 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTAU-R1: Visual Language Model for Traffic Anomaly Understanding
Mar 19, 2026Traffic Anomaly Understanding (TAU) is important for traffic safety in Intelligent Transportation Systems. Recent vision-language models (VLMs) have shown strong capabilities in video understanding. However, progress on TAU remains limited due to the lack of benchmarks and task-specific methodologies. To address this limitation, we introduce Roundabout-TAU, a dataset constructed from real-world roundabout videos collected in collaboration with the City of Carmel, Indiana. The dataset contains 342 clips and is annotated with more than 2,000 question-answer pairs covering multiple aspects of traffic anomaly understanding. Building on this benchmark, we propose TAU-R1, a two-layer vision-language framework for TAU. The first layer is a lightweight anomaly classifier that performs coarse anomaly categorisation, while the second layer is a larger anomaly reasoner that generates detailed event summaries. To improve task-specific reasoning, we introduce a two-stage training strategy consisting of decomposed-QA-enhanced supervised fine-tuning followed by TAU-GRPO, a GRPO-based post-training method with TAU-specific reward functions. Experimental results show that TAU-R1 achieves strong performance on both anomaly classification and reasoning tasks while maintaining deployment efficiency. The dataset and code are available at: https://github.com/siri-rouser/TAU-R1
Diffusion^2: Dual Diffusion Model with Uncertainty-Aware Adaptive Noise for Momentary Trajectory Prediction
Oct 05, 2025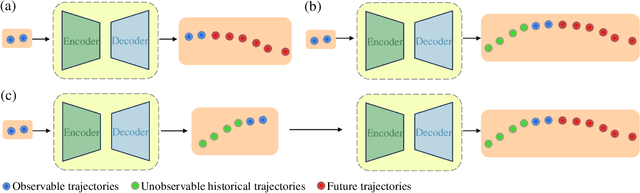
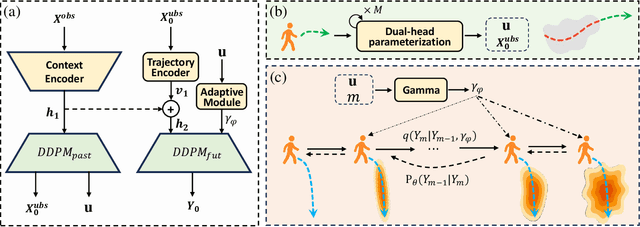
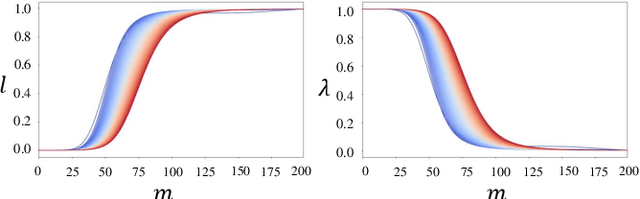
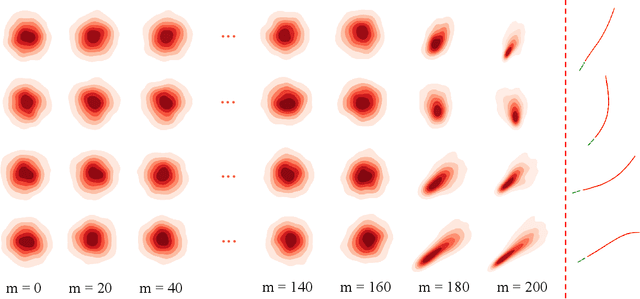
Accurate pedestrian trajectory prediction is crucial for ensuring safety and efficiency in autonomous driving and human-robot interaction scenarios. Earlier studies primarily utilized sufficient observational data to predict future trajectories. However, in real-world scenarios, such as pedestrians suddenly emerging from blind spots, sufficient observational data is often unavailable (i.e. momentary trajectory), making accurate prediction challenging and increasing the risk of traffic accidents. Therefore, advancing research on pedestrian trajectory prediction under extreme scenarios is critical for enhancing traffic safety. In this work, we propose a novel framework termed Diffusion^2, tailored for momentary trajectory prediction. Diffusion^2 consists of two sequentially connected diffusion models: one for backward prediction, which generates unobserved historical trajectories, and the other for forward prediction, which forecasts future trajectories. Given that the generated unobserved historical trajectories may introduce additional noise, we propose a dual-head parameterization mechanism to estimate their aleatoric uncertainty and design a temporally adaptive noise module that dynamically modulates the noise scale in the forward diffusion process. Empirically, Diffusion^2 sets a new state-of-the-art in momentary trajectory prediction on ETH/UCY and Stanford Drone datasets.
