 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePatchScene: Patch-based Voxel Diffusion for Large-Scale Scene Completion
Jun 02, 2026We propose PatchScene, a novel diffusion-based framework for large-scale LiDAR scene completion. Unlike existing methods that rely on global latent representations or dense voxel grids, PatchScene adopts a patch-based voxel diffusion paradigm that explicitly generates fine-grained geometry within localized 3D regions. To ensure coherent reconstruction at both spatial and temporal scales, we introduce a confidence-guided spatio-temporal fusion mechanism that integrates overlapping patches and adjacent frames in a unified generative process. Furthermore, we design an Annular-Flow diffusion strategy that leverages the radial density pattern of LiDAR scans to progressively propagate high-fidelity information from near-range to far-range regions, enabling spatially unbounded scene completion. Extensive experiments on the SemanticKITTI benchmark demonstrate that PatchScene achieves state-of-the-art performance across all standard metrics, surpassing previous approaches in both geometric accuracy and temporal consistency. Remarkably, the model trained on 20 m LiDAR ranges generalizes effectively to 50 m scenes without retraining, highlighting its strong scalability and generalization capability for real-world autonomous driving applications.
M100: An Orchestrated Dataflow Architecture Powering General AI Computing
Apr 20, 2026As deep learning-based AI technologies gain momentum, the demand for general-purpose AI computing architectures continues to grow. While GPGPU-based architectures offer versatility for diverse AI workloads, they often fall short in efficiency and cost-effectiveness. Various Domain-Specific Architectures (DSAs) excel at particular AI tasks but struggle to extend across broader applications or adapt to the rapidly evolving AI landscape. M100 is Li Auto's response: a performant, cost-effective architecture for AI inference in Autonomous Driving (AD), Large Language Models (LLMs), and intelligent human interactions, domains crucial to today's most competitive automobile platforms. M100 employs a dataflow parallel architecture, where compiler-architecture co-design orchestrates not only computation but, more critically, data movement across time and space. Leveraging dataflow computing efficiency, our hardware-software co-design improves system performance while reducing hardware complexity and cost. M100 largely eliminates caching: tensor computations are driven by compiler- and runtime-managed data streams flowing between computing elements and on/off-chip memories, yielding greater efficiency and scalability than cache-based systems. Another key principle was selecting the right operational granularity for scheduling, issuing, and execution across compiler, firmware, and hardware. Recognizing commonalities in AI workloads, we chose the tensor as the fundamental data element. M100 demonstrates general AI computing capability across diverse inference applications, including UniAD (for AD) and LLaMA (for LLMs). Benchmarks show M100 outperforms GPGPU architectures in AD applications with higher utilization, representing a promising direction for future general AI computing.
The Effect of Gender Diversity on Scientific Team Impact: A Team Roles Perspective
Dec 29, 2025The influence of gender diversity on the success of scientific teams is of great interest to academia. However, prior findings remain inconsistent, and most studies operationalize diversity in aggregate terms, overlooking internal role differentiation. This limitation obscures a more nuanced understanding of how gender diversity shapes team impact. In particular, the effect of gender diversity across different team roles remains poorly understood. To this end, we define a scientific team as all coauthors of a paper and measure team impact through five-year citation counts. Using author contribution statements, we classified members into leadership and support roles. Drawing on more than 130,000 papers from PLOS journals, most of which are in biomedical-related disciplines, we employed multivariable regression to examine the association between gender diversity in these roles and team impact. Furthermore, we apply a threshold regression model to investigate how team size moderates this relationship. The results show that (1) the relationship between gender diversity and team impact follows an inverted U-shape for both leadership and support groups; (2) teams with an all-female leadership group and an all-male support group achieve higher impact than other team types. Interestingly, (3) the effect of leadership-group gender diversity is significantly negative for small teams but becomes positive and statistically insignificant in large teams. In contrast, the estimates for support-group gender diversity remain significant and positive, regardless of team size.
