 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoosting Overlapping Organoid Instance Segmentation Using Pseudo-Label Unmixing and Synthesis-Assisted Learning
Jan 10, 2026Organoids, sophisticated in vitro models of human tissues, are crucial for medical research due to their ability to simulate organ functions and assess drug responses accurately. Accurate organoid instance segmentation is critical for quantifying their dynamic behaviors, yet remains profoundly limited by high-quality annotated datasets and pervasive overlap in microscopy imaging. While semi-supervised learning (SSL) offers a solution to alleviate reliance on scarce labeled data, conventional SSL frameworks suffer from biases induced by noisy pseudo-labels, particularly in overlapping regions. Synthesis-assisted SSL (SA-SSL) has been proposed for mitigating training biases in semi-supervised semantic segmentation. We present the first adaptation of SA-SSL to organoid instance segmentation and reveal that SA-SSL struggles to disentangle intertwined organoids, often misrepresenting overlapping instances as a single entity. To overcome this, we propose Pseudo-Label Unmixing (PLU), which identifies erroneous pseudo-labels for overlapping instances and then regenerates organoid labels through instance decomposition. For image synthesis, we apply a contour-based approach to synthesize organoid instances efficiently, particularly for overlapping cases. Instance-level augmentations (IA) on pseudo-labels before image synthesis further enhances the effect of synthetic data (SD). Rigorous experiments on two organoid datasets demonstrate our method's effectiveness, achieving performance comparable to fully supervised models using only 10% labeled data, and state-of-the-art results. Ablation studies validate the contributions of PLU, contour-based synthesis, and augmentation-aware training. By addressing overlap at both pseudo-label and synthesis levels, our work advances scalable, label-efficient organoid analysis, unlocking new potential for high-throughput applications in precision medicine.
QSMnet-INR: Single-Orientation Quantitative Susceptibility Mapping via Implicit Neural Representation in k-Space
Dec 10, 2025Quantitative Susceptibility Mapping (QSM) quantifies tissue magnetic susceptibility from magnetic-resonance phase data and plays a crucial role in brain microstructure imaging, iron-deposition assessment, and neurological-disease research. However, single-orientation QSM inversion remains highly ill-posed because the dipole kernel exhibits a cone-null region in the Fourier domain, leading to streaking artifacts and structural loss. To overcome this limitation, we propose QSMnet-INR, a deep, physics-informed framework that integrates an Implicit Neural Representation (INR) into the k-space domain. The INR module continuously models multi-directional dipole responses and explicitly completes the cone-null region, while a frequency-domain residual-weighted Dipole Loss enforces physical consistency. The overall network combines a 3D U-Net-based QSMnet backbone with the INR module through alternating optimization for end-to-end joint training. Experiments on the 2016 QSM Reconstruction Challenge, a multi-orientation GRE dataset, and both in-house and public single-orientation clinical data demonstrate that QSMnet-INR consistently outperforms conventional and recent deep-learning approaches across multiple quantitative metrics. The proposed framework shows notable advantages in structural recovery within cone-null regions and in artifact suppression. Ablation studies further confirm the complementary contributions of the INR module and Dipole Loss to detail preservation and physical stability. Overall, QSMnet-INR effectively alleviates the ill-posedness of single-orientation QSM without requiring multi-orientation acquisition, achieving high accuracy, robustness, and strong cross-scenario generalization-highlighting its potential for clinical translation.
Text2Scenario: Text-Driven Scenario Generation for Autonomous Driving Test
Mar 04, 2025Autonomous driving (AD) testing constitutes a critical methodology for assessing performance benchmarks prior to product deployment. The creation of segmented scenarios within a simulated environment is acknowledged as a robust and effective strategy; however, the process of tailoring these scenarios often necessitates laborious and time-consuming manual efforts, thereby hindering the development and implementation of AD technologies. In response to this challenge, we introduce Text2Scenario, a framework that leverages a Large Language Model (LLM) to autonomously generate simulation test scenarios that closely align with user specifications, derived from their natural language inputs. Specifically, an LLM, equipped with a meticulously engineered input prompt scheme functions as a text parser for test scenario descriptions, extracting from a hierarchically organized scenario repository the components that most accurately reflect the user's preferences. Subsequently, by exploiting the precedence of scenario components, the process involves sequentially matching and linking scenario representations within a Domain Specific Language corpus, ultimately fabricating executable test scenarios. The experimental results demonstrate that such prompt engineering can meticulously extract the nuanced details of scenario elements embedded within various descriptive formats, with the majority of generated scenarios aligning closely with the user's initial expectations, allowing for the efficient and precise evaluation of diverse AD stacks void of the labor-intensive need for manual scenario configuration. Project page: https://caixxuan.github.io/Text2Scenario.GitHub.io.
