 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAIL: Scene-aware Adaptive Iterative Learning for Long-Tail Trajectory Prediction in Autonomous Vehicles
Apr 06, 2026Autonomous vehicles (AVs) rely on accurate trajectory prediction for safe navigation in diverse traffic environments, yet existing models struggle with long-tail scenarios-rare but safety-critical events characterized by abrupt maneuvers, high collision risks, and complex interactions. These challenges stem from data imbalance, inadequate definitions of long-tail trajectories, and suboptimal learning strategies that prioritize common behaviors over infrequent ones. To address this, we propose SAIL, a novel framework that systematically tackles the long-tail problem by first defining and modeling trajectories across three key attribute dimensions: prediction error, collision risk, and state complexity. Our approach then synergizes an attribute-guided augmentation and feature extraction process with a highly adaptive contrastive learning strategy. This strategy employs a continuous cosine momentum schedule, similarity-weighted hard-negative mining, and a dynamic pseudo-labeling mechanism based on evolving feature clustering. Furthermore, it incorporates a focusing mechanism to intensify learning on hard-positive samples within each identified class. This comprehensive design enables SAIL to excel at identifying and forecasting diverse and challenging long-tail events. Extensive evaluations on the nuScenes and ETH/UCY datasets demonstrate SAIL's superior performance, achieving up to 28.8% reduction in prediction error on the hardest 1% of long-tail samples compared to state-of-the-art baselines, while maintaining competitive accuracy across all scenarios. This framework advances reliable AV trajectory prediction in real-world, mixed-autonomy settings.
Language-Grounded Multi-Agent Planning for Personalized and Fair Participatory Urban Sensing
Mar 25, 2026Participatory urban sensing leverages human mobility for large-scale urban data collection, yet existing methods typically rely on centralized optimization and assume homogeneous participants, resulting in rigid assignments that overlook personal preferences and heterogeneous urban contexts. We propose MAPUS, an LLM-based multi-agent framework for personalized and fair participatory urban sensing. In our framework, participants are modeled as autonomous agents with individual profiles and schedules, while a coordinator agent performs fairness-aware selection and refines sensing routes through language-based negotiation. Experiments on real-world datasets show that MAPUS achieves competitive sensing coverage while substantially improving participant satisfaction and fairness, promoting more human-centric and sustainable urban sensing systems.
Can Large Multimodal Models Inspect Buildings? A Hierarchical Benchmark for Structural Pathology Reasoning
Mar 20, 2026Automated building facade inspection is a critical component of urban resilience and smart city maintenance. Traditionally, this field has relied on specialized discriminative models (e.g., YOLO, Mask R-CNN) that excel at pixel-level localization but are constrained to passive perception and worse generization without the visual understandng to interpret structural topology. Large Multimodal Models (LMMs) promise a paradigm shift toward active reasoning, yet their application in such high-stakes engineering domains lacks rigorous evaluation standards. To bridge this gap, we introduce a human-in-the-loop semi-automated annotation framework, leveraging expert-proposal verification to unify 12 fragmented datasets into a standardized, hierarchical ontology. Building on this foundation, we present \textit{DefectBench}, the first multi-dimensional benchmark designed to interrogate LMMs beyond basic semantic recognition. \textit{DefectBench} evaluates 18 state-of-the-art (SOTA) LMMs across three escalating cognitive dimensions: Semantic Perception, Spatial Localization, and Generative Geometry Segmentation. Extensive experiments reveal that while current LMMs demonstrate exceptional topological awareness and semantic understanding (effectively diagnosing "what" and "how"), they exhibit significant deficiencies in metric localization precision ("where"). Crucially, however, we validate the viability of zero-shot generative segmentation, showing that general-purpose foundation models can rival specialized supervised networks without domain-specific training. This work provides both a rigorous benchmarking standard and a high-quality open-source database, establishing a new baseline for the advancement of autonomous AI agents in civil engineering.
Coordinated Pandemic Control with Large Language Model Agents as Policymaking Assistants
Jan 14, 2026Effective pandemic control requires timely and coordinated policymaking across administrative regions that are intrinsically interdependent. However, human-driven responses are often fragmented and reactive, with policies formulated in isolation and adjusted only after outbreaks escalate, undermining proactive intervention and global pandemic mitigation. To address this challenge, here we propose a large language model (LLM) multi-agent policymaking framework that supports coordinated and proactive pandemic control across regions. Within our framework, each administrative region is assigned an LLM agent as an AI policymaking assistant. The agent reasons over region-specific epidemiological dynamics while communicating with other agents to account for cross-regional interdependencies. By integrating real-world data, a pandemic evolution simulator, and structured inter-agent communication, our framework enables agents to jointly explore counterfactual intervention scenarios and synthesize coordinated policy decisions through a closed-loop simulation process. We validate the proposed framework using state-level COVID-19 data from the United States between April and December 2020, together with real-world mobility records and observed policy interventions. Compared with real-world pandemic outcomes, our approach reduces cumulative infections and deaths by up to 63.7% and 40.1%, respectively, at the individual state level, and by 39.0% and 27.0%, respectively, when aggregated across states. These results demonstrate that LLM multi-agent systems can enable more effective pandemic control with coordinated policymaking...
