 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Psychosocial Impacts of Generative AI Harms
May 02, 2024
The rapid emergence of generative Language Models (LMs) has led to growing concern about the impacts that their unexamined adoption may have on the social well-being of diverse user groups. Meanwhile, LMs are increasingly being adopted in K-20 schools and one-on-one student settings with minimal investigation of potential harms associated with their deployment. Motivated in part by real-world/everyday use cases (e.g., an AI writing assistant) this paper explores the potential psychosocial harms of stories generated by five leading LMs in response to open-ended prompting. We extend findings of stereotyping harms analyzing a total of 150K 100-word stories related to student classroom interactions. Examining patterns in LM-generated character demographics and representational harms (i.e., erasure, subordination, and stereotyping) we highlight particularly egregious vignettes, illustrating the ways LM-generated outputs may influence the experiences of users with marginalized and minoritized identities, and emphasizing the need for a critical understanding of the psychosocial impacts of generative AI tools when deployed and utilized in diverse social contexts.
Measuring Disagreement in Science
Jul 30, 2021
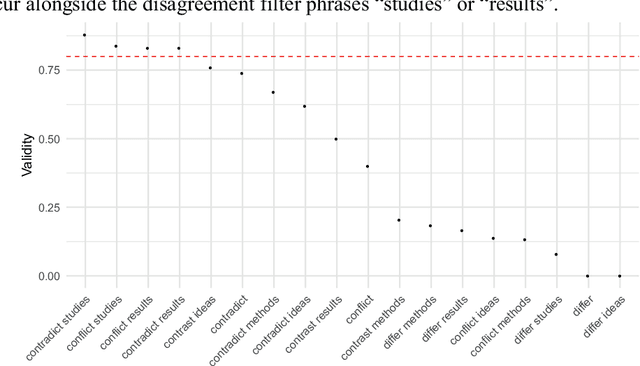
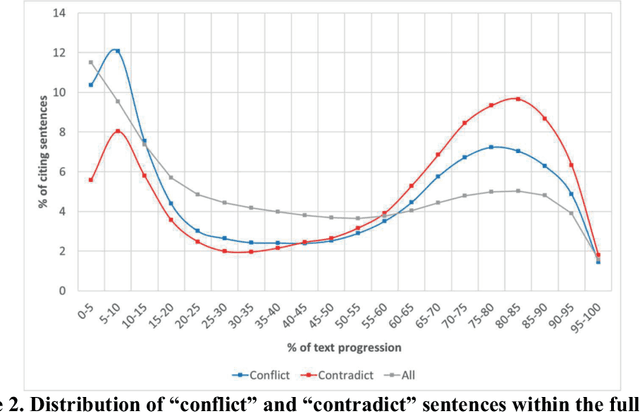
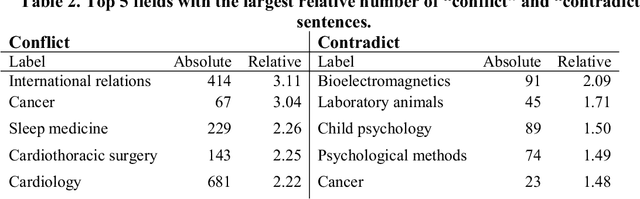
Disagreement is essential to scientific progress. However, the extent of disagreement in science, its evolution over time, and the fields in which it happens, remains largely unknown. Leveraging a massive collection of scientific texts, we develop a cue-phrase based approach to identify instances of disagreement citations across more than four million scientific articles. Using this method, we construct an indicator of disagreement across scientific fields over the 2000-2015 period. In contrast with black-box text classification methods, our framework is transparent and easily interpretable. We reveal a disciplinary spectrum of disagreement, with higher disagreement in the social sciences and lower disagreement in physics and mathematics. However, detailed disciplinary analysis demonstrates heterogeneity across sub-fields, revealing the importance of local disciplinary cultures and epistemic characteristics of disagreement. Paper-level analysis reveals notable episodes of disagreement in science, and illustrates how methodological artefacts can confound analyses of scientific texts. These findings contribute to a broader understanding of disagreement and establish a foundation for future research to understanding key processes underlying scientific progress.