Collaborative-Distilled Diffusion Models (CDDM) for Accelerated and Lightweight Trajectory Prediction
Oct 01, 2025Trajectory prediction is a fundamental task in Autonomous Vehicles (AVs) and Intelligent Transportation Systems (ITS), supporting efficient motion planning and real-time traffic safety management. Diffusion models have recently demonstrated strong performance in probabilistic trajectory prediction, but their large model size and slow sampling process hinder real-world deployment. This paper proposes Collaborative-Distilled Diffusion Models (CDDM), a novel method for real-time and lightweight trajectory prediction. Built upon Collaborative Progressive Distillation (CPD), CDDM progressively transfers knowledge from a high-capacity teacher diffusion model to a lightweight student model, jointly reducing both the number of sampling steps and the model size across distillation iterations. A dual-signal regularized distillation loss is further introduced to incorporate guidance from both the teacher and ground-truth data, mitigating potential overfitting and ensuring robust performance. Extensive experiments on the ETH-UCY pedestrian benchmark and the nuScenes vehicle benchmark demonstrate that CDDM achieves state-of-the-art prediction accuracy. The well-distilled CDDM retains 96.2% and 95.5% of the baseline model's ADE and FDE performance on pedestrian trajectories, while requiring only 231K parameters and 4 or 2 sampling steps, corresponding to 161x compression, 31x acceleration, and 9 ms latency. Qualitative results further show that CDDM generates diverse and accurate trajectories under dynamic agent behaviors and complex social interactions. By bridging high-performing generative models with practical deployment constraints, CDDM enables resource-efficient probabilistic prediction for AVs and ITS. Code is available at https://github.com/bingzhangw/CDDM.
