 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemiHMER: Semi-supervised Handwritten Mathematical Expression Recognition using pseudo-labels
Feb 11, 2025



In recent years, deep learning with Convolutional Neural Networks (CNNs) has achieved remarkable results in the field of HMER (Handwritten Mathematical Expression Recognition). However, it remains challenging to improve performance with limited labeled training data. This paper presents, for the first time, a simple yet effective semi-supervised HMER framework by introducing dual-branch semi-supervised learning. Specifically, we simplify the conventional deep co-training from consistency regularization to cross-supervised learning, where the prediction of one branch is used as a pseudo-label to supervise the other branch directly end-to-end. Considering that the learning of the two branches tends to converge in the later stages of model optimization, we also incorporate a weak-to-strong strategy by applying different levels of augmentation to each branch, which behaves like expanding the training data and improving the quality of network training. Meanwhile, We propose a novel module, Global Dynamic Counting Module(GDCM), to enhance the performance of the HMER decoder, which alleviates recognition inaccuracies in long-distance formula recognition and the occurrence of repeated characters. We release our code at https://github.com/chenkehua/SemiHMER.
* 12 pages,3 figures
MMHMER:Multi-viewer and Multi-task for Handwritten Mathematical Expression Recognition
Feb 08, 2025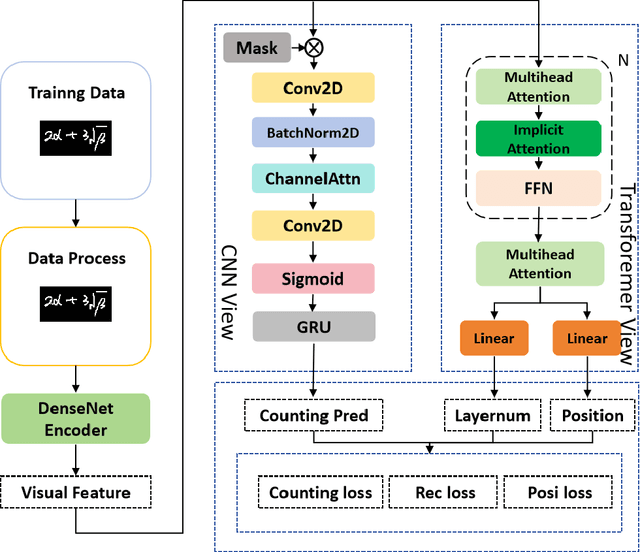

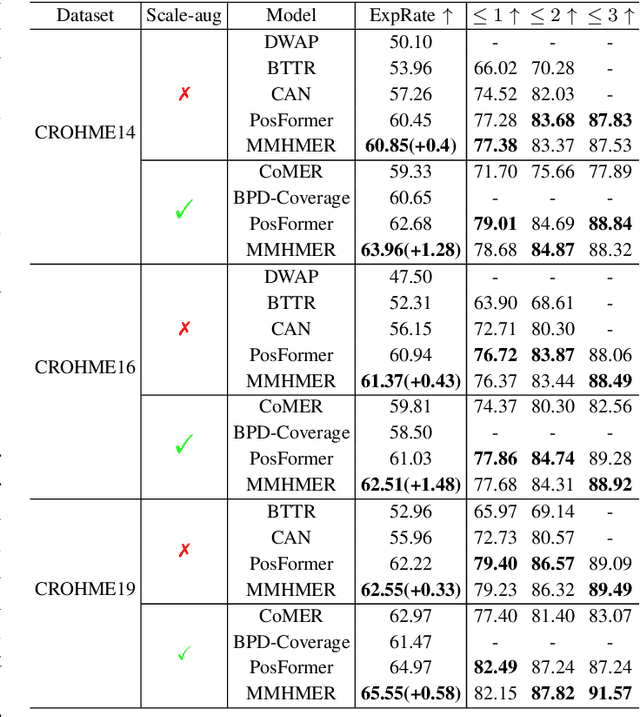
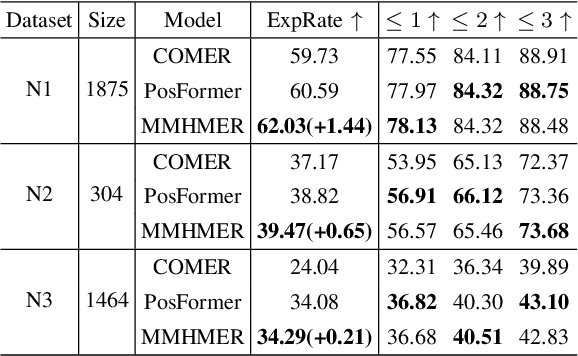
Handwritten Mathematical Expression Recognition (HMER) methods have made remarkable progress, with most existing HMER approaches based on either a hybrid CNN/RNN-based with GRU architecture or Transformer architectures. Each of these has its strengths and weaknesses. Leveraging different model structures as viewers and effectively integrating their diverse capabilities presents an intriguing avenue for exploration. This involves addressing two key challenges: 1) How to fuse these two methods effectively, and 2) How to achieve higher performance under an appropriate level of complexity. This paper proposes an efficient CNN-Transformer multi-viewer, multi-task approach to enhance the model's recognition performance. Our MMHMER model achieves 63.96%, 62.51%, and 65.46% ExpRate on CROHME14, CROHME16, and CROHME19, outperforming Posformer with an absolute gain of 1.28%, 1.48%, and 0.58%. The main contribution of our approach is that we propose a new multi-view, multi-task framework that can effectively integrate the strengths of CNN and Transformer. By leveraging the feature extraction capabilities of CNN and the sequence modeling capabilities of Transformer, our model can better handle the complexity of handwritten mathematical expressions.
GDN: A Stacking Network Used for Skin Cancer Diagnosis
Dec 05, 2023Skin cancer, the primary type of cancer that can be identified by visual recognition, requires an automatic identification system that can accurately classify different types of lesions. This paper presents GoogLe-Dense Network (GDN), which is an image-classification model to identify two types of skin cancer, Basal Cell Carcinoma, and Melanoma. GDN uses stacking of different networks to enhance the model performance. Specifically, GDN consists of two sequential levels in its structure. The first level performs basic classification tasks accomplished by GoogLeNet and DenseNet, which are trained in parallel to enhance efficiency. To avoid low accuracy and long training time, the second level takes the output of the GoogLeNet and DenseNet as the input for a logistic regression model. We compare our method with four baseline networks including ResNet, VGGNet, DenseNet, and GoogLeNet on the dataset, in which GoogLeNet and DenseNet significantly outperform ResNet and VGGNet. In the second level, different stacking methods such as perceptron, logistic regression, SVM, decision trees and K-neighbor are studied in which Logistic Regression shows the best prediction result among all. The results prove that GDN, compared to a single network structure, has higher accuracy in optimizing skin cancer detection.