LLM-ODDR: A Large Language Model Framework for Joint Order Dispatching and Driver Repositioning
May 28, 2025Ride-hailing platforms face significant challenges in optimizing order dispatching and driver repositioning operations in dynamic urban environments. Traditional approaches based on combinatorial optimization, rule-based heuristics, and reinforcement learning often overlook driver income fairness, interpretability, and adaptability to real-world dynamics. To address these gaps, we propose LLM-ODDR, a novel framework leveraging Large Language Models (LLMs) for joint Order Dispatching and Driver Repositioning (ODDR) in ride-hailing services. LLM-ODDR framework comprises three key components: (1) Multi-objective-guided Order Value Refinement, which evaluates orders by considering multiple objectives to determine their overall value; (2) Fairness-aware Order Dispatching, which balances platform revenue with driver income fairness; and (3) Spatiotemporal Demand-Aware Driver Repositioning, which optimizes idle vehicle placement based on historical patterns and projected supply. We also develop JointDR-GPT, a fine-tuned model optimized for ODDR tasks with domain knowledge. Extensive experiments on real-world datasets from Manhattan taxi operations demonstrate that our framework significantly outperforms traditional methods in terms of effectiveness, adaptability to anomalous conditions, and decision interpretability. To our knowledge, this is the first exploration of LLMs as decision-making agents in ride-hailing ODDR tasks, establishing foundational insights for integrating advanced language models within intelligent transportation systems.
LD-Scene: LLM-Guided Diffusion for Controllable Generation of Adversarial Safety-Critical Driving Scenarios
May 16, 2025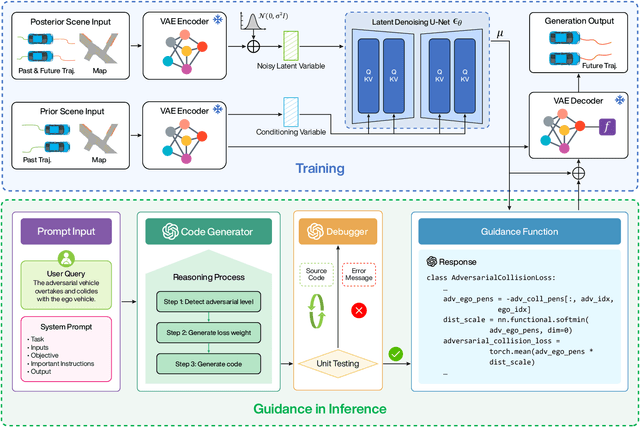

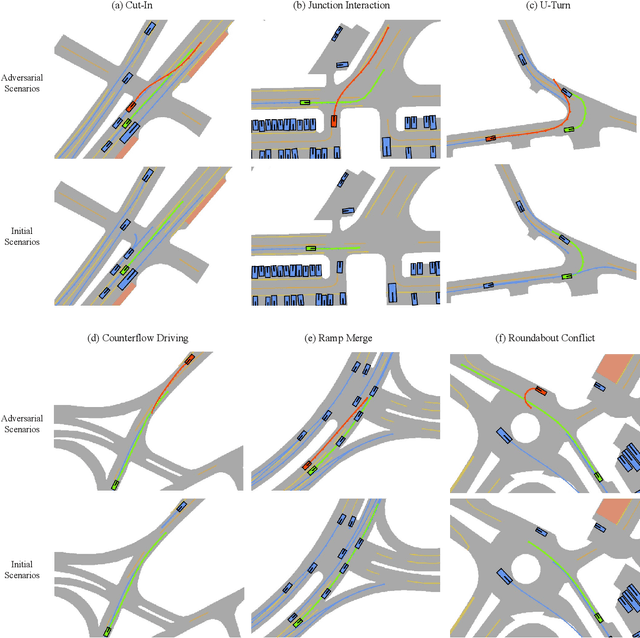

Ensuring the safety and robustness of autonomous driving systems necessitates a comprehensive evaluation in safety-critical scenarios. However, these safety-critical scenarios are rare and difficult to collect from real-world driving data, posing significant challenges to effectively assessing the performance of autonomous vehicles. Typical existing methods often suffer from limited controllability and lack user-friendliness, as extensive expert knowledge is essentially required. To address these challenges, we propose LD-Scene, a novel framework that integrates Large Language Models (LLMs) with Latent Diffusion Models (LDMs) for user-controllable adversarial scenario generation through natural language. Our approach comprises an LDM that captures realistic driving trajectory distributions and an LLM-based guidance module that translates user queries into adversarial loss functions, facilitating the generation of scenarios aligned with user queries. The guidance module integrates an LLM-based Chain-of-Thought (CoT) code generator and an LLM-based code debugger, enhancing the controllability and robustness in generating guidance functions. Extensive experiments conducted on the nuScenes dataset demonstrate that LD-Scene achieves state-of-the-art performance in generating realistic, diverse, and effective adversarial scenarios. Furthermore, our framework provides fine-grained control over adversarial behaviors, thereby facilitating more effective testing tailored to specific driving scenarios.