ChronoForge-RL: Chronological Forging through Reinforcement Learning for Enhanced Video Understanding
Sep 19, 2025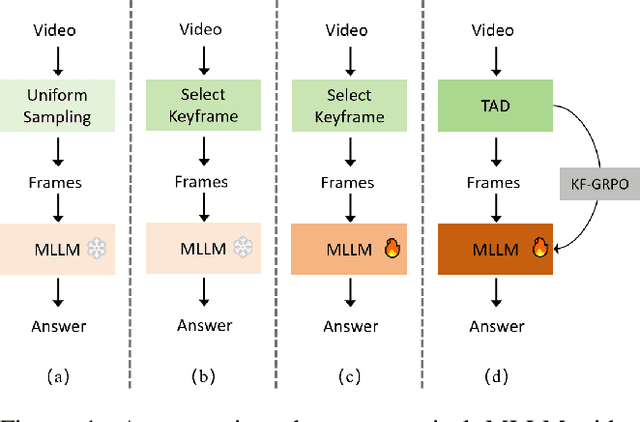
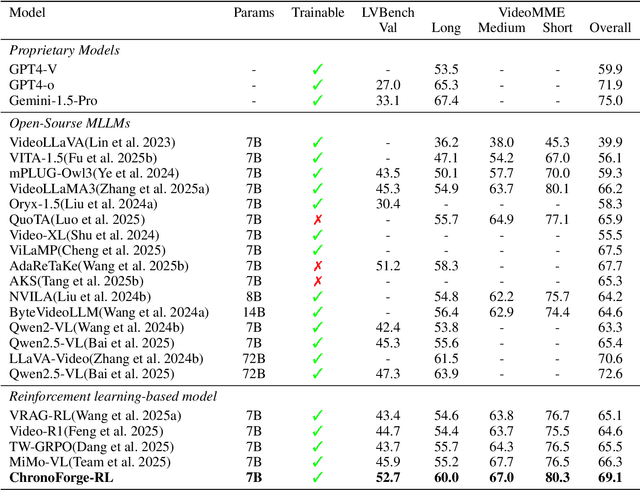
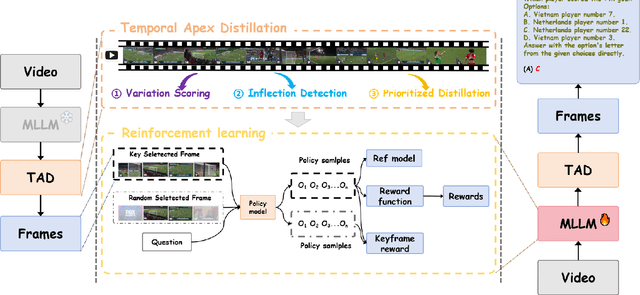
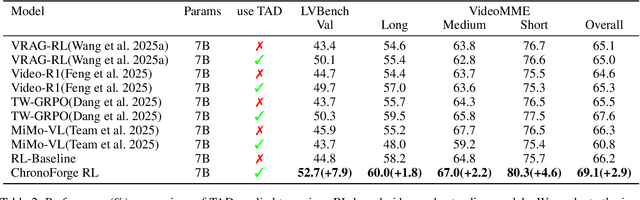
Current state-of-the-art video understanding methods typically struggle with two critical challenges: (1) the computational infeasibility of processing every frame in dense video content and (2) the difficulty in identifying semantically significant frames through naive uniform sampling strategies. In this paper, we propose a novel video understanding framework, called ChronoForge-RL, which combines Temporal Apex Distillation (TAD) and KeyFrame-aware Group Relative Policy Optimization (KF-GRPO) to tackle these issues. Concretely, we introduce a differentiable keyframe selection mechanism that systematically identifies semantic inflection points through a three-stage process to enhance computational efficiency while preserving temporal information. Then, two particular modules are proposed to enable effective temporal reasoning: Firstly, TAD leverages variation scoring, inflection detection, and prioritized distillation to select the most informative frames. Secondly, we introduce KF-GRPO which implements a contrastive learning paradigm with a saliency-enhanced reward mechanism that explicitly incentivizes models to leverage both frame content and temporal relationships. Finally, our proposed ChronoForge-RL achieves 69.1% on VideoMME and 52.7% on LVBench compared to baseline methods, clearly surpassing previous approaches while enabling our 7B parameter model to achieve performance comparable to 72B parameter alternatives.
DVP-MVS++: Synergize Depth-Normal-Edge and Harmonized Visibility Prior for Multi-View Stereo
Jun 16, 2025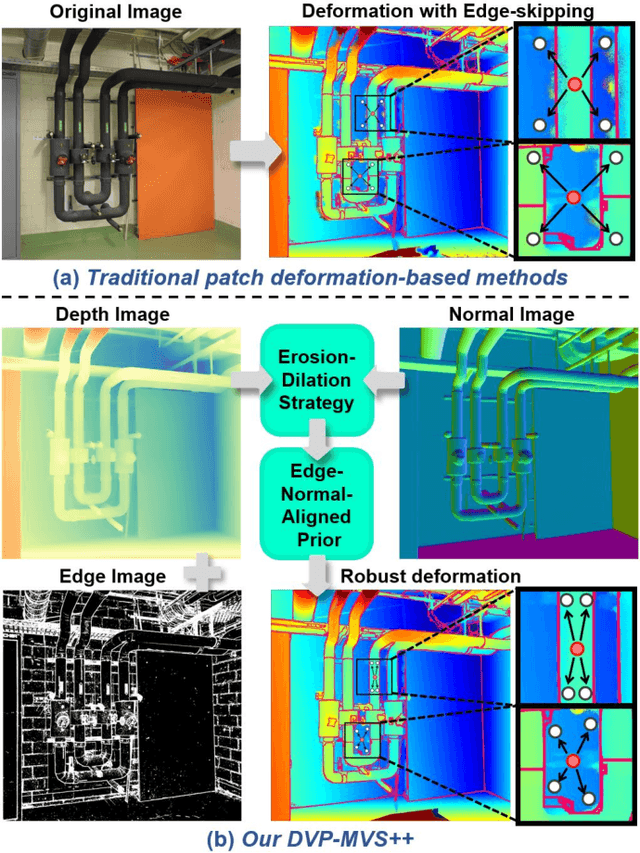
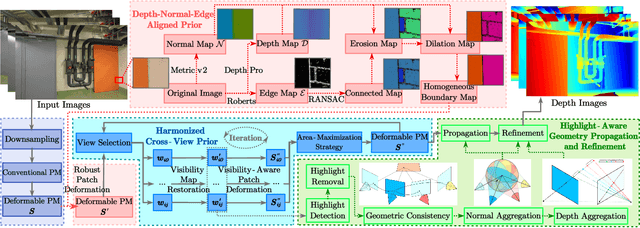
