 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTAU-R1: Visual Language Model for Traffic Anomaly Understanding
Mar 19, 2026Traffic Anomaly Understanding (TAU) is important for traffic safety in Intelligent Transportation Systems. Recent vision-language models (VLMs) have shown strong capabilities in video understanding. However, progress on TAU remains limited due to the lack of benchmarks and task-specific methodologies. To address this limitation, we introduce Roundabout-TAU, a dataset constructed from real-world roundabout videos collected in collaboration with the City of Carmel, Indiana. The dataset contains 342 clips and is annotated with more than 2,000 question-answer pairs covering multiple aspects of traffic anomaly understanding. Building on this benchmark, we propose TAU-R1, a two-layer vision-language framework for TAU. The first layer is a lightweight anomaly classifier that performs coarse anomaly categorisation, while the second layer is a larger anomaly reasoner that generates detailed event summaries. To improve task-specific reasoning, we introduce a two-stage training strategy consisting of decomposed-QA-enhanced supervised fine-tuning followed by TAU-GRPO, a GRPO-based post-training method with TAU-specific reward functions. Experimental results show that TAU-R1 achieves strong performance on both anomaly classification and reasoning tasks while maintaining deployment efficiency. The dataset and code are available at: https://github.com/siri-rouser/TAU-R1
Shared Spatial Memory Through Predictive Coding
Nov 06, 2025

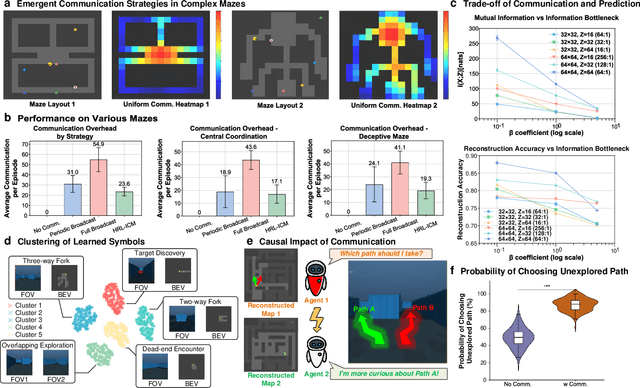
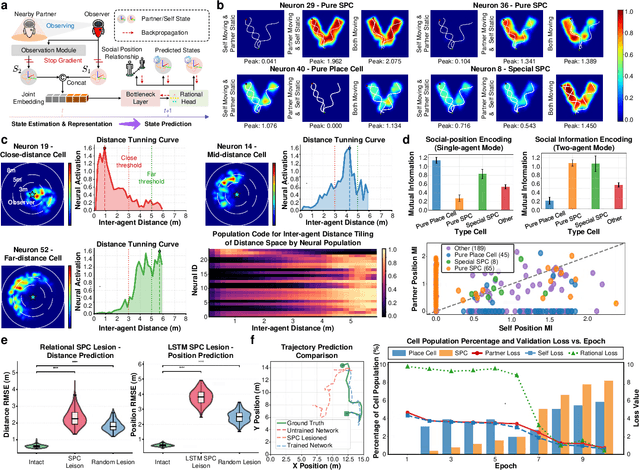
Sharing and reconstructing a consistent spatial memory is a critical challenge in multi-agent systems, where partial observability and limited bandwidth often lead to catastrophic failures in coordination. We introduce a multi-agent predictive coding framework that formulate coordination as the minimization of mutual uncertainty among agents. Instantiated as an information bottleneck objective, it prompts agents to learn not only who and what to communicate but also when. At the foundation of this framework lies a grid-cell-like metric as internal spatial coding for self-localization, emerging spontaneously from self-supervised motion prediction. Building upon this internal spatial code, agents gradually develop a bandwidth-efficient communication mechanism and specialized neural populations that encode partners' locations: an artificial analogue of hippocampal social place cells (SPCs). These social representations are further enacted by a hierarchical reinforcement learning policy that actively explores to reduce joint uncertainty. On the Memory-Maze benchmark, our approach shows exceptional resilience to bandwidth constraints: success degrades gracefully from 73.5% to 64.4% as bandwidth shrinks from 128 to 4 bits/step, whereas a full-broadcast baseline collapses from 67.6% to 28.6%. Our findings establish a theoretically principled and biologically plausible basis for how complex social representations emerge from a unified predictive drive, leading to social collective intelligence.
