 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAIR-VLA: Vision-Language-Action Systems for Aerial Manipulation
Jan 29, 2026While Vision-Language-Action (VLA) models have achieved remarkable success in ground-based embodied intelligence, their application to Aerial Manipulation Systems (AMS) remains a largely unexplored frontier. The inherent characteristics of AMS, including floating-base dynamics, strong coupling between the UAV and the manipulator, and the multi-step, long-horizon nature of operational tasks, pose severe challenges to existing VLA paradigms designed for static or 2D mobile bases. To bridge this gap, we propose AIR-VLA, the first VLA benchmark specifically tailored for aerial manipulation. We construct a physics-based simulation environment and release a high-quality multimodal dataset comprising 3000 manually teleoperated demonstrations, covering base manipulation, object & spatial understanding, semantic reasoning, and long-horizon planning. Leveraging this platform, we systematically evaluate mainstream VLA models and state-of-the-art VLM models. Our experiments not only validate the feasibility of transferring VLA paradigms to aerial systems but also, through multi-dimensional metrics tailored to aerial tasks, reveal the capabilities and boundaries of current models regarding UAV mobility, manipulator control, and high-level planning. AIR-VLA establishes a standardized testbed and data foundation for future research in general-purpose aerial robotics. The resource of AIR-VLA will be available at https://anonymous.4open.science/r/AIR-VLA-dataset-B5CC/.
CogRail: Benchmarking VLMs in Cognitive Intrusion Perception for Intelligent Railway Transportation Systems
Jan 14, 2026Accurate and early perception of potential intrusion targets is essential for ensuring the safety of railway transportation systems. However, most existing systems focus narrowly on object classification within fixed visual scopes and apply rule-based heuristics to determine intrusion status, often overlooking targets that pose latent intrusion risks. Anticipating such risks requires the cognition of spatial context and temporal dynamics for the object of interest (OOI), which presents challenges for conventional visual models. To facilitate deep intrusion perception, we introduce a novel benchmark, CogRail, which integrates curated open-source datasets with cognitively driven question-answer annotations to support spatio-temporal reasoning and prediction. Building upon this benchmark, we conduct a systematic evaluation of state-of-the-art visual-language models (VLMs) using multimodal prompts to identify their strengths and limitations in this domain. Furthermore, we fine-tune VLMs for better performance and propose a joint fine-tuning framework that integrates three core tasks, position perception, movement prediction, and threat analysis, facilitating effective adaptation of general-purpose foundation models into specialized models tailored for cognitive intrusion perception. Extensive experiments reveal that current large-scale multimodal models struggle with the complex spatial-temporal reasoning required by the cognitive intrusion perception task, underscoring the limitations of existing foundation models in this safety-critical domain. In contrast, our proposed joint fine-tuning framework significantly enhances model performance by enabling targeted adaptation to domain-specific reasoning demands, highlighting the advantages of structured multi-task learning in improving both accuracy and interpretability. Code will be available at https://github.com/Hub-Tian/CogRail.
AMap: Distilling Future Priors for Ahead-Aware Online HD Map Construction
Dec 22, 2025



Online High-Definition (HD) map construction is pivotal for autonomous driving. While recent approaches leverage historical temporal fusion to improve performance, we identify a critical safety flaw in this paradigm: it is inherently ``spatially backward-looking." These methods predominantly enhance map reconstruction in traversed areas, offering minimal improvement for the unseen road ahead. Crucially, our analysis of downstream planning tasks reveals a severe asymmetry: while rearward perception errors are often tolerable, inaccuracies in the forward region directly precipitate hazardous driving maneuvers. To bridge this safety gap, we propose AMap, a novel framework for Ahead-aware online HD Mapping. We pioneer a ``distill-from-future" paradigm, where a teacher model with privileged access to future temporal contexts guides a lightweight student model restricted to the current frame. This process implicitly compresses prospective knowledge into the student model, endowing it with ``look-ahead" capabilities at zero inference-time cost. Technically, we introduce a Multi-Level BEV Distillation strategy with spatial masking and an Asymmetric Query Adaptation module to effectively transfer future-aware representations to the student's static queries. Extensive experiments on the nuScenes and Argoverse 2 benchmark demonstrate that AMap significantly enhances current-frame perception. Most notably, it outperforms state-of-the-art temporal models in critical forward regions while maintaining the efficiency of single current frame inference.
Reusing Attention for One-stage Lane Topology Understanding
Jul 23, 2025Understanding lane toplogy relationships accurately is critical for safe autonomous driving. However, existing two-stage methods suffer from inefficiencies due to error propagations and increased computational overheads. To address these challenges, we propose a one-stage architecture that simultaneously predicts traffic elements, lane centerlines and topology relationship, improving both the accuracy and inference speed of lane topology understanding for autonomous driving. Our key innovation lies in reusing intermediate attention resources within distinct transformer decoders. This approach effectively leverages the inherent relational knowledge within the element detection module to enable the modeling of topology relationships among traffic elements and lanes without requiring additional computationally expensive graph networks. Furthermore, we are the first to demonstrate that knowledge can be distilled from models that utilize standard definition (SD) maps to those operates without using SD maps, enabling superior performance even in the absence of SD maps. Extensive experiments on the OpenLane-V2 dataset show that our approach outperforms baseline methods in both accuracy and efficiency, achieving superior results in lane detection, traffic element identification, and topology reasoning. Our code is available at https://github.com/Yang-Li-2000/one-stage.git.