KoMA: Knowledge-driven Multi-agent Framework for Autonomous Driving with Large Language Models
Jul 19, 2024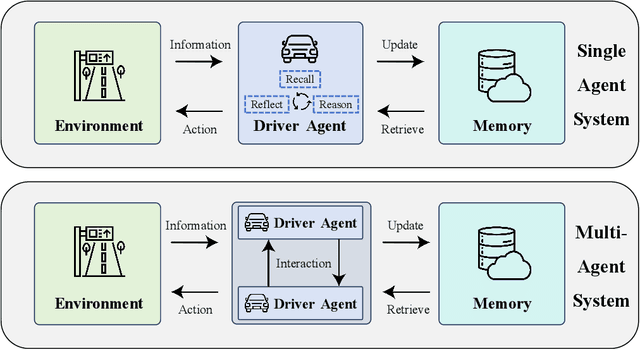
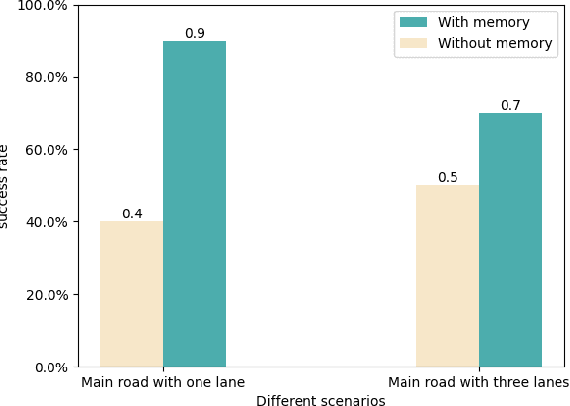
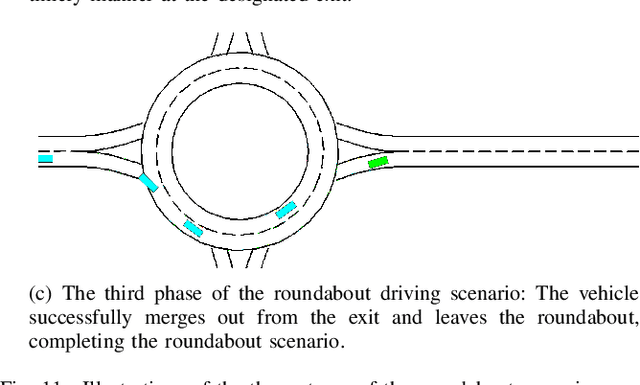
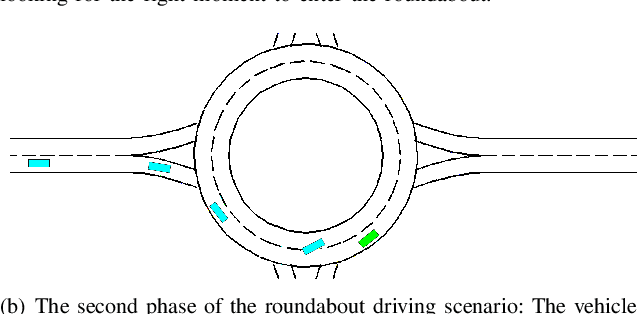
Large language models (LLMs) as autonomous agents offer a novel avenue for tackling real-world challenges through a knowledge-driven manner. These LLM-enhanced methodologies excel in generalization and interpretability. However, the complexity of driving tasks often necessitates the collaboration of multiple, heterogeneous agents, underscoring the need for such LLM-driven agents to engage in cooperative knowledge sharing and cognitive synergy. Despite the promise of LLMs, current applications predominantly center around single agent scenarios. To broaden the horizons of knowledge-driven strategies and bolster the generalization capabilities of autonomous agents, we propose the KoMA framework consisting of multi-agent interaction, multi-step planning, shared-memory, and ranking-based reflection modules to enhance multi-agents' decision-making in complex driving scenarios. Based on the framework's generated text descriptions of driving scenarios, the multi-agent interaction module enables LLM agents to analyze and infer the intentions of surrounding vehicles, akin to human cognition. The multi-step planning module enables LLM agents to analyze and obtain final action decisions layer by layer to ensure consistent goals for short-term action decisions. The shared memory module can accumulate collective experience to make superior decisions, and the ranking-based reflection module can evaluate and improve agent behavior with the aim of enhancing driving safety and efficiency. The KoMA framework not only enhances the robustness and adaptability of autonomous driving agents but also significantly elevates their generalization capabilities across diverse scenarios. Empirical results demonstrate the superiority of our approach over traditional methods, particularly in its ability to handle complex, unpredictable driving environments without extensive retraining.