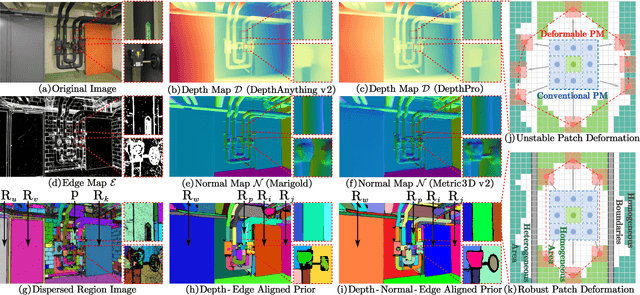
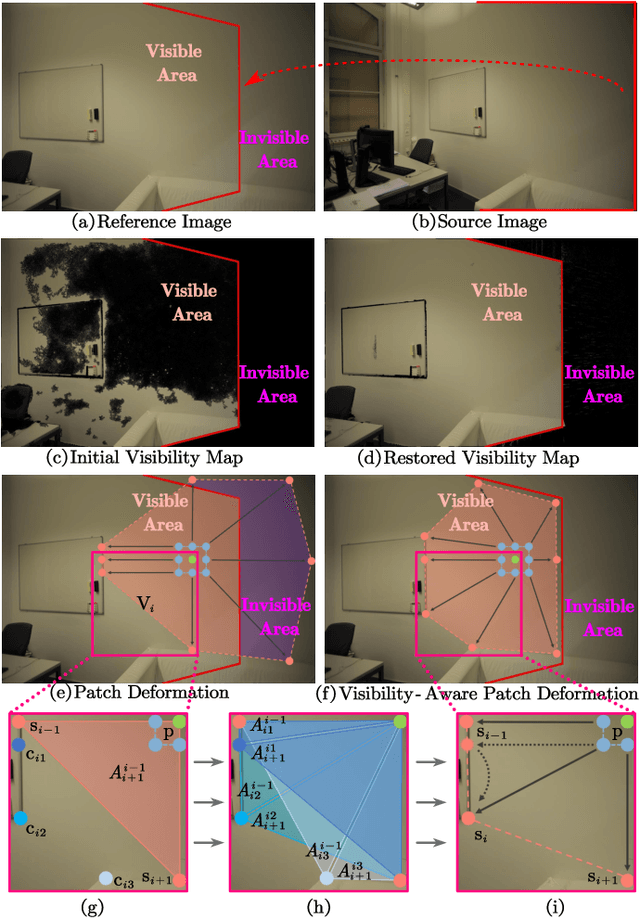
Recently, patch deformation-based methods have demonstrated significant effectiveness in multi-view stereo due to their incorporation of deformable and expandable perception for reconstructing textureless areas. However, these methods generally focus on identifying reliable pixel correlations to mitigate matching ambiguity of patch deformation, while neglecting the deformation instability caused by edge-skipping and visibility occlusions, which may cause potential estimation deviations. To address these issues, we propose DVP-MVS++, an innovative approach that synergizes both depth-normal-edge aligned and harmonized cross-view priors for robust and visibility-aware patch deformation. Specifically, to avoid edge-skipping, we first apply DepthPro, Metric3Dv2 and Roberts operator to generate coarse depth maps, normal maps and edge maps, respectively. These maps are then aligned via an erosion-dilation strategy to produce fine-grained homogeneous boundaries for facilitating robust patch deformation. Moreover, we reformulate view selection weights as visibility maps, and then implement both an enhanced cross-view depth reprojection and an area-maximization strategy to help reliably restore visible areas and effectively balance deformed patch, thus acquiring harmonized cross-view priors for visibility-aware patch deformation. Additionally, we obtain geometry consistency by adopting both aggregated normals via view selection and projection depth differences via epipolar lines, and then employ SHIQ for highlight correction to enable geometry consistency with highlight-aware perception, thus improving reconstruction quality during propagation and refinement stage. Evaluation results on ETH3D, Tanks & Temples and Strecha datasets exhibit the state-of-the-art performance and robust generalization capability of our proposed method.