Diffusion^2: Dual Diffusion Model with Uncertainty-Aware Adaptive Noise for Momentary Trajectory Prediction
Oct 05, 2025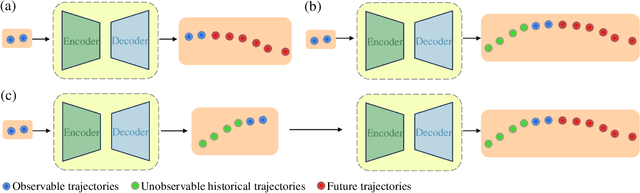
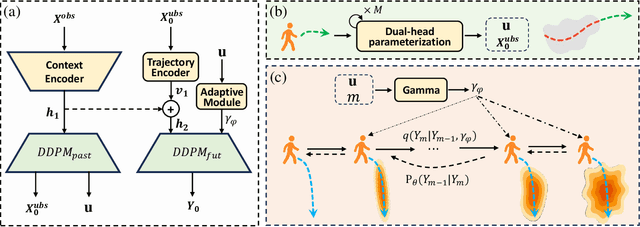
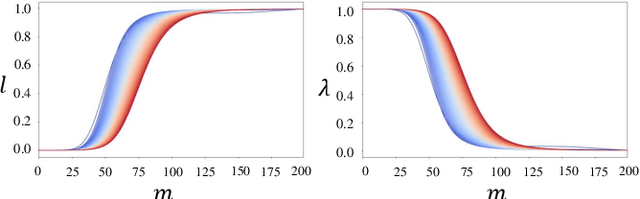
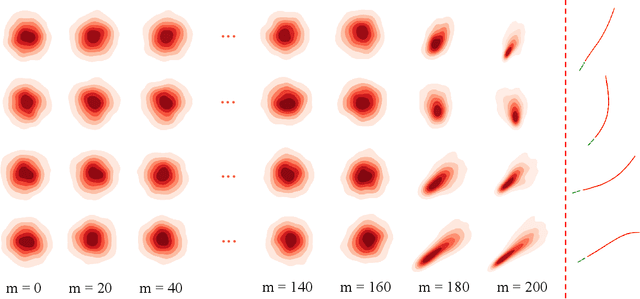
Accurate pedestrian trajectory prediction is crucial for ensuring safety and efficiency in autonomous driving and human-robot interaction scenarios. Earlier studies primarily utilized sufficient observational data to predict future trajectories. However, in real-world scenarios, such as pedestrians suddenly emerging from blind spots, sufficient observational data is often unavailable (i.e. momentary trajectory), making accurate prediction challenging and increasing the risk of traffic accidents. Therefore, advancing research on pedestrian trajectory prediction under extreme scenarios is critical for enhancing traffic safety. In this work, we propose a novel framework termed Diffusion^2, tailored for momentary trajectory prediction. Diffusion^2 consists of two sequentially connected diffusion models: one for backward prediction, which generates unobserved historical trajectories, and the other for forward prediction, which forecasts future trajectories. Given that the generated unobserved historical trajectories may introduce additional noise, we propose a dual-head parameterization mechanism to estimate their aleatoric uncertainty and design a temporally adaptive noise module that dynamically modulates the noise scale in the forward diffusion process. Empirically, Diffusion^2 sets a new state-of-the-art in momentary trajectory prediction on ETH/UCY and Stanford Drone datasets.
Collaborative-Distilled Diffusion Models (CDDM) for Accelerated and Lightweight Trajectory Prediction
Oct 01, 2025Trajectory prediction is a fundamental task in Autonomous Vehicles (AVs) and Intelligent Transportation Systems (ITS), supporting efficient motion planning and real-time traffic safety management. Diffusion models have recently demonstrated strong performance in probabilistic trajectory prediction, but their large model size and slow sampling process hinder real-world deployment. This paper proposes Collaborative-Distilled Diffusion Models (CDDM), a novel method for real-time and lightweight trajectory prediction. Built upon Collaborative Progressive Distillation (CPD), CDDM progressively transfers knowledge from a high-capacity teacher diffusion model to a lightweight student model, jointly reducing both the number of sampling steps and the model size across distillation iterations. A dual-signal regularized distillation loss is further introduced to incorporate guidance from both the teacher and ground-truth data, mitigating potential overfitting and ensuring robust performance. Extensive experiments on the ETH-UCY pedestrian benchmark and the nuScenes vehicle benchmark demonstrate that CDDM achieves state-of-the-art prediction accuracy. The well-distilled CDDM retains 96.2% and 95.5% of the baseline model's ADE and FDE performance on pedestrian trajectories, while requiring only 231K parameters and 4 or 2 sampling steps, corresponding to 161x compression, 31x acceleration, and 9 ms latency. Qualitative results further show that CDDM generates diverse and accurate trajectories under dynamic agent behaviors and complex social interactions. By bridging high-performing generative models with practical deployment constraints, CDDM enables resource-efficient probabilistic prediction for AVs and ITS. Code is available at https://github.com/bingzhangw/CDDM.
