 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLIRudit: Cross-Lingual Information Retrieval of Scientific Documents
Apr 22, 2025Cross-lingual information retrieval (CLIR) consists in finding relevant documents in a language that differs from the language of the queries. This paper presents CLIRudit, a new dataset created to evaluate cross-lingual academic search, focusing on English queries and French documents. The dataset is built using bilingual article metadata from \'Erudit, a Canadian publishing platform, and is designed to represent scenarios in which researchers search for scholarly content in languages other than English. We perform a comprehensive benchmarking of different zero-shot first-stage retrieval methods on the dataset, including dense and sparse retrievers, query and document machine translation, and state-of-the-art multilingual retrievers. Our results show that large dense retrievers, not necessarily trained for the cross-lingual retrieval task, can achieve zero-shot performance comparable to using ground truth human translations, without the need for machine translation. Sparse retrievers, such as BM25 or SPLADE, combined with document translation, show competitive results, providing an efficient alternative to large dense models. This research advances the understanding of cross-lingual academic information retrieval and provides a framework that others can use to build comparable datasets across different languages and disciplines. By making the dataset and code publicly available, we aim to facilitate further research that will help make scientific knowledge more accessible across language barriers.
Sorting the Babble in Babel: Assessing the Performance of Language Detection Algorithms on the OpenAlex Database
Feb 05, 2025Following a recent study on the quality of OpenAlex linguistic metadata (C\'espedes et al., 2025), the present paper aims to optimize the latter through the design, use, and evaluation of various linguistic classification procedures based on the latest and most efficient automatic language detection algorithms. Starting from a multilingual set of manually-annotated samples of articles indexed in the database, different classification procedures are then designed, based on the application of a set of language detection algorithms on a series of corpora generated from different combinations of textual metadata of indexed articles. At sample level first, the performance of these different procedures for each of the main languages in the database is evaluated in terms of precision, recall, and processing time. Then, overall procedure performance is estimated at the database level by means of a probabilistic simulation of harmonically aggregated and weighted scores. Results show that procedure performance strongly depends on the importance given to each of the measures implemented: for contexts where precision is preferred, using the LangID algorithm on article titles, abstracts as well as journal names gives the best results; however, for all cases where recall is considered at least slightly more important than precision or as soon as processing times are given any kind of consideration, use of the FastSpell algorithm on article titles only outperforms all other alternatives. Given the lack of truly multilingual, large-scale bibliographic databases, it is hoped that these results help confirm and foster the unparalleled potential of the OpenAlex database for cross-linguistic, bibliometric-based research and analysis.
Delineating Feminist Studies through bibliometric analysis
Nov 27, 2024The multidisciplinary and socially anchored nature of Feminist Studies presents unique challenges for bibliometric analysis, as this research area transcends traditional disciplinary boundaries and reflects discussions from feminist and LGBTQIA+ social movements. This paper proposes a novel approach for identifying gender/sex related publications scattered across diverse scientific disciplines. Using the Dimensions database, we employ bibliometric techniques, natural language processing (NLP) and manual curation to compile a dataset of scientific publications that allows for the analysis of Gender Studies and its influence across different disciplines. This is achieved through a methodology that combines a core of specialized journals with a comprehensive keyword search over titles. These keywords are obtained by applying Topic Modeling (BERTopic) to the corpus of titles and abstracts from the core. This methodological strategy, divided into two stages, reflects the dynamic interaction between Gender Studies and its dialogue with different disciplines. This hybrid system surpasses basic keyword search by mitigating potential biases introduced through manual keyword enumeration. The resulting dataset comprises over 1.9 million scientific documents published between 1668 and 2023, spanning four languages. This dataset enables a characterization of Gender Studies in terms of addressed topics, citation and collaboration dynamics, and institutional and regional participation. By addressing the methodological challenges of studying "more-than-disciplinary" research areas, this approach could also be adapted to delineate other conversations where disciplinary boundaries are difficult to disentangle.