SAH-Drive: A Scenario-Aware Hybrid Planner for Closed-Loop Vehicle Trajectory Generation
May 30, 2025Reliable planning is crucial for achieving autonomous driving. Rule-based planners are efficient but lack generalization, while learning-based planners excel in generalization yet have limitations in real-time performance and interpretability. In long-tail scenarios, these challenges make planning particularly difficult. To leverage the strengths of both rule-based and learning-based planners, we proposed the Scenario-Aware Hybrid Planner (SAH-Drive) for closed-loop vehicle trajectory planning. Inspired by human driving behavior, SAH-Drive combines a lightweight rule-based planner and a comprehensive learning-based planner, utilizing a dual-timescale decision neuron to determine the final trajectory. To enhance the computational efficiency and robustness of the hybrid planner, we also employed a diffusion proposal number regulator and a trajectory fusion module. The experimental results show that the proposed method significantly improves the generalization capability of the planning system, achieving state-of-the-art performance in interPlan, while maintaining computational efficiency without incurring substantial additional runtime.
Text2Scenario: Text-Driven Scenario Generation for Autonomous Driving Test
Mar 04, 2025Autonomous driving (AD) testing constitutes a critical methodology for assessing performance benchmarks prior to product deployment. The creation of segmented scenarios within a simulated environment is acknowledged as a robust and effective strategy; however, the process of tailoring these scenarios often necessitates laborious and time-consuming manual efforts, thereby hindering the development and implementation of AD technologies. In response to this challenge, we introduce Text2Scenario, a framework that leverages a Large Language Model (LLM) to autonomously generate simulation test scenarios that closely align with user specifications, derived from their natural language inputs. Specifically, an LLM, equipped with a meticulously engineered input prompt scheme functions as a text parser for test scenario descriptions, extracting from a hierarchically organized scenario repository the components that most accurately reflect the user's preferences. Subsequently, by exploiting the precedence of scenario components, the process involves sequentially matching and linking scenario representations within a Domain Specific Language corpus, ultimately fabricating executable test scenarios. The experimental results demonstrate that such prompt engineering can meticulously extract the nuanced details of scenario elements embedded within various descriptive formats, with the majority of generated scenarios aligning closely with the user's initial expectations, allowing for the efficient and precise evaluation of diverse AD stacks void of the labor-intensive need for manual scenario configuration. Project page: https://caixxuan.github.io/Text2Scenario.GitHub.io.
PreMixer: MLP-Based Pre-training Enhanced MLP-Mixers for Large-scale Traffic Forecasting
Dec 18, 2024



In urban computing, precise and swift forecasting of multivariate time series data from traffic networks is crucial. This data incorporates additional spatial contexts such as sensor placements and road network layouts, and exhibits complex temporal patterns that amplify challenges for predictive learning in traffic management, smart mobility demand, and urban planning. Consequently, there is an increasing need to forecast traffic flow across broader geographic regions and for higher temporal coverage. However, current research encounters limitations because of the inherent inefficiency of model and their unsuitability for large-scale traffic network applications due to model complexity. This paper proposes a novel framework, named PreMixer, designed to bridge this gap. It features a predictive model and a pre-training mechanism, both based on the principles of Multi-Layer Perceptrons (MLP). The PreMixer comprehensively consider temporal dependencies of traffic patterns in different time windows and processes the spatial dynamics as well. Additionally, we integrate spatio-temporal positional encoding to manage spatiotemporal heterogeneity without relying on predefined graphs. Furthermore, our innovative pre-training model uses a simple patch-wise MLP to conduct masked time series modeling, learning from long-term historical data segmented into patches to generate enriched contextual representations. This approach enhances the downstream forecasting model without incurring significant time consumption or computational resource demands owing to improved learning efficiency and data handling flexibility. Our framework achieves comparable state-of-the-art performance while maintaining high computational efficiency, as verified by extensive experiments on large-scale traffic datasets.
NEST: A Neuromodulated Small-world Hypergraph Trajectory Prediction Model for Autonomous Driving
Dec 16, 2024Accurate trajectory prediction is essential for the safety and efficiency of autonomous driving. Traditional models often struggle with real-time processing, capturing non-linearity and uncertainty in traffic environments, efficiency in dense traffic, and modeling temporal dynamics of interactions. We introduce NEST (Neuromodulated Small-world Hypergraph Trajectory Prediction), a novel framework that integrates Small-world Networks and hypergraphs for superior interaction modeling and prediction accuracy. This integration enables the capture of both local and extended vehicle interactions, while the Neuromodulator component adapts dynamically to changing traffic conditions. We validate the NEST model on several real-world datasets, including nuScenes, MoCAD, and HighD. The results consistently demonstrate that NEST outperforms existing methods in various traffic scenarios, showcasing its exceptional generalization capability, efficiency, and temporal foresight. Our comprehensive evaluation illustrates that NEST significantly improves the reliability and operational efficiency of autonomous driving systems, making it a robust solution for trajectory prediction in complex traffic environments.