Escaping Stability-Plasticity Dilemma in Online Continual Learning for Motion Forecasting via Synergetic Memory Rehearsal
Aug 27, 2025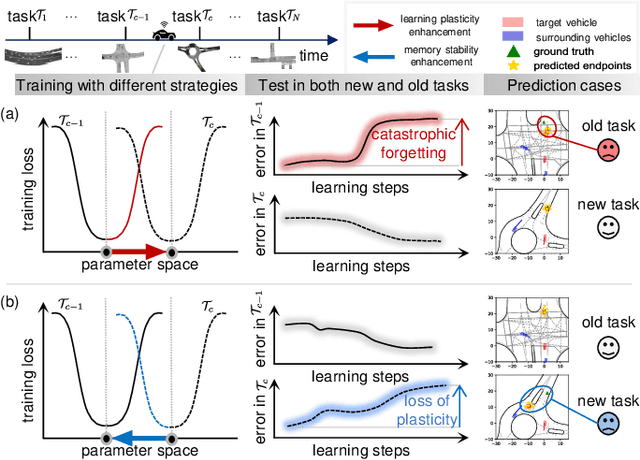
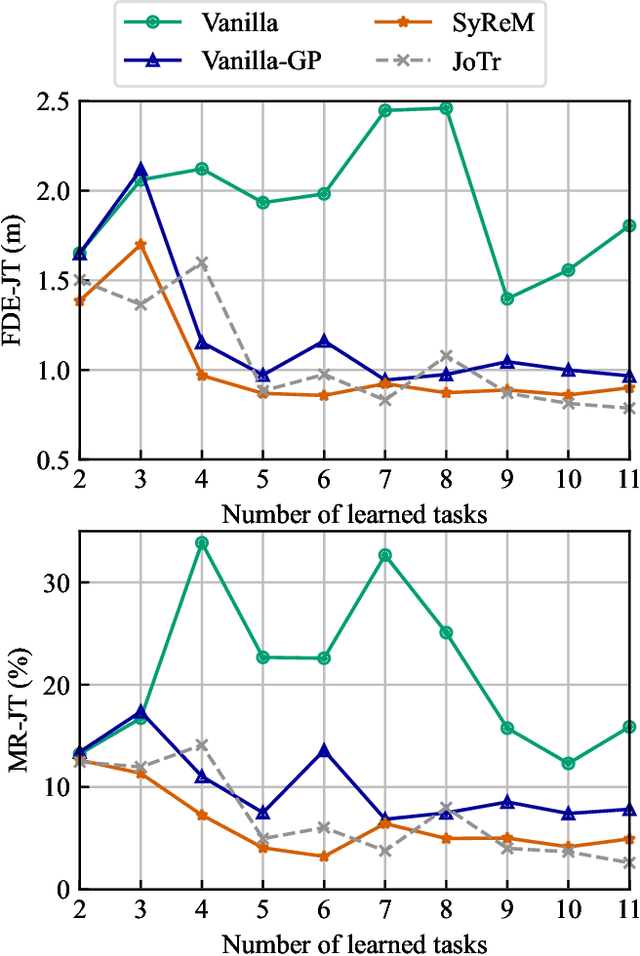
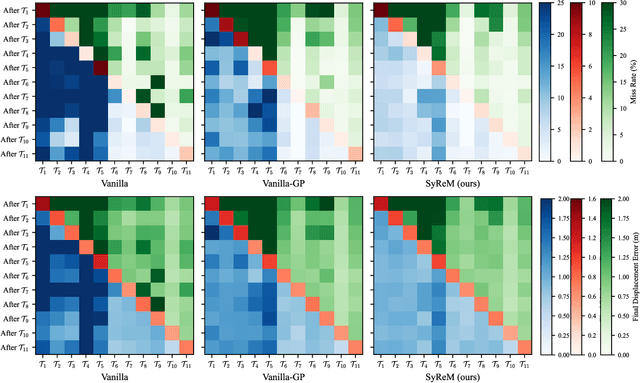
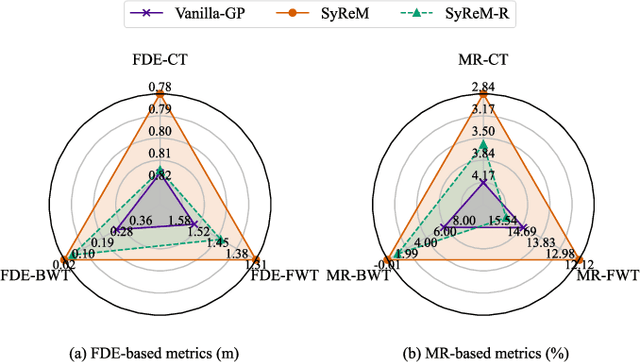
Deep neural networks (DNN) have achieved remarkable success in motion forecasting. However, most DNN-based methods suffer from catastrophic forgetting and fail to maintain their performance in previously learned scenarios after adapting to new data. Recent continual learning (CL) studies aim to mitigate this phenomenon by enhancing memory stability of DNN, i.e., the ability to retain learned knowledge. Yet, excessive emphasis on the memory stability often impairs learning plasticity, i.e., the capacity of DNN to acquire new information effectively. To address such stability-plasticity dilemma, this study proposes a novel CL method, synergetic memory rehearsal (SyReM), for DNN-based motion forecasting. SyReM maintains a compact memory buffer to represent learned knowledge. To ensure memory stability, it employs an inequality constraint that limits increments in the average loss over the memory buffer. Synergistically, a selective memory rehearsal mechanism is designed to enhance learning plasticity by selecting samples from the memory buffer that are most similar to recently observed data. This selection is based on an online-measured cosine similarity of loss gradients, ensuring targeted memory rehearsal. Since replayed samples originate from learned scenarios, this memory rehearsal mechanism avoids compromising memory stability. We validate SyReM under an online CL paradigm where training samples from diverse scenarios arrive as a one-pass stream. Experiments on 11 naturalistic driving datasets from INTERACTION demonstrate that, compared to non-CL and CL baselines, SyReM significantly mitigates catastrophic forgetting in past scenarios while improving forecasting accuracy in new ones. The implementation is publicly available at https://github.com/BIT-Jack/SyReM.
Complementary Learning System Empowers Online Continual Learning of Vehicle Motion Forecasting in Smart Cities
Aug 27, 2025



Artificial intelligence underpins most smart city services, yet deep neural network (DNN) that forecasts vehicle motion still struggle with catastrophic forgetting, the loss of earlier knowledge when models are updated. Conventional fixes enlarge the training set or replay past data, but these strategies incur high data collection costs, sample inefficiently and fail to balance long- and short-term experience, leaving them short of human-like continual learning. Here we introduce Dual-LS, a task-free, online continual learning paradigm for DNN-based motion forecasting that is inspired by the complementary learning system of the human brain. Dual-LS pairs two synergistic memory rehearsal replay mechanisms to accelerate experience retrieval