 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTube-Structured Incremental Semantic HARQ for Generative Video Receivers
May 11, 2026Generative semantic communication uses receiver-side generative priors to reconstruct visual content from compact semantics, making it attractive for bandwidth-limited multimedia delivery. For video, reliable recovery remains difficult because errors accumulate over time, useful evidence is temporally correlated, and the receiver must make decisions under limited interaction, retransmission, and reconstruction budgets. Existing generative semantic communication studies mainly emphasize representation, compression, or generative reconstruction, while recent error-resilient and semantic-HARQ methods still largely operate on encoder-defined or frame-block retransmission units. This paper studies receiver-driven semantic HARQ for generative video reconstruction under a budget-constrained AoIS-AUC objective and argues that the retransmission primitive is itself an important system design variable. We propose tube-structured package-native requests, in which temporally local packages are the channel-visible HARQ objects and are transmitted, dropped, received, and committed at package granularity. Under a controlled comparison protocol with matched backbone, budgets, and channel model, this primitive yields lower time-weighted recovery cost than competitive block-based baselines in practically relevant moderate-to-harsh regimes, while the gap naturally shrinks in near-clean channels. The gain mainly appears as earlier stabilization of the recovery trajectory, while final-quality endpoints remain broadly comparable, and it persists even against a tube-aware block-ranking baseline.
Revisiting the Independence Assumption in LEO Satellite-to-Ground Optical Links: A State-Coupled Joint Fading Model
May 11, 2026Performance analysis of low Earth orbit (LEO) satellite-to-ground optical links relies on composite fading models that typically evaluate scintillation and angular loss under the assumption of statistical independence. While ensuring analytical tractability, this assumption decouples fading mechanisms driven by the same atmospheric turbulence and fails to capture the distinct effects of free atmosphere (FA) and boundary layer (BL) perturbations. To model this coupling while preserving tractability, this paper develops a state-coupled joint fading model. In the proposed framework, aperture-averaged scintillation and effective angular loss are jointly characterized by a discrete slow atmospheric state, parameterized by separate FA and BL scaling factors. By replacing unconditional independence with state-conditioned independence, the model enables a closed-form derivation of the outage probability, preserving the computational simplicity of the independent baseline. Numerical results show that the independent baseline can misestimate outage under non-nominal layered turbulence states. This outage prediction bias varies with elevation because the relative roles of scintillation and angular loss change with the link geometry, resulting in different residual angular correction requirements for a given outage target.
Seeing the Evidence, Missing the Answer: Tool-Guided Vision-Language Models on Visual Illusions
Mar 31, 2026Vision-language models (VLMs) exhibit a systematic bias when confronted with classic optical illusions: they overwhelmingly predict the illusion as "real" regardless of whether the image has been counterfactually modified. We present a tool-guided inference framework for the DataCV 2026 Challenge (Tasks I and II) that addresses this failure mode without any model training. An off-the-shelf vision-language model is given access to a small set of generic image manipulation tools: line drawing, region cropping, side-by-side comparison, and channel isolation, together with an illusion-type-routing system prompt that prescribes which tools to invoke for each perceptual question category. Critically, every tool call produces a new, immutable image resource appended to a persistent registry, so the model can reference and compose any prior annotated view throughout its reasoning chain. Rather than hard-coding illusion-specific modules, this generic-tool-plus-routing design yields strong cross-structural generalization: performance remained consistent from the validation set to a test set containing structurally unfamiliar illusion variants (e.g., Mach Bands rotated from vertical to horizontal stacking). We further report three empirical observations that we believe warrant additional investigation: (i) a strong positive-detection bias likely rooted in imbalanced illusion training data, (ii) a striking dissociation between pixel-accurate spatial reasoning and logical inference over self-generated annotations, and (iii) pronounced sensitivity to image compression artifacts that compounds false positives.
Synthetic Defect Image Generation for Power Line Insulator Inspection Using Multimodal Large Language Models
Mar 09, 2026Utility companies increasingly rely on drone imagery for post-event and routine inspection, but training accurate defect-type classifiers remains difficult because defect examples are rare and inspection datasets are often limited or proprietary. We address this data-scarcity setting by using an off-the-shelf multimodal large language model (MLLM) as a training-free image generator to synthesize defect images from visual references and text prompts. Our pipeline increases diversity via dual-reference conditioning, improves label fidelity with lightweight human verification and prompt refinement, and filters the resulting synthetic pool using an embedding-based selection rule based on distances to class centroids computed from the real training split. We evaluate on ceramic insulator defect-type classification (shell vs. glaze) using a public dataset with a realistic low training-data regime (104 real training images; 152 validation; 308 test). Augmenting the 10% real training set with embedding-selected synthetic images improves test F1 score (harmonic mean of precision and recall) from 0.615 to 0.739 (20% relative), corresponding to an estimated 4--5x data-efficiency gain, and the gains persist with stronger backbone models and frozen-feature linear-probe baselines. These results suggest a practical, low-barrier path for improving defect recognition when collecting additional real defects is slow or infeasible.