Deep Fictitious Play-Based Potential Differential Games for Learning Human-Like Interaction at Unsignalized Intersections
Jun 14, 2025Modeling vehicle interactions at unsignalized intersections is a challenging task due to the complexity of the underlying game-theoretic processes. Although prior studies have attempted to capture interactive driving behaviors, most approaches relied solely on game-theoretic formulations and did not leverage naturalistic driving datasets. In this study, we learn human-like interactive driving policies at unsignalized intersections using Deep Fictitious Play. Specifically, we first model vehicle interactions as a Differential Game, which is then reformulated as a Potential Differential Game. The weights in the cost function are learned from the dataset and capture diverse driving styles. We also demonstrate that our framework provides a theoretical guarantee of convergence to a Nash equilibrium. To the best of our knowledge, this is the first study to train interactive driving policies using Deep Fictitious Play. We validate the effectiveness of our Deep Fictitious Play-Based Potential Differential Game (DFP-PDG) framework using the INTERACTION dataset. The results demonstrate that the proposed framework achieves satisfactory performance in learning human-like driving policies. The learned individual weights effectively capture variations in driver aggressiveness and preferences. Furthermore, the ablation study highlights the importance of each component within our model.
SemiHMER: Semi-supervised Handwritten Mathematical Expression Recognition using pseudo-labels
Feb 11, 2025



In recent years, deep learning with Convolutional Neural Networks (CNNs) has achieved remarkable results in the field of HMER (Handwritten Mathematical Expression Recognition). However, it remains challenging to improve performance with limited labeled training data. This paper presents, for the first time, a simple yet effective semi-supervised HMER framework by introducing dual-branch semi-supervised learning. Specifically, we simplify the conventional deep co-training from consistency regularization to cross-supervised learning, where the prediction of one branch is used as a pseudo-label to supervise the other branch directly end-to-end. Considering that the learning of the two branches tends to converge in the later stages of model optimization, we also incorporate a weak-to-strong strategy by applying different levels of augmentation to each branch, which behaves like expanding the training data and improving the quality of network training. Meanwhile, We propose a novel module, Global Dynamic Counting Module(GDCM), to enhance the performance of the HMER decoder, which alleviates recognition inaccuracies in long-distance formula recognition and the occurrence of repeated characters. We release our code at https://github.com/chenkehua/SemiHMER.