while dynamically coordinating long-term and short-term knowledge representations. Tests on naturalistic data spanning three countries, over 772,000 vehicles and cumulative testing mileage of 11,187 km show that Dual-LS mitigates catastrophic forgetting by up to 74.31\% and reduces computational resource demand by up to 94.02\%, markedly boosting predictive stability in vehicle motion forecasting without inflating data requirements. Meanwhile, it endows DNN-based vehicle motion forecasting with computation efficient and human-like continual learning adaptability fit for smart cities.
MultiEditor: Controllable Multimodal Object Editing for Driving Scenarios Using 3D Gaussian Splatting Priors
Jul 30, 2025Autonomous driving systems rely heavily on multimodal perception data to understand complex environments. However, the long-tailed distribution of real-world data hinders generalization, especially for rare but safety-critical vehicle categories. To address this challenge, we propose MultiEditor, a dual-branch latent diffusion framework designed to edit images and LiDAR point clouds in driving scenarios jointly. At the core of our approach is introducing 3D Gaussian Splatting (3DGS) as a structural and appearance prior for target objects. Leveraging this prior, we design a multi-level appearance control mechanism--comprising pixel-level pasting, semantic-level guidance, and multi-branch refinement--to achieve high-fidelity reconstruction across modalities. We further propose a depth-guided deformable cross-modality condition module that adaptively enables mutual guidance between modalities using 3DGS-rendered depth, significantly enhancing cross-modality consistency. Extensive experiments demonstrate that MultiEditor achieves superior performance in visual and geometric fidelity, editing controllability, and cross-modality consistency. Furthermore, generating rare-category vehicle data with MultiEditor substantially enhances the detection accuracy of perception models on underrepresented classes.
The Fourth Monocular Depth Estimation Challenge
Apr 24, 2025


This paper presents the results of the fourth edition of the Monocular Depth Estimation Challenge (MDEC), which focuses on zero-shot generalization to the SYNS-Patches benchmark, a dataset featuring challenging environments in both natural and indoor settings. In this edition, we revised the evaluation protocol to use least-squares alignment with two degrees of freedom to support disparity and affine-invariant predictions. We also revised the baselines and included popular off-the-shelf methods: Depth Anything v2 and Marigold. The challenge received a total of 24 submissions that outperformed the baselines on the test set; 10 of these included a report describing their approach, with most leading methods relying on affine-invariant predictions. The challenge winners improved the 3D F-Score over the previous edition's best result, raising it from 22.58% to 23.05%.