Measuring Disagreement in Science
Jul 30, 2021
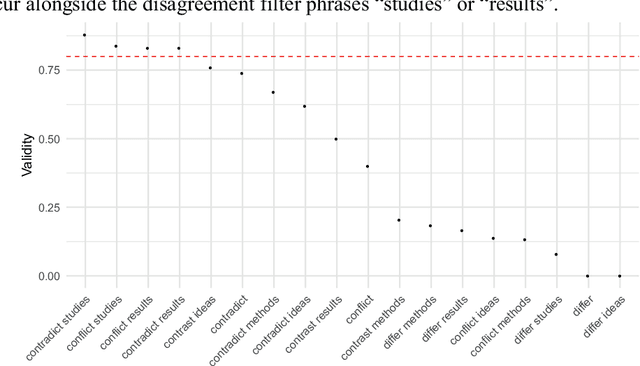
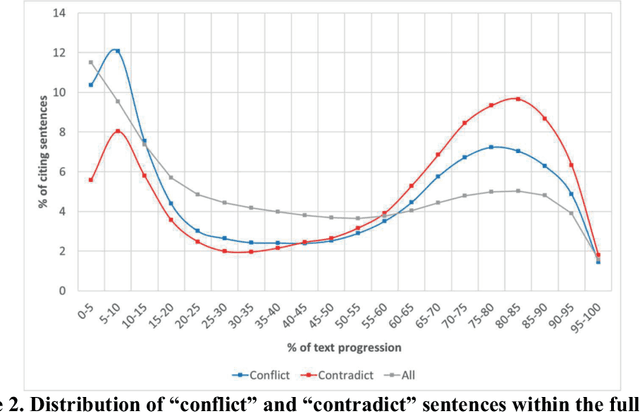
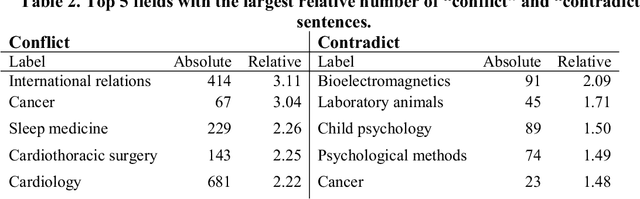
Disagreement is essential to scientific progress. However, the extent of disagreement in science, its evolution over time, and the fields in which it happens, remains largely unknown. Leveraging a massive collection of scientific texts, we develop a cue-phrase based approach to identify instances of disagreement citations across more than four million scientific articles. Using this method, we construct an indicator of disagreement across scientific fields over the 2000-2015 period. In contrast with black-box text classification methods, our framework is transparent and easily interpretable. We reveal a disciplinary spectrum of disagreement, with higher disagreement in the social sciences and lower disagreement in physics and mathematics. However, detailed disciplinary analysis demonstrates heterogeneity across sub-fields, revealing the importance of local disciplinary cultures and epistemic characteristics of disagreement. Paper-level analysis reveals notable episodes of disagreement in science, and illustrates how methodological artefacts can confound analyses of scientific texts. These findings contribute to a broader understanding of disagreement and establish a foundation for future research to understanding key processes underlying scientific progress.
Avoiding bias when inferring race using name-based approaches
May 03, 2021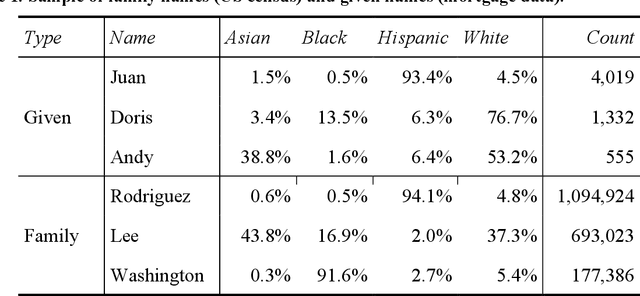
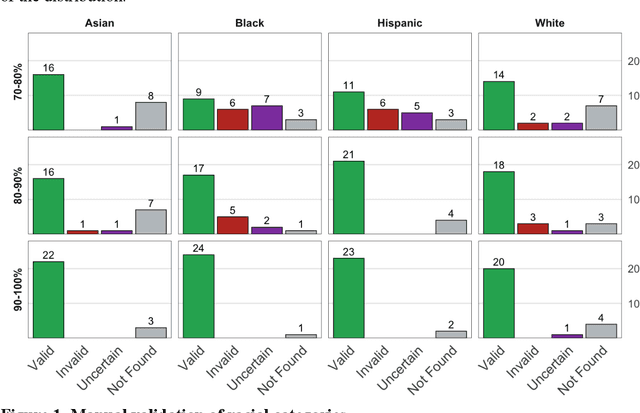
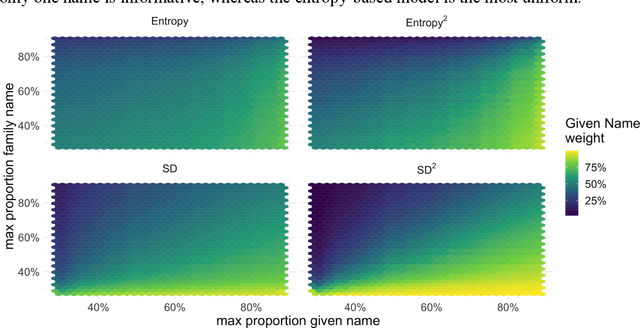
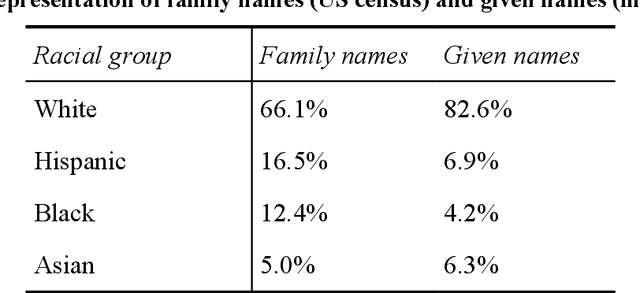
Racial disparity in academia is a widely acknowledged problem. The quantitative understanding of racial-based systemic inequalities is an important step towards a more equitable research system. However, few large-scale analyses have been performed on this topic, mostly because of the lack of robust race-disambiguation algorithms. Identifying author information does not generally include the author's race. Therefore, an algorithm needs to be employed, using known information about authors, i.e., their names, to infer their perceived race. Nevertheless, as any other algorithm, the process of racial inference can generate biases if it is not carefully considered. When the research is focused on the understanding of racial-based