 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvReal: Adversarial Patch Generation Framework with Application to Adversarial Safety Evaluation of Object Detection Systems
May 22, 2025
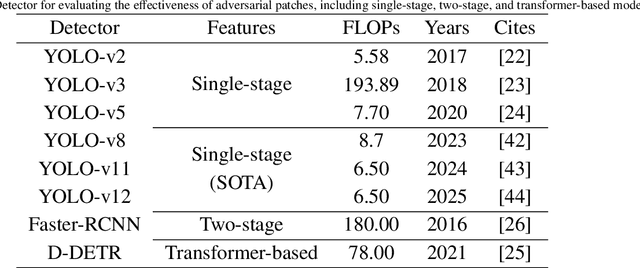
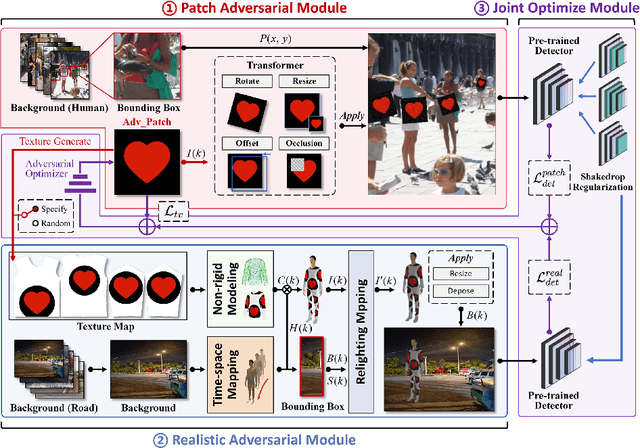

Autonomous vehicles are typical complex intelligent systems with artificial intelligence at their core. However, perception methods based on deep learning are extremely vulnerable to adversarial samples, resulting in safety accidents. How to generate effective adversarial examples in the physical world and evaluate object detection systems is a huge challenge. In this study, we propose a unified joint adversarial training framework for both 2D and 3D samples to address the challenges of intra-class diversity and environmental variations in real-world scenarios. Building upon this framework, we introduce an adversarial sample reality enhancement approach that incorporates non-rigid surface modeling and a realistic 3D matching mechanism. We compare with 5 advanced adversarial patches and evaluate their attack performance on 8 object detecotrs, including single-stage, two-stage, and transformer-based models. Extensive experiment results in digital and physical environments demonstrate that the adversarial textures generated by our method can effectively mislead the target detection model. Moreover, proposed method demonstrates excellent robustness and transferability under multi-angle attacks, varying lighting conditions, and different distance in the physical world. The demo video and code can be obtained at https://github.com/Huangyh98/AdvReal.git.
Text2Scenario: Text-Driven Scenario Generation for Autonomous Driving Test
Mar 04, 2025Autonomous driving (AD) testing constitutes a critical methodology for assessing performance benchmarks prior to product deployment. The creation of segmented scenarios within a simulated environment is acknowledged as a robust and effective strategy; however, the process of tailoring these scenarios often necessitates laborious and time-consuming manual efforts, thereby hindering the development and implementation of AD technologies. In response to this challenge, we introduce Text2Scenario, a framework that leverages a Large Language Model (LLM) to autonomously generate simulation test scenarios that closely align with user specifications, derived from their natural language inputs. Specifically, an LLM, equipped with a meticulously engineered input prompt scheme functions as a text parser for test scenario descriptions, extracting from a hierarchically organized scenario repository the components that most accurately reflect the user's preferences. Subsequently, by exploiting the precedence of scenario components, the process involves sequentially matching and linking scenario representations within a Domain Specific Language corpus, ultimately fabricating executable test scenarios. The experimental results demonstrate that such prompt engineering can meticulously extract the nuanced details of scenario elements embedded within various descriptive formats, with the majority of generated scenarios aligning closely with the user's initial expectations, allowing for the efficient and precise evaluation of diverse AD stacks void of the labor-intensive need for manual scenario configuration. Project page: https://caixxuan.github.io/Text2Scenario.GitHub.io.
AutoAttacker: A Large Language Model Guided System to Implement Automatic Cyber-attacks
Mar 02, 2024Large language models (LLMs) have demonstrated impressive results on natural language tasks, and security researchers are beginning to employ them in both offensive and defensive systems. In cyber-security, there have been multiple research efforts that utilize LLMs focusing on the pre-breach stage of attacks like phishing and malware generation. However, so far there lacks a comprehensive study regarding whether LLM-based systems can be leveraged to simulate the post-breach stage of attacks that are typically human-operated, or "hands-on-keyboard" attacks, under various attack techniques and environments. As LLMs inevitably advance, they may be able to automate both the pre- and post-breach attack stages. This shift may transform organizational attacks from rare, expert-led events to frequent, automated operations requiring no expertise and executed at automation speed and scale. This risks fundamentally changing global computer security and correspondingly causing substantial economic impacts, and a goal of this work is to better understand these risks now so we can better prepare for these inevitable ever-more-capable LLMs on the horizon. On the immediate impact side, this research serves three purposes. First, an automated LLM-based, post-breach exploitation framework can help analysts quickly test and continually improve their organization's network security posture against previously unseen attacks. Second, an LLM-based penetration test system can extend the effectiveness of red teams with a limited number of human analysts. Finally, this research can help defensive systems and teams learn to detect novel attack behaviors preemptively before their use in the wild....