 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMMHMER:Multi-viewer and Multi-task for Handwritten Mathematical Expression Recognition
Feb 08, 2025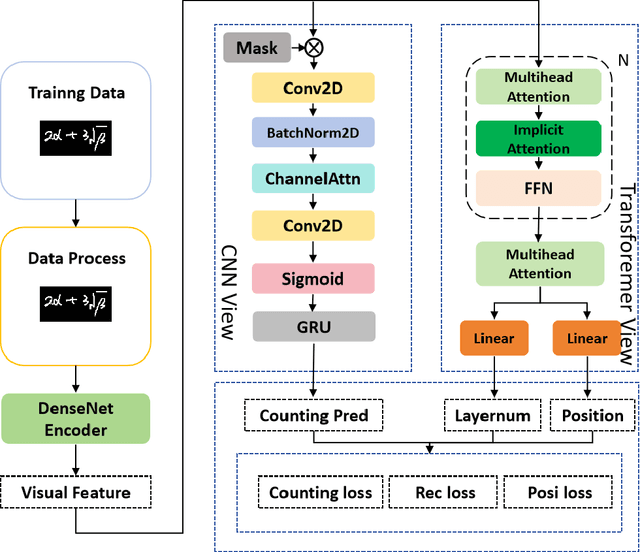

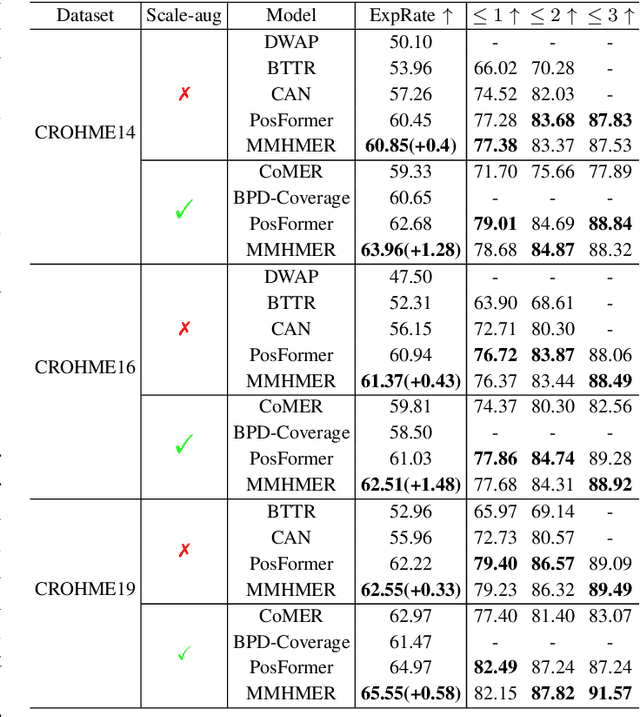
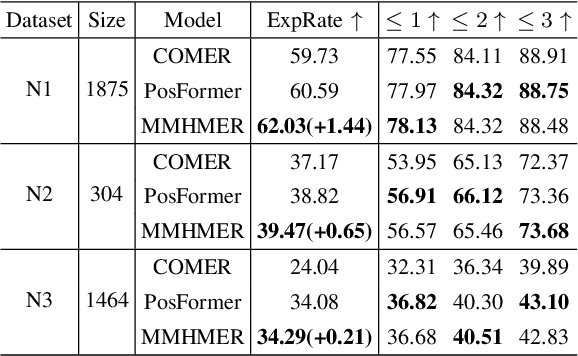
Handwritten Mathematical Expression Recognition (HMER) methods have made remarkable progress, with most existing HMER approaches based on either a hybrid CNN/RNN-based with GRU architecture or Transformer architectures. Each of these has its strengths and weaknesses. Leveraging different model structures as viewers and effectively integrating their diverse capabilities presents an intriguing avenue for exploration. This involves addressing two key challenges: 1) How to fuse these two methods effectively, and 2) How to achieve higher performance under an appropriate level of complexity. This paper proposes an efficient CNN-Transformer multi-viewer, multi-task approach to enhance the model's recognition performance. Our MMHMER model achieves 63.96%, 62.51%, and 65.46% ExpRate on CROHME14, CROHME16, and CROHME19, outperforming Posformer with an absolute gain of 1.28%, 1.48%, and 0.58%. The main contribution of our approach is that we propose a new multi-view, multi-task framework that can effectively integrate the strengths of CNN and Transformer. By leveraging the feature extraction capabilities of CNN and the sequence modeling capabilities of Transformer, our model can better handle the complexity of handwritten mathematical expressions.
Exploring Isolated Musical Notes as Pre-training Data for Predominant Instrument Recognition in Polyphonic Music
Jun 15, 2023With the growing amount of musical data available, automatic instrument recognition, one of the essential problems in Music Information Retrieval (MIR), is drawing more and more attention. While automatic recognition of single instruments has been well-studied, it remains challenging for polyphonic, multi-instrument musical recordings. This work presents our efforts toward building a robust end-to-end instrument recognition system for polyphonic multi-instrument music. We train our model using a pre-training and fine-tuning approach: we use a large amount of monophonic musical data for pre-training and subsequently fine-tune the model for the polyphonic ensemble. In pre-training, we apply data augmentation techniques to alleviate the domain gap between monophonic musical data and real-world music. We evaluate our method on the IRMAS testing data, a polyphonic musical dataset comprising professionally-produced commercial music recordings. Experimental results show that our best model achieves a micro F1-score of 0.674 and an LRAP of 0.814, meaning 10.9% and 8.9% relative improvement compared with the previous state-of-the-art end-to-end approach. Also, we are able to build a lightweight model, achieving competitive performance with only 519K trainable parameters.