Deep Fictitious Play-Based Potential Differential Games for Learning Human-Like Interaction at Unsignalized Intersections
Jun 14, 2025Modeling vehicle interactions at unsignalized intersections is a challenging task due to the complexity of the underlying game-theoretic processes. Although prior studies have attempted to capture interactive driving behaviors, most approaches relied solely on game-theoretic formulations and did not leverage naturalistic driving datasets. In this study, we learn human-like interactive driving policies at unsignalized intersections using Deep Fictitious Play. Specifically, we first model vehicle interactions as a Differential Game, which is then reformulated as a Potential Differential Game. The weights in the cost function are learned from the dataset and capture diverse driving styles. We also demonstrate that our framework provides a theoretical guarantee of convergence to a Nash equilibrium. To the best of our knowledge, this is the first study to train interactive driving policies using Deep Fictitious Play. We validate the effectiveness of our Deep Fictitious Play-Based Potential Differential Game (DFP-PDG) framework using the INTERACTION dataset. The results demonstrate that the proposed framework achieves satisfactory performance in learning human-like driving policies. The learned individual weights effectively capture variations in driver aggressiveness and preferences. Furthermore, the ablation study highlights the importance of each component within our model.
PreMixer: MLP-Based Pre-training Enhanced MLP-Mixers for Large-scale Traffic Forecasting
Dec 18, 2024



In urban computing, precise and swift forecasting of multivariate time series data from traffic networks is crucial. This data incorporates additional spatial contexts such as sensor placements and road network layouts, and exhibits complex temporal patterns that amplify challenges for predictive learning in traffic management, smart mobility demand, and urban planning. Consequently, there is an increasing need to forecast traffic flow across broader geographic regions and for higher temporal coverage. However, current research encounters limitations because of the inherent inefficiency of model and their unsuitability for large-scale traffic network applications due to model complexity. This paper proposes a novel framework, named PreMixer, designed to bridge this gap. It features a predictive model and a pre-training mechanism, both based on the principles of Multi-Layer Perceptrons (MLP). The PreMixer comprehensively consider temporal dependencies of traffic patterns in different time windows and processes the spatial dynamics as well. Additionally, we integrate spatio-temporal positional encoding to manage spatiotemporal heterogeneity without relying on predefined graphs. Furthermore, our innovative pre-training model uses a simple patch-wise MLP to conduct masked time series modeling, learning from long-term historical data segmented into patches to generate enriched contextual representations. This approach enhances the downstream forecasting model without incurring significant time consumption or computational resource demands owing to improved learning efficiency and data handling flexibility. Our framework achieves comparable state-of-the-art performance while maintaining high computational efficiency, as verified by extensive experiments on large-scale traffic datasets.
Artificial Immunofluorescence in a Flash: Rapid Synthetic Imaging from Brightfield Through Residual Diffusion
Jul 25, 2024



Immunofluorescent (IF) imaging is crucial for visualizing biomarker expressions, cell morphology and assessing the effects of drug treatments on sub-cellular components. IF imaging needs extra staining process and often requiring cell fixation, therefore it may also introduce artefects and alter endogenouous cell morphology. Some IF stains are expensive or not readily available hence hindering experiments. Recent diffusion models, which synthesise high-fidelity IF images from easy-to-acquire brightfield (BF) images, offer a promising solution but are hindered by training instability and slow inference times due to the noise diffusion process. This paper presents a novel method for the conditional synthesis of IF images directly from BF images along with cell segmentation masks. Our approach employs a Residual Diffusion process that enhances stability and significantly reduces inference time. We performed a critical evaluation against other image-to-image synthesis models, including UNets, GANs, and advanced diffusion models. Our model demonstrates significant improvements in image quality (p<0.05 in MSE, PSNR, and SSIM), inference speed (26 times faster than competing diffusion models), and accurate segmentation results for both nuclei and cell bodies (0.77 and 0.63 mean IOU for nuclei and cell true positives, respectively). This paper is a substantial advancement in the field, providing robust and efficient tools for cell image analysis.
