 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMMHMER:Multi-viewer and Multi-task for Handwritten Mathematical Expression Recognition
Feb 08, 2025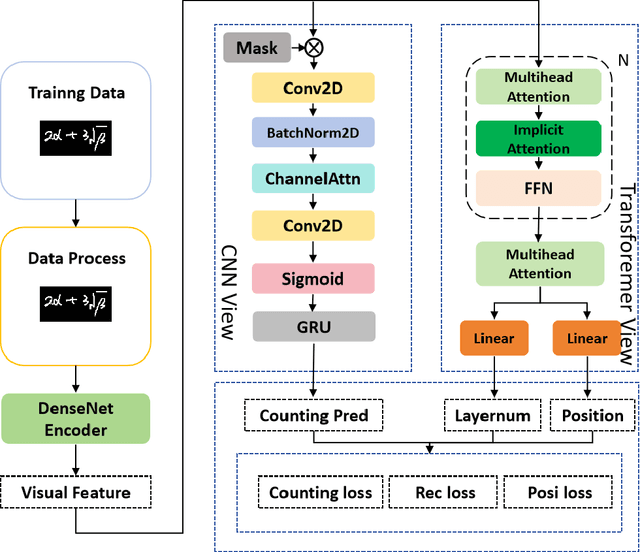

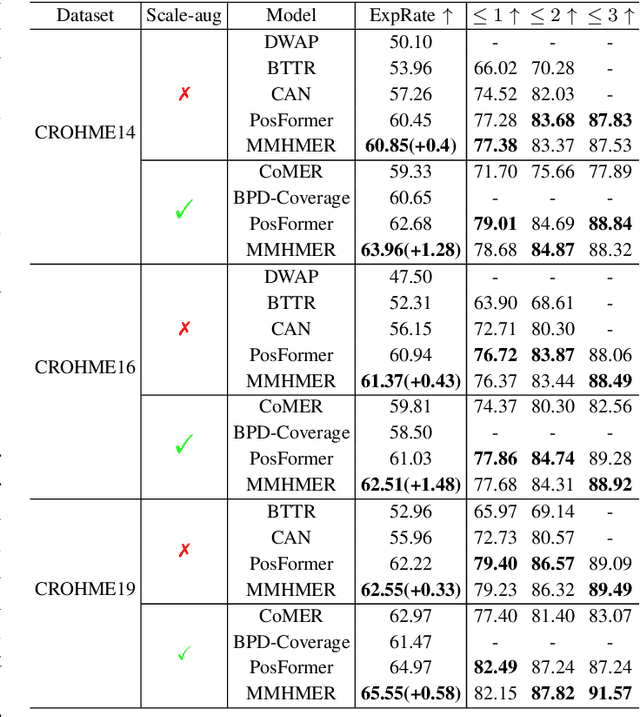
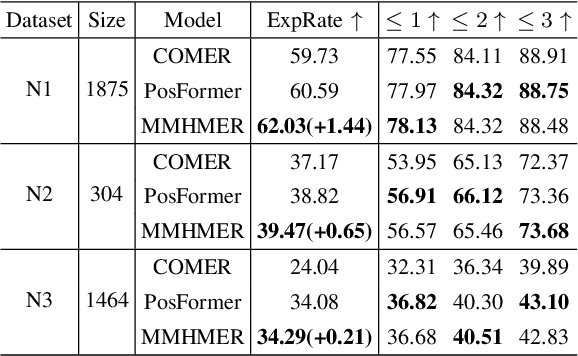
Handwritten Mathematical Expression Recognition (HMER) methods have made remarkable progress, with most existing HMER approaches based on either a hybrid CNN/RNN-based with GRU architecture or Transformer architectures. Each of these has its strengths and weaknesses. Leveraging different model structures as viewers and effectively integrating their diverse capabilities presents an intriguing avenue for exploration. This involves addressing two key challenges: 1) How to fuse these two methods effectively, and 2) How to achieve higher performance under an appropriate level of complexity. This paper proposes an efficient CNN-Transformer multi-viewer, multi-task approach to enhance the model's recognition performance. Our MMHMER model achieves 63.96%, 62.51%, and 65.46% ExpRate on CROHME14, CROHME16, and CROHME19, outperforming Posformer with an absolute gain of 1.28%, 1.48%, and 0.58%. The main contribution of our approach is that we propose a new multi-view, multi-task framework that can effectively integrate the strengths of CNN and Transformer. By leveraging the feature extraction capabilities of CNN and the sequence modeling capabilities of Transformer, our model can better handle the complexity of handwritten mathematical expressions.