Stag-1: Towards Realistic 4D Driving Simulation with Video Generation Model
Dec 06, 2024



4D driving simulation is essential for developing realistic autonomous driving simulators. Despite advancements in existing methods for generating driving scenes, significant challenges remain in view transformation and spatial-temporal dynamic modeling. To address these limitations, we propose a Spatial-Temporal simulAtion for drivinG (Stag-1) model to reconstruct real-world scenes and design a controllable generative network to achieve 4D simulation. Stag-1 constructs continuous 4D point cloud scenes using surround-view data from autonomous vehicles. It decouples spatial-temporal relationships and produces coherent keyframe videos. Additionally, Stag-1 leverages video generation models to obtain photo-realistic and controllable 4D driving simulation videos from any perspective. To expand the range of view generation, we train vehicle motion videos based on decomposed camera poses, enhancing modeling capabilities for distant scenes. Furthermore, we reconstruct vehicle camera trajectories to integrate 3D points across consecutive views, enabling comprehensive scene understanding along the temporal dimension. Following extensive multi-level scene training, Stag-1 can simulate from any desired viewpoint and achieve a deep understanding of scene evolution under static spatial-temporal conditions. Compared to existing methods, our approach shows promising performance in multi-view scene consistency, background coherence, and accuracy, and contributes to the ongoing advancements in realistic autonomous driving simulation. Code: https://github.com/wzzheng/Stag.
Real-time Accident Anticipation for Autonomous Driving Through Monocular Depth-Enhanced 3D Modeling
Sep 02, 2024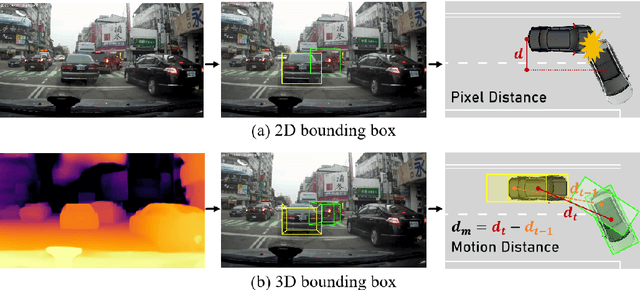
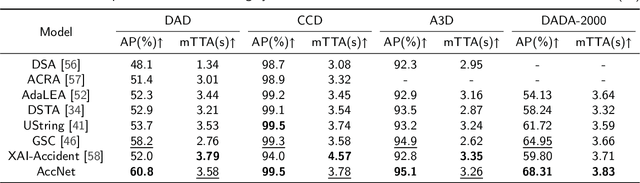
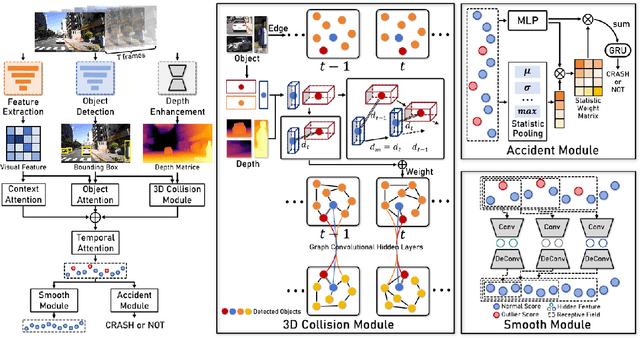
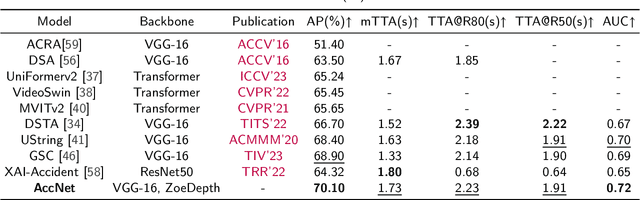
The primary goal of traffic accident anticipation is to foresee potential accidents in real time using dashcam videos, a task that is pivotal for enhancing the safety and reliability of autonomous driving technologies. In this study, we introduce an innovative framework, AccNet, which significantly advances the prediction capabilities beyond the current state-of-the-art (SOTA) 2D-based methods by incorporating monocular depth cues for sophisticated 3D scene modeling. Addressing the prevalent challenge of skewed data distribution in traffic accident datasets, we propose the Binary Adaptive Loss for Early Anticipation (BA-LEA). This novel loss function, together with a multi-task learning strategy, shifts the focus of the predictive model towards the critical moments preceding an accident. {We rigorously evaluate the performance of our framework on three benchmark datasets--Dashcam Accident Dataset (DAD), Car Crash Dataset (CCD), and AnAn Accident Detection (A3D), and DADA-2000 Dataset--demonstrating its superior predictive accuracy through key metrics such as Average Precision (AP) and mean Time-To-Accident (mTTA).