MSCT: Addressing Time-Varying Confounding with Marginal Structural Causal Transformer for Counterfactual Post-Crash Traffic Prediction
Jul 19, 2024



Traffic crashes profoundly impede traffic efficiency and pose economic challenges. Accurate prediction of post-crash traffic status provides essential information for evaluating traffic perturbations and developing effective solutions. Previous studies have established a series of deep learning models to predict post-crash traffic conditions, however, these correlation-based methods cannot accommodate the biases caused by time-varying confounders and the heterogeneous effects of crashes. The post-crash traffic prediction model needs to estimate the counterfactual traffic speed response to hypothetical crashes under various conditions, which demonstrates the necessity of understanding the causal relationship between traffic factors. Therefore, this paper presents the Marginal Structural Causal Transformer (MSCT), a novel deep learning model designed for counterfactual post-crash traffic prediction. To address the issue of time-varying confounding bias, MSCT incorporates a structure inspired by Marginal Structural Models and introduces a balanced loss function to facilitate learning of invariant causal features. The proposed model is treatment-aware, with a specific focus on comprehending and predicting traffic speed under hypothetical crash intervention strategies. In the absence of ground-truth data, a synthetic data generation procedure is proposed to emulate the causal mechanism between traffic speed, crashes, and covariates. The model is validated using both synthetic and real-world data, demonstrating that MSCT outperforms state-of-the-art models in multi-step-ahead prediction performance. This study also systematically analyzes the impact of time-varying confounding bias and dataset distribution on model performance, contributing valuable insights into counterfactual prediction for intelligent transportation systems.
EditFollower: Tunable Car Following Models for Customizable Adaptive Cruise Control Systems
Jun 23, 2024



In the realm of driving technologies, fully autonomous vehicles have not been widely adopted yet, making advanced driver assistance systems (ADAS) crucial for enhancing driving experiences. Adaptive Cruise Control (ACC) emerges as a pivotal component of ADAS. However, current ACC systems often employ fixed settings, failing to intuitively capture drivers' social preferences and leading to potential function disengagement. To overcome these limitations, we propose the Editable Behavior Generation (EBG) model, a data-driven car-following model that allows for adjusting driving discourtesy levels. The framework integrates diverse courtesy calculation methods into long short-term memory (LSTM) and Transformer architectures, offering a comprehensive approach to capture nuanced driving dynamics. By integrating various discourtesy values during the training process, our model generates realistic agent trajectories with different levels of courtesy in car-following behavior. Experimental results on the HighD and Waymo datasets showcase a reduction in Mean Squared Error (MSE) of spacing and MSE of speed compared to baselines, establishing style controllability. To the best of our knowledge, this work represents the first data-driven car-following model capable of dynamically adjusting discourtesy levels. Our model provides valuable insights for the development of ACC systems that take into account drivers' social preferences.
MetaFollower: Adaptable Personalized Autonomous Car Following
Jun 23, 2024



Car-following (CF) modeling, a fundamental component in microscopic traffic simulation, has attracted increasing interest of researchers in the past decades. In this study, we propose an adaptable personalized car-following framework -MetaFollower, by leveraging the power of meta-learning. Specifically, we first utilize Model-Agnostic Meta-Learning (MAML) to extract common driving knowledge from various CF events. Afterward, the pre-trained model can be fine-tuned on new drivers with only a few CF trajectories to achieve personalized CF adaptation. We additionally combine Long Short-Term Memory (LSTM) and Intelligent Driver Model (IDM) to reflect temporal heterogeneity with high interpretability. Unlike conventional adaptive cruise control (ACC) systems that rely on predefined settings and constant parameters without considering heterogeneous driving characteristics, MetaFollower can accurately capture and simulate the intricate dynamics of car-following behavior while considering the unique driving styles of individual drivers. We demonstrate the versatility and adaptability of MetaFollower by showcasing its ability to adapt to new drivers with limited training data quickly. To evaluate the performance of MetaFollower, we conduct rigorous experiments comparing it with both data-driven and physics-based models. The results reveal that our proposed framework outperforms baseline models in predicting car-following behavior with higher accuracy and safety. To the best of our knowledge, this is the first car-following model aiming to achieve fast adaptation by considering both driver and temporal heterogeneity based on meta-learning.