inequalities, such biases undermine the objectives of the investigation and may perpetuate inequities. The goal of this article is to assess the biases introduced by the different approaches used name-based racial inference. We use information from US census and mortgage applications to infer the race of US author names in the Web of Science. We estimate the effects of using given and family names, thresholds or continuous distributions, and imputation. Our results demonstrate that the validity of name-based inference varies by race and ethnicity and that threshold approaches underestimate Black authors and overestimate White authors. We conclude with recommendations to avoid potential biases. This article fills an important research gap that will allow more systematic and unbiased studies on racial disparity in science.
Improving Reproducibility in Machine Learning Research (A Report from the NeurIPS 2019 Reproducibility Program)
Apr 02, 2020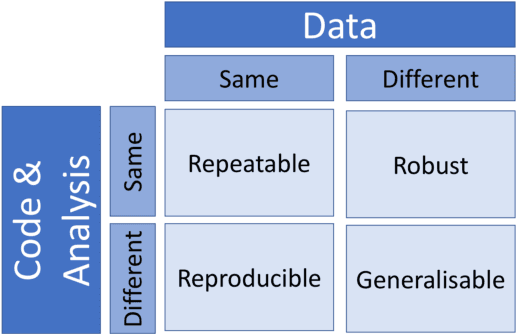
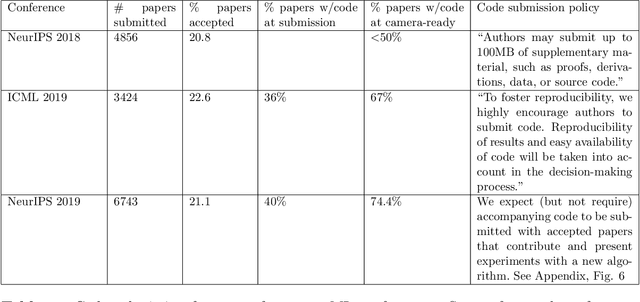
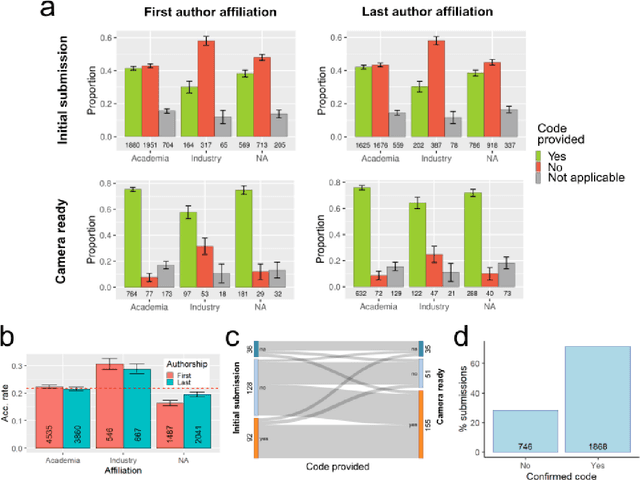
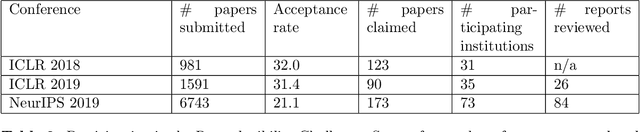
One of the challenges in machine learning research is to ensure that presented and published results are sound and reliable. Reproducibility, that is obtaining similar results as presented in a paper or talk, using the same code and data (when available), is a necessary step to verify the reliability of research findings. Reproducibility is also an important step to promote open and accessible research, thereby allowing the scientific community to quickly integrate new findings and convert ideas to practice. Reproducibility also promotes the use of robust experimental workflows, which potentially reduce unintentional errors. In 2019, the Neural Information Processing Systems (NeurIPS) conference, the premier international conference for research in machine learning, introduced a reproducibility program, designed to improve the standards across the community for how we conduct, communicate, and evaluate machine learning research. The program contained three components: a code submission policy, a community-wide reproducibility challenge, and the inclusion of the Machine Learning Reproducibility checklist as part of the paper submission process. In this paper, we describe each of these components, how it was deployed, as well as what we were able to learn from this initiative.
