success in the computer science area. Additionally, we discover an interesting phenomenon that the h-index of scholars within the same institution or university are actually very close to each other.
Team Power and Hierarchy: Understanding Team Success
Aug 09, 2021
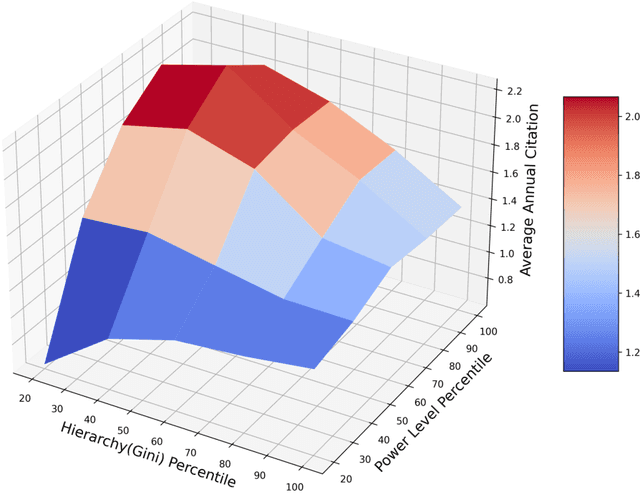

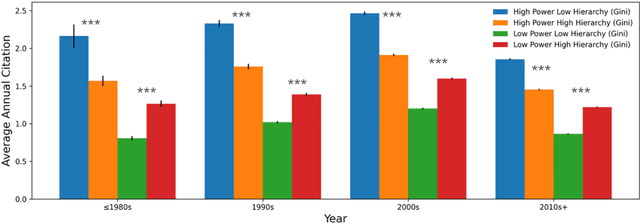
Teamwork is cooperative, participative and power sharing. In science of science, few studies have looked at the impact of team collaboration from the perspective of team power and hierarchy. This research examines in depth the relationships between team power and team success in the field of Computer Science (CS) using the DBLP dataset. Team power and hierarchy are measured using academic age and team success is quantified by citation. By analyzing 4,106,995 CS teams, we find that high power teams with flat structure have the best performance. On the contrary, low-power teams with hierarchical structure is a facilitator of team performance. These results are consistent across different time periods and team sizes.
Analyzing Linguistic Complexity and Scientific Impact
Jul 27, 2019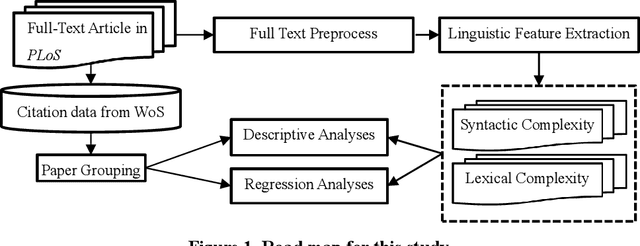
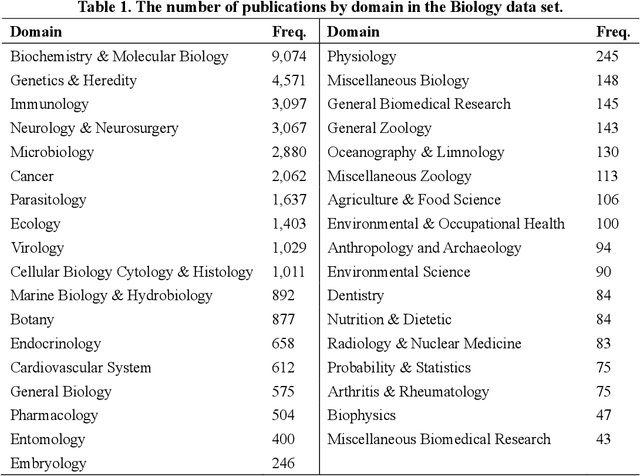


The number of publications and the number of citations received have become the most common indicators of scholarly success. In this context, scientific writing increasingly plays an important role in scholars' scientific careers. To understand the relationship between scientific writing and scientific impact, this paper selected 12 variables of linguistic complexity as a proxy for depicting scientific writing. We then analyzed these features from 36,400 full-text Biology articles and 1,797 full-text Psychology articles. These features were compared to the scientific impact of articles, grouped into high, medium, and low categories. The results suggested no practical significant relationship between linguistic complexity and citation strata in either discipline. This suggests that textual complexity plays little role in scientific impact in our data sets.
Examining Scientific Writing Styles from the Perspective of Linguistic Complexity
Sep 13, 2018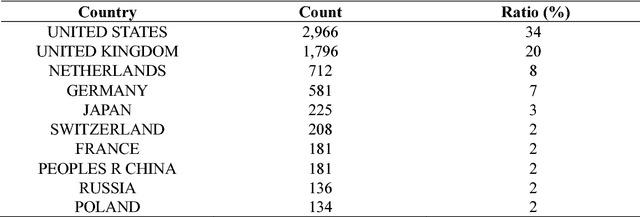
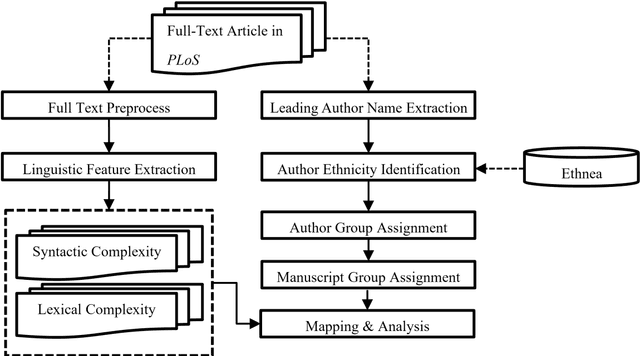
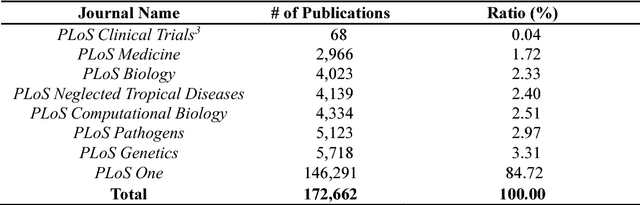

Publishing articles in high-impact English journals is difficult for scholars around the world, especially for non-native English-speaking scholars (NNESs), most of whom struggle with proficiency in English. In order to uncover the differences in English scientific writing between native English-speaking scholars (NESs) and NNESs, we collected a large-scale data set containing more than 150,000 full-text articles published in PLoS between 2006 and 2015. We divided these articles into three groups according to the ethnic backgrounds of the first and corresponding authors, obtained by Ethnea, and examined the scientific writing styles in English from a two-fold perspective of linguistic complexity: (1) syntactic complexity, including measurements of sentence length and sentence complexity; and (2) lexical complexity, including measurements of lexical diversity, lexical density, and lexical sophistication. The observations suggest marginal differences between groups in syntactical and lexical complexity.