Avoiding bias when inferring race using name-based approaches
May 03, 2021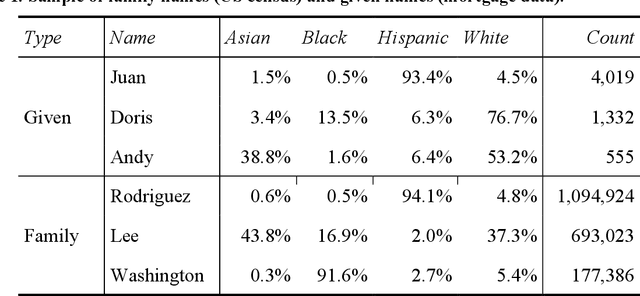
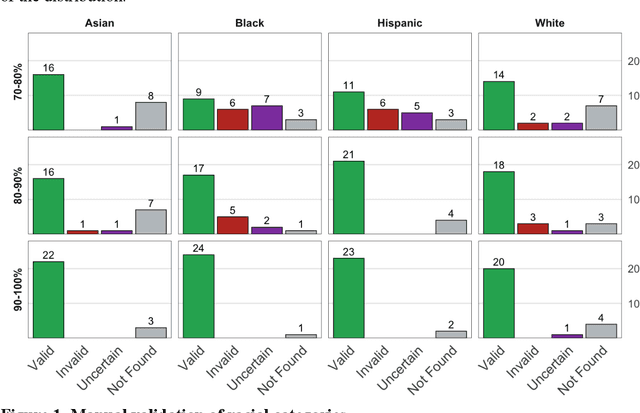
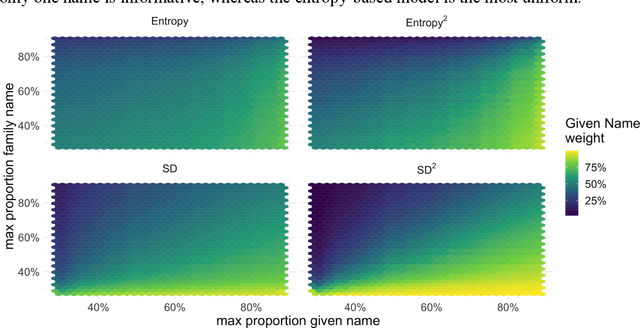
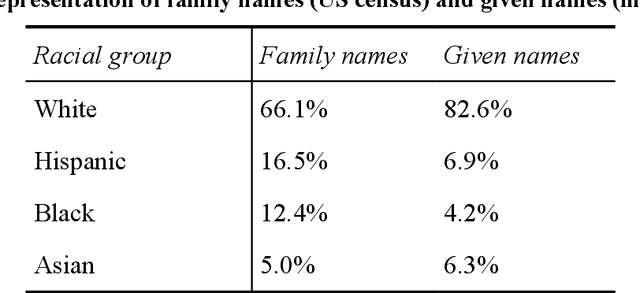
Racial disparity in academia is a widely acknowledged problem. The quantitative understanding of racial-based systemic inequalities is an important step towards a more equitable research system. However, few large-scale analyses have been performed on this topic, mostly because of the lack of robust race-disambiguation algorithms. Identifying author information does not generally include the author's race. Therefore, an algorithm needs to be employed, using known information about authors, i.e., their names, to infer their perceived race. Nevertheless, as any other algorithm, the process of racial inference can generate biases if it is not carefully considered. When the research is focused on the understanding of racial-based inequalities, such biases undermine the objectives of the investigation and may perpetuate inequities. The goal of this article is to assess the biases introduced by the different approaches used name-based racial inference. We use information from US census and mortgage applications to infer the race of US author names in the Web of Science. We estimate the effects of using given and family names, thresholds or continuous distributions, and imputation. Our results demonstrate that the validity of name-based inference varies by race and ethnicity and that threshold approaches underestimate Black authors and overestimate White authors. We conclude with recommendations to avoid potential biases. This article fills an important research gap that will allow more systematic and unbiased studies on racial disparity in science.
Analyzing Linguistic Complexity and Scientific Impact
Jul 27, 2019
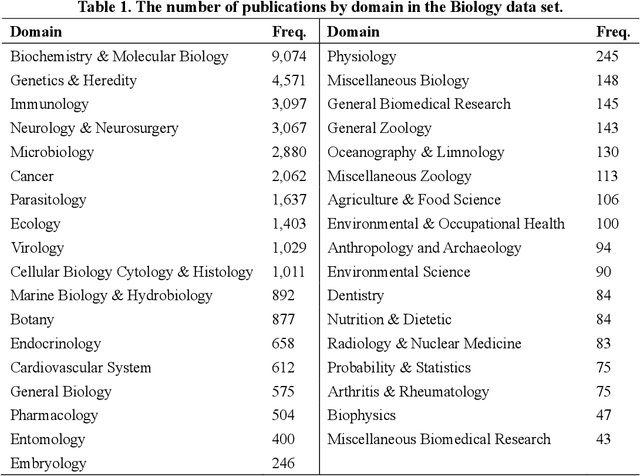


The number of publications and the number of citations received have become the most common indicators of scholarly success. In this context, scientific writing increasingly plays an important role in scholars' scientific careers. To understand the relationship between scientific writing and scientific impact, this paper selected 12 variables of linguistic complexity as a proxy for depicting scientific writing. We then analyzed these features from 36,400 full-text Biology articles and 1,797 full-text Psychology articles. These features were compared to the scientific impact of articles, grouped into high, medium, and low categories. The results suggested no practical significant relationship between linguistic complexity and citation strata in either discipline. This suggests that textual complexity plays little role in scientific impact in our data sets.