Cross-cultural Deployment of Autonomous Vehicles Using Data-light Inverse Reinforcement Learning
Apr 15, 2025More than the adherence to specific traffic regulations, driving culture touches upon a more implicit part - an informal, conventional, collective behavioral pattern followed by drivers - that varies across countries, regions, and even cities. Such cultural divergence has become one of the biggest challenges in deploying autonomous vehicles (AVs) across diverse regions today. The current emergence of data-driven methods has shown a potential solution to enable culture-compatible driving through learning from data, but what if some underdeveloped regions cannot provide sufficient local data to inform driving culture? This issue is particularly significant for a broader global AV market. Here, we propose a cross-cultural deployment scheme for AVs, called data-light inverse reinforcement learning, designed to re-calibrate culture-specific AVs and assimilate them into other cultures. First, we report the divergence in driving cultures through a comprehensive comparative analysis of naturalistic driving datasets on highways from three countries: Germany, China, and the USA. Then, we demonstrate the effectiveness of our scheme by testing the expeditious cross-cultural deployment across these three countries, with cumulative testing mileage of over 56084 km. The performance is particularly advantageous when cross-cultural deployment is carried out without affluent local data. Results show that we can reduce the dependence on local data by a margin of 98.67% at best. This study is expected to bring a broader, fairer AV global market, particularly in those regions that lack enough local data to develop culture-compatible AVs.
Deployment-friendly Lane-changing Intention Prediction Powered by Brain-inspired Spiking Neural Networks
Feb 09, 2025Accurate and real-time prediction of surrounding vehicles' lane-changing intentions is a critical challenge in deploying safe and efficient autonomous driving systems in open-world scenarios. Existing high-performing methods remain hard to deploy due to their high computational cost, long training times, and excessive memory requirements. Here, we propose an efficient lane-changing intention prediction approach based on brain-inspired Spiking Neural Networks (SNN). By leveraging the event-driven nature of SNN, the proposed approach enables us to encode the vehicle's states in a more efficient manner. Comparison experiments conducted on HighD and NGSIM datasets demonstrate that our method significantly improves training efficiency and reduces deployment costs while maintaining comparable prediction accuracy. Particularly, compared to the baseline, our approach reduces training time by 75% and memory usage by 99.9%. These results validate the efficiency and reliability of our method in lane-changing predictions, highlighting its potential for safe and efficient autonomous driving systems while offering significant advantages in deployment, including reduced training time, lower memory usage, and faster inference.
FedRTS: Federated Robust Pruning via Combinatorial Thompson Sampling
Jan 31, 2025



Federated Learning (FL) enables collaborative model training across distributed clients without data sharing, but its high computational and communication demands strain resource-constrained devices. While existing methods use dynamic pruning to improve efficiency by periodically adjusting sparse model topologies while maintaining sparsity, these approaches suffer from issues such as greedy adjustments, unstable topologies, and communication inefficiency, resulting in less robust models and suboptimal performance under data heterogeneity and partial client availability. To address these challenges, we propose Federated Robust pruning via combinatorial Thompson Sampling (FedRTS), a novel framework designed to develop robust sparse models. FedRTS enhances robustness and performance through its Thompson Sampling-based Adjustment (TSAdj) mechanism, which uses probabilistic decisions informed by stable, farsighted information instead of deterministic decisions reliant on unstable and myopic information in previous methods. Extensive experiments demonstrate that FedRTS achieves state-of-the-art performance in computer vision and natural language processing tasks while reducing communication costs, particularly excelling in scenarios with heterogeneous data distributions and partial client participation. Our codes are available at: https://github.com/Little0o0/FedRTS
Automating Traffic Model Enhancement with AI Research Agent
Sep 25, 2024



Developing efficient traffic models is essential for optimizing transportation systems, yet current approaches remain time-intensive and susceptible to human errors due to their reliance on manual processes. Traditional workflows involve exhaustive literature reviews, formula optimization, and iterative testing, leading to inefficiencies in research. In response, we introduce the Traffic Research Agent (TR-Agent), an AI-driven system designed to autonomously develop and refine traffic models through an iterative, closed-loop process. Specifically, we divide the research pipeline into four key stages: idea generation, theory formulation, theory evaluation, and iterative optimization; and construct TR-Agent with four corresponding modules: Idea Generator, Code Generator, Evaluator, and Analyzer. Working in synergy, these modules retrieve knowledge from external resources, generate novel ideas, implement and debug models, and finally assess them on the evaluation datasets. Furthermore, the system continuously refines these models based on iterative feedback, enhancing research efficiency and model performance. Experimental results demonstrate that TR-Agent achieves significant performance improvements across multiple traffic models, including the Intelligent Driver Model (IDM) for car following, the MOBIL lane-changing model, and the Lighthill-Whitham-Richards (LWR) traffic flow model. Additionally, TR-Agent provides detailed explanations for its optimizations, allowing researchers to verify and build upon its improvements easily. This flexibility makes the framework a powerful tool for researchers in transportation and beyond. To further support research and collaboration, we have open-sourced both the code and data used in our experiments, facilitating broader access and enabling continued advancements in the field.