 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Psychosocial Impacts of Generative AI Harms
May 02, 2024
The rapid emergence of generative Language Models (LMs) has led to growing concern about the impacts that their unexamined adoption may have on the social well-being of diverse user groups. Meanwhile, LMs are increasingly being adopted in K-20 schools and one-on-one student settings with minimal investigation of potential harms associated with their deployment. Motivated in part by real-world/everyday use cases (e.g., an AI writing assistant) this paper explores the potential psychosocial harms of stories generated by five leading LMs in response to open-ended prompting. We extend findings of stereotyping harms analyzing a total of 150K 100-word stories related to student classroom interactions. Examining patterns in LM-generated character demographics and representational harms (i.e., erasure, subordination, and stereotyping) we highlight particularly egregious vignettes, illustrating the ways LM-generated outputs may influence the experiences of users with marginalized and minoritized identities, and emphasizing the need for a critical understanding of the psychosocial impacts of generative AI tools when deployed and utilized in diverse social contexts.
Laissez-Faire Harms: Algorithmic Biases in Generative Language Models
Apr 11, 2024



The rapid deployment of generative language models (LMs) has raised concerns about social biases affecting the well-being of diverse consumers. The extant literature on generative LMs has primarily examined bias via explicit identity prompting. However, prior research on bias in earlier language-based technology platforms, including search engines, has shown that discrimination can occur even when identity terms are not specified explicitly. Studies of bias in LM responses to open-ended prompts (where identity classifications are left unspecified) are lacking and have not yet been grounded in end-consumer harms. Here, we advance studies of generative LM bias by considering a broader set of natural use cases via open-ended prompting. In this "laissez-faire" setting, we find that synthetically generated texts from five of the most pervasive LMs (ChatGPT3.5, ChatGPT4, Claude2.0, Llama2, and PaLM2) perpetuate harms of omission, subordination, and stereotyping for minoritized individuals with intersectional race, gender, and/or sexual orientation identities (AI/AN, Asian, Black, Latine, MENA, NH/PI, Female, Non-binary, Queer). We find widespread evidence of bias to an extent that such individuals are hundreds to thousands of times more likely to encounter LM-generated outputs that portray their identities in a subordinated manner compared to representative or empowering portrayals. We also document a prevalence of stereotypes (e.g. perpetual foreigner) in LM-generated outputs that are known to trigger psychological harms that disproportionately affect minoritized individuals. These include stereotype threat, which leads to impaired cognitive performance and increased negative self-perception. Our findings highlight the urgent need to protect consumers from discriminatory harms caused by language models and invest in critical AI education programs tailored towards empowering diverse consumers.
Avoiding bias when inferring race using name-based approaches
May 03, 2021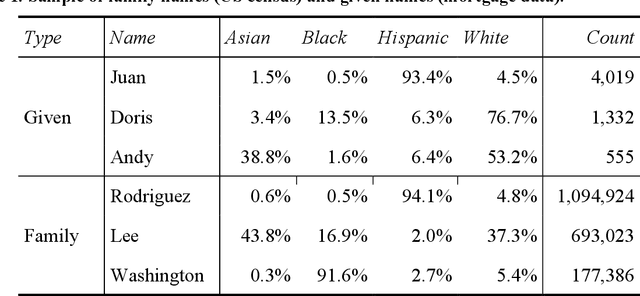
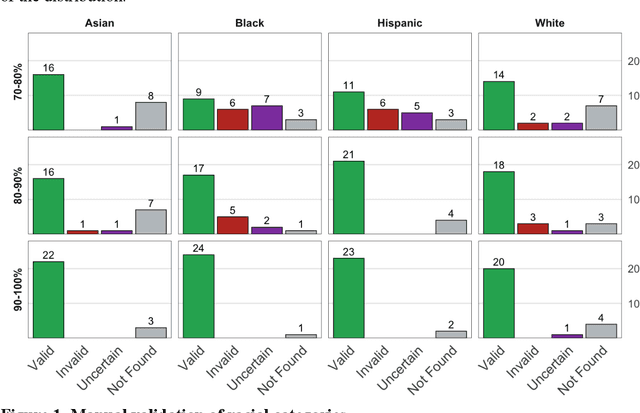
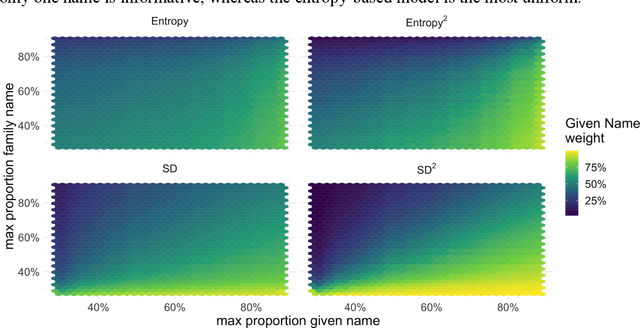
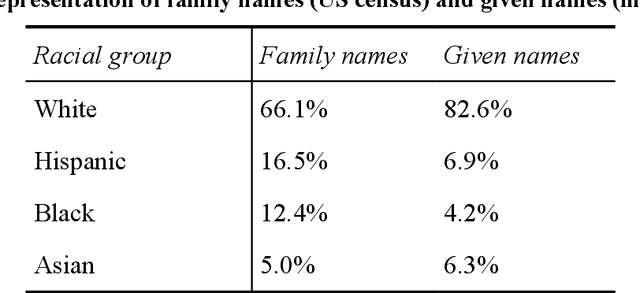
Racial disparity in academia is a widely acknowledged problem. The quantitative understanding of racial-based systemic inequalities is an important step towards a more equitable research system. However, few large-scale analyses have been performed on this topic, mostly because of the lack of robust race-disambiguation algorithms. Identifying author information does not generally include the author's race. Therefore, an algorithm needs to be employed, using known information about authors, i.e., their names, to infer their perceived race. Nevertheless, as any other algorithm, the process of racial inference can generate biases if it is not carefully considered. When the research is focused on the understanding of racial-based inequalities, such biases undermine the objectives of the investigation and may perpetuate inequities. The goal of this article is to assess the biases introduced by the different approaches used name-based racial inference. We use information from US census and mortgage applications to infer the race of US author names in the Web of Science. We estimate the effects of using given and family names, thresholds or continuous distributions, and imputation. Our results demonstrate that the validity of name-based inference varies by race and ethnicity and that threshold approaches underestimate Black authors and overestimate White authors. We conclude with recommendations to avoid potential biases. This article fills an important research gap that will allow more systematic and unbiased studies on racial disparity in science.