Multi-Scale Wavelet Transformers for Operator Learning of Dynamical Systems
Feb 01, 2026Recent years have seen a surge in data-driven surrogates for dynamical systems that can be orders of magnitude faster than numerical solvers. However, many machine learning-based models such as neural operators exhibit spectral bias, attenuating high-frequency components that often encode small-scale structure. This limitation is particularly damaging in applications such as weather forecasting, where misrepresented high frequencies can induce long-horizon instability. To address this issue, we propose multi-scale wavelet transformers (MSWTs), which learn system dynamics in a tokenized wavelet domain. The wavelet transform explicitly separates low- and high-frequency content across scales. MSWTs leverage a wavelet-preserving downsampling scheme that retains high-frequency features and employ wavelet-based attention to capture dependencies across scales and frequency bands. Experiments on chaotic dynamical systems show substantial error reductions and improved long horizon spectral fidelity. On the ERA5 climate reanalysis, MSWTs further reduce climatological bias, demonstrating their effectiveness in a real-world forecasting setting.
Characteristics Analysis of Autonomous Vehicle Pre-crash Scenarios
Feb 28, 2025



To date, hundreds of crashes have occurred in open road testing of automated vehicles (AVs), highlighting the need for improving AV reliability and safety. Pre-crash scenario typology classifies crashes based on vehicle dynamics and kinematics features. Building on this, characteristics analysis can identify similar features under comparable crashes, offering a more effective reflection of general crash patterns and providing more targeted recommendations for enhancing AV performance. However, current studies primarily concentrated on crashes among conventional human-driven vehicles, leaving a gap in research dedicated to in-depth AV crash analyses. In this paper, we analyzed the latest California AV collision reports and used the newly revised pre-crash scenario typology to identify pre-crash scenarios. We proposed a set of mapping rules for automatically extracting these AV pre-crash scenarios, successfully identifying 24 types with a 98.1% accuracy rate, and obtaining two key scenarios of AV crashes (i.e., rear-end scenarios and intersection scenarios) through detailed analysis. Association analyses of rear-end scenarios showed that the significant environmental influencing factors were traffic control type, location type, light, etc. For intersection scenarios prone to severe crashes with detailed descriptions, we employed causal analyses to obtain the significant causal factors: habitual violations and expectations of certain behavior. Optimization recommendations were then formulated, addressing both governmental oversight and AV manufacturers' potential improvements. The findings of this paper could guide government authorities to develop related regulations, help manufacturers design AV test scenarios, and identify potential shortcomings in control algorithms specific to various real-world scenarios, thereby optimizing AV systems effectively.
Pre-Trained Large Language Model Based Remaining Useful Life Transfer Prediction of Bearing
Jan 13, 2025



Accurately predicting the remaining useful life (RUL) of rotating machinery, such as bearings, is essential for ensuring equipment reliability and minimizing unexpected industrial failures. Traditional data-driven deep learning methods face challenges in practical settings due to inconsistent training and testing data distributions and limited generalization for long-term predictions.
Deep Learning-Based Electricity Price Forecast for Virtual Bidding in Wholesale Electricity Market
Nov 25, 2024



Virtual bidding plays an important role in two-settlement electric power markets, as it can reduce discrepancies between day-ahead and real-time markets. Renewable energy penetration increases volatility in electricity prices, making accurate forecasting critical for virtual bidders, reducing uncertainty and maximizing profits. This study presents a Transformer-based deep learning model to forecast the price spread between real-time and day-ahead electricity prices in the ERCOT (Electric Reliability Council of Texas) market. The proposed model leverages various time-series features, including load forecasts, solar and wind generation forecasts, and temporal attributes. The model is trained under realistic constraints and validated using a walk-forward approach by updating the model every week. Based on the price spread prediction results, several trading strategies are proposed and the most effective strategy for maximizing cumulative profit under realistic market conditions is identified through backtesting. The results show that the strategy of trading only at the peak hour with a precision score of over 50% produces nearly consistent profit over the test period. The proposed method underscores the importance of an accurate electricity price forecasting model and introduces a new method of evaluating the price forecast model from a virtual bidder's perspective, providing valuable insights for future research.