* 12 pages,3 figures
MMHMER:Multi-viewer and Multi-task for Handwritten Mathematical Expression Recognition
Feb 08, 2025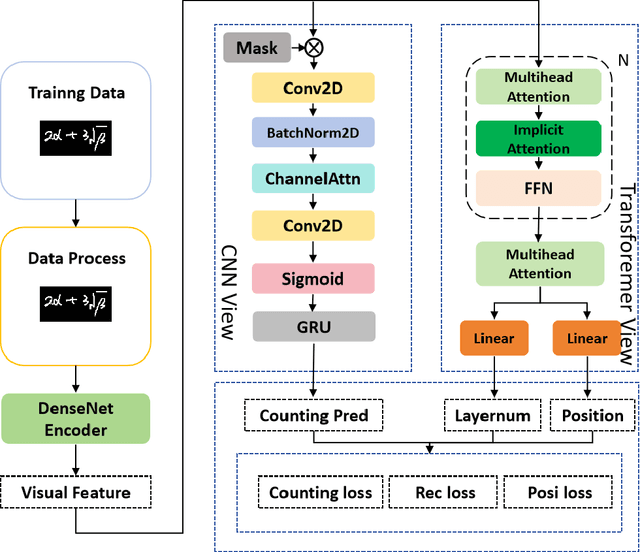

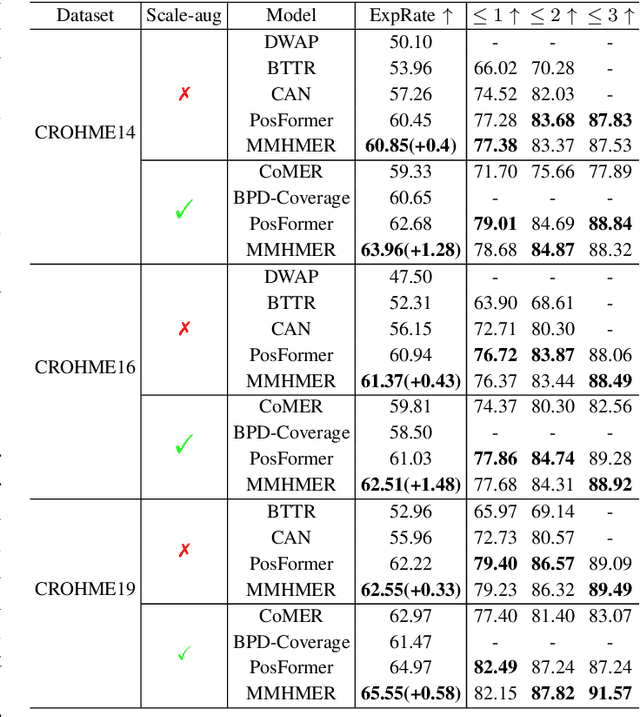
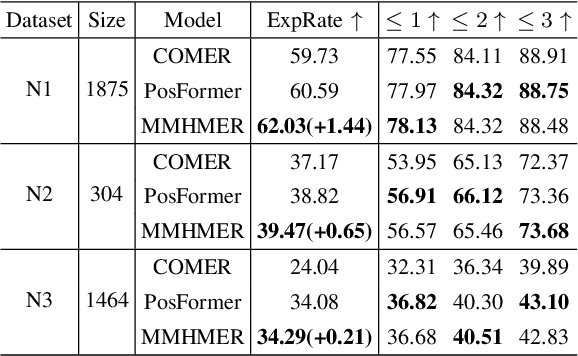
Handwritten Mathematical Expression Recognition (HMER) methods have made remarkable progress, with most existing HMER approaches based on either a hybrid CNN/RNN-based with GRU architecture or Transformer architectures. Each of these has its strengths and weaknesses. Leveraging different model structures as viewers and effectively integrating their diverse capabilities presents an intriguing avenue for exploration. This involves addressing two key challenges: 1) How to fuse these two methods effectively, and 2) How to achieve higher performance under an appropriate level of complexity. This paper proposes an efficient CNN-Transformer multi-viewer, multi-task approach to enhance the model's recognition performance. Our MMHMER model achieves 63.96%, 62.51%, and 65.46% ExpRate on CROHME14, CROHME16, and CROHME19, outperforming Posformer with an absolute gain of 1.28%, 1.48%, and 0.58%. The main contribution of our approach is that we propose a new multi-view, multi-task framework that can effectively integrate the strengths of CNN and Transformer. By leveraging the feature extraction capabilities of CNN and the sequence modeling capabilities of Transformer, our model can better handle the complexity of handwritten mathematical expressions.