Content and linguistic biases in the peer review process of artificial intelligence conferences
Oct 21, 2019
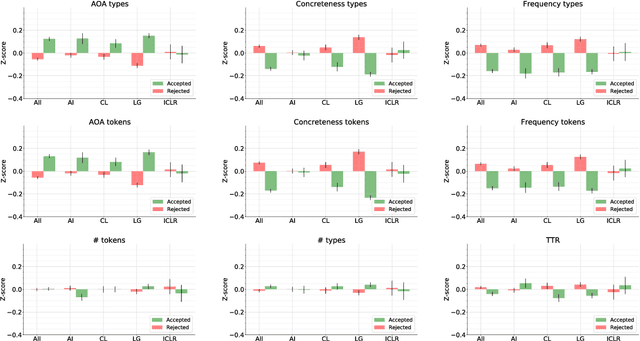
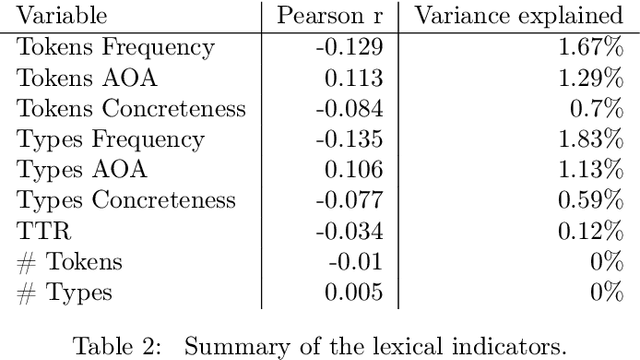
We analysed a recently released dataset of scientific manuscripts that were either rejected or accepted from various conferences in artificial intelligence. We used a combination of semantic, lexical and psycholinguistic analyses of the full text of the manuscripts to compare them based on the outcome of the peer review process. We found that accepted manuscripts were written with words that are less frequent, that are acquired at an older age, and that are more abstract than rejected manuscripts. We also found that accepted manuscripts scored lower on two indicators of readability than rejected manuscripts, and that they also used more artificial intelligence jargon. An analysis of the references included in the manuscripts revealed that the subset of accepted submissions were more likely to cite the same publications. This finding was echoed by pairwise comparisons of the word content of the manuscripts (i.e. an indicator or semantic similarity), which was higher in the accepted manuscripts. Finally, we predicted the peer review outcome of manuscripts with their word content, with words related to machine learning and neural networks positively related with acceptance, whereas words related to logic, symbolic processing and knowledge-based systems negatively related with acceptance.
Analyzing Linguistic Complexity and Scientific Impact
Jul 27, 2019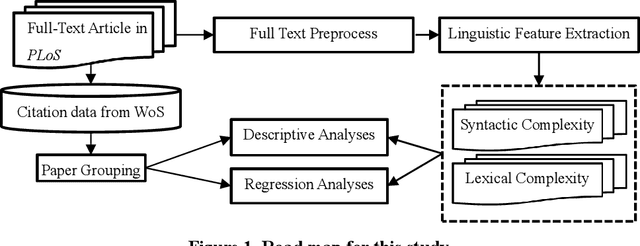


The number of publications and the number of citations received have become the most common indicators of scholarly success. In this context, scientific writing increasingly plays an important role in scholars' scientific careers. To understand the relationship between scientific writing and scientific impact, this paper selected 12 variables of linguistic complexity as a proxy for depicting scientific writing. We then analyzed these features from 36,400 full-text Biology articles and 1,797 full-text Psychology articles. These features were compared to the scientific impact of articles, grouped into high, medium, and low categories. The results suggested no practical significant relationship between linguistic complexity and citation strata in either discipline. This suggests that textual complexity plays little role in scientific impact in our data sets.