MetaFollower: Adaptable Personalized Autonomous Car Following
Jun 23, 2024



Car-following (CF) modeling, a fundamental component in microscopic traffic simulation, has attracted increasing interest of researchers in the past decades. In this study, we propose an adaptable personalized car-following framework -MetaFollower, by leveraging the power of meta-learning. Specifically, we first utilize Model-Agnostic Meta-Learning (MAML) to extract common driving knowledge from various CF events. Afterward, the pre-trained model can be fine-tuned on new drivers with only a few CF trajectories to achieve personalized CF adaptation. We additionally combine Long Short-Term Memory (LSTM) and Intelligent Driver Model (IDM) to reflect temporal heterogeneity with high interpretability. Unlike conventional adaptive cruise control (ACC) systems that rely on predefined settings and constant parameters without considering heterogeneous driving characteristics, MetaFollower can accurately capture and simulate the intricate dynamics of car-following behavior while considering the unique driving styles of individual drivers. We demonstrate the versatility and adaptability of MetaFollower by showcasing its ability to adapt to new drivers with limited training data quickly. To evaluate the performance of MetaFollower, we conduct rigorous experiments comparing it with both data-driven and physics-based models. The results reveal that our proposed framework outperforms baseline models in predicting car-following behavior with higher accuracy and safety. To the best of our knowledge, this is the first car-following model aiming to achieve fast adaptation by considering both driver and temporal heterogeneity based on meta-learning.
Video Frame Interpolation for Polarization via Swin-Transformer
Jun 17, 2024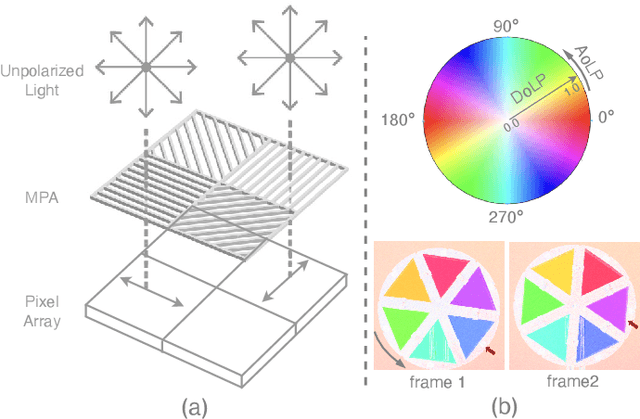
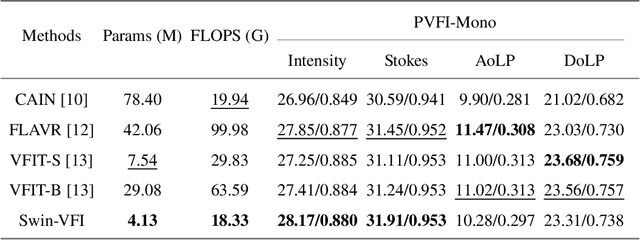
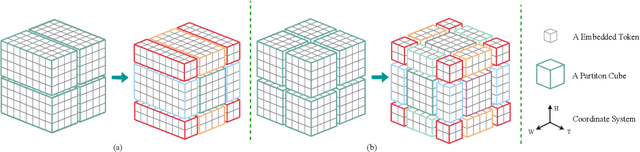
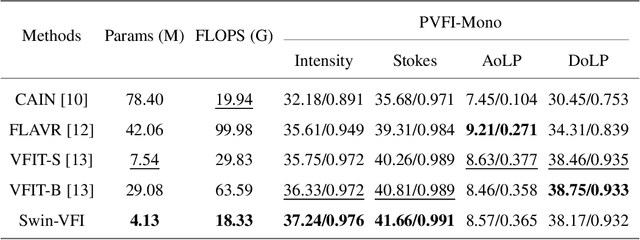
Video Frame Interpolation (VFI) has been extensively explored and demonstrated, yet its application to polarization remains largely unexplored. Due to the selective transmission of light by polarized filters, longer exposure times are typically required to ensure sufficient light intensity, which consequently lower the temporal sample rates. Furthermore, because polarization reflected by objects varies with shooting perspective, focusing solely on estimating pixel displacement is insufficient to accurately reconstruct the intermediate polarization. To tackle these challenges, this study proposes a multi-stage and multi-scale network called Swin-VFI based on the Swin-Transformer and introduces a tailored loss function to facilitate the network's understanding of polarization changes. To ensure the practicality of our proposed method, this study evaluates its interpolated frames in Shape from Polarization (SfP) and Human Shape Reconstruction tasks, comparing them with other state-of-the-art methods such as CAIN, FLAVR, and VFIT. Experimental results demonstrate our approach's superior reconstruction accuracy across all tasks.