Cross-cultural Deployment of Autonomous Vehicles Using Data-light Inverse Reinforcement Learning
Apr 15, 2025More than the adherence to specific traffic regulations, driving culture touches upon a more implicit part - an informal, conventional, collective behavioral pattern followed by drivers - that varies across countries, regions, and even cities. Such cultural divergence has become one of the biggest challenges in deploying autonomous vehicles (AVs) across diverse regions today. The current emergence of data-driven methods has shown a potential solution to enable culture-compatible driving through learning from data, but what if some underdeveloped regions cannot provide sufficient local data to inform driving culture? This issue is particularly significant for a broader global AV market. Here, we propose a cross-cultural deployment scheme for AVs, called data-light inverse reinforcement learning, designed to re-calibrate culture-specific AVs and assimilate them into other cultures. First, we report the divergence in driving cultures through a comprehensive comparative analysis of naturalistic driving datasets on highways from three countries: Germany, China, and the USA. Then, we demonstrate the effectiveness of our scheme by testing the expeditious cross-cultural deployment across these three countries, with cumulative testing mileage of over 56084 km. The performance is particularly advantageous when cross-cultural deployment is carried out without affluent local data. Results show that we can reduce the dependence on local data by a margin of 98.67% at best. This study is expected to bring a broader, fairer AV global market, particularly in those regions that lack enough local data to develop culture-compatible AVs.
Targetless Intrinsics and Extrinsic Calibration of Multiple LiDARs and Cameras with IMU using Continuous-Time Estimation
Jan 06, 2025



Accurate spatiotemporal calibration is a prerequisite for multisensor fusion. However, sensors are typically asynchronous, and there is no overlap between the fields of view of cameras and LiDARs, posing challenges for intrinsic and extrinsic parameter calibration. To address this, we propose a calibration pipeline based on continuous-time and bundle adjustment (BA) capable of simultaneous intrinsic and extrinsic calibration (6 DOF transformation and time offset). We do not require overlapping fields of view or any calibration board. Firstly, we establish data associations between cameras using Structure from Motion (SFM) and perform self-calibration of camera intrinsics. Then, we establish data associations between LiDARs through adaptive voxel map construction, optimizing for extrinsic calibration within the map. Finally, by matching features between the intensity projection of LiDAR maps and camera images, we conduct joint optimization for intrinsic and extrinsic parameters. This pipeline functions in texture-rich structured environments, allowing simultaneous calibration of any number of cameras and LiDARs without the need for intricate sensor synchronization triggers. Experimental results demonstrate our method's ability to fulfill co-visibility and motion constraints between sensors without accumulating errors.
A History-Guided Regional Partitioning Evolutionary Optimization for Solving the Flexible Job Shop Problem with Limited Multi-load Automated Guided Vehicles
Sep 27, 2024In a flexible job shop environment, using Automated Guided Vehicles (AGVs) to transport jobs and process materials is an important way to promote the intelligence of the workshop. Compared with single-load AGVs, multi-load AGVs can improve AGV utilization, reduce path conflicts, etc. Therefore, this study proposes a history-guided regional partitioning algorithm (HRPEO) for the flexible job shop scheduling problem with limited multi-load AGVs (FJSPMA). First, the encoding and decoding rules are designed according to the characteristics of multi-load AGVs, and then the initialization rule based on the branch and bound method is used to generate the initial population. Second, to prevent the algorithm from falling into a local optimum, the algorithm adopts a regional partitioning strategy. This strategy divides the solution space into multiple regions and measures the potential of the regions. After that, cluster the regions into multiple clusters in each iteration, and selects individuals for evolutionary search based on the set of clusters. Third, a local search strategy is designed to improve the exploitation ability of the algorithm, which uses a greedy approach to optimize machines selection and transportation sequence according to the characteristics of FJSPMA. Finally, a large number of experiments are carried out on the benchmarks to test the performance of the algorithm. Compared with multiple advanced algorithms, the results show that the HRPEO has a better advantage in solving FJSPMA.