Dual-Level Precision Edges Guided Multi-View Stereo with Accurate Planarization
Dec 29, 2024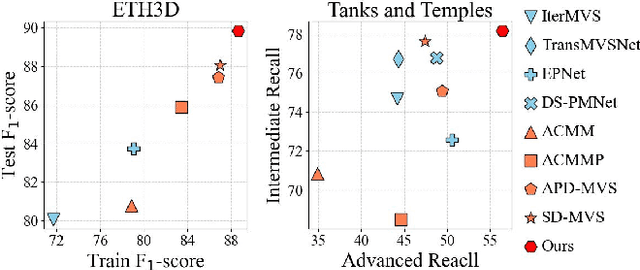
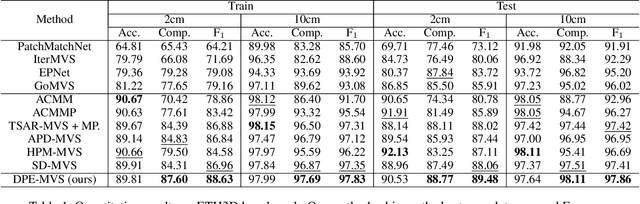

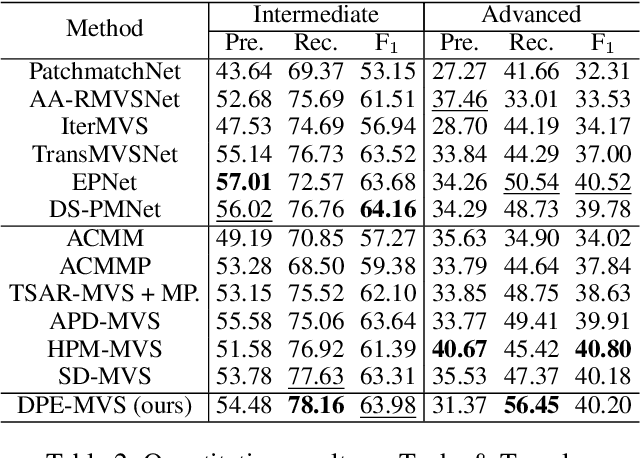
The reconstruction of low-textured areas is a prominent research focus in multi-view stereo (MVS). In recent years, traditional MVS methods have performed exceptionally well in reconstructing low-textured areas by constructing plane models. However, these methods often encounter issues such as crossing object boundaries and limited perception ranges, which undermine the robustness of plane model construction. Building on previous work (APD-MVS), we propose the DPE-MVS method. By introducing dual-level precision edge information, including fine and coarse edges, we enhance the robustness of plane model construction, thereby improving reconstruction accuracy in low-textured areas. Furthermore, by leveraging edge information, we refine the sampling strategy in conventional PatchMatch MVS and propose an adaptive patch size adjustment approach to optimize matching cost calculation in both stochastic and low-textured areas. This additional use of edge information allows for more precise and robust matching. Our method achieves state-of-the-art performance on the ETH3D and Tanks & Temples benchmarks. Notably, our method outperforms all published methods on the ETH3D benchmark.
Dynamic High-Order Control Barrier Functions with Diffuser for Safety-Critical Trajectory Planning at Signal-Free Intersections
Nov 29, 2024



Planning safe and efficient trajectories through signal-free intersections presents significant challenges for autonomous vehicles (AVs), particularly in dynamic, multi-task environments with unpredictable interactions and an increased possibility of conflicts. This study aims to address these challenges by developing a robust, adaptive framework to ensure safety in such complex scenarios. Existing approaches often struggle to provide reliable safety mechanisms in dynamic and learn multi-task behaviors from demonstrations in signal-free intersections. This study proposes a safety-critical planning method that integrates Dynamic High-Order Control Barrier Functions (DHOCBF) with a diffusion-based model, called Dynamic Safety-Critical Diffuser (DSC-Diffuser), offering a robust solution for adaptive, safe, and multi-task driving in signal-free intersections. Our approach incorporates a goal-oriented, task-guided diffusion model, enabling the model to learn multiple driving tasks simultaneously from real-world data. To further ensure driving safety in dynamic environments, the proposed DHOCBF framework dynamically adjusts to account for the movements of surrounding vehicles, offering enhanced adaptability compared to traditional control barrier functions. Validity evaluations of DHOCBF, conducted through numerical simulations, demonstrate its robustness in adapting to variations in obstacle velocities, sizes, uncertainties, and locations, effectively maintaining driving safety across a wide range of complex and uncertain scenarios. Performance evaluations across various scenes confirm that DSC-Diffuser provides realistic, stable, and generalizable policies, equipping it with the flexibility to adapt to diverse driving tasks.