 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoAttacker: A Large Language Model Guided System to Implement Automatic Cyber-attacks
Mar 02, 2024



Large language models (LLMs) have demonstrated impressive results on natural language tasks, and security researchers are beginning to employ them in both offensive and defensive systems. In cyber-security, there have been multiple research efforts that utilize LLMs focusing on the pre-breach stage of attacks like phishing and malware generation. However, so far there lacks a comprehensive study regarding whether LLM-based systems can be leveraged to simulate the post-breach stage of attacks that are typically human-operated, or "hands-on-keyboard" attacks, under various attack techniques and environments. As LLMs inevitably advance, they may be able to automate both the pre- and post-breach attack stages. This shift may transform organizational attacks from rare, expert-led events to frequent, automated operations requiring no expertise and executed at automation speed and scale. This risks fundamentally changing global computer security and correspondingly causing substantial economic impacts, and a goal of this work is to better understand these risks now so we can better prepare for these inevitable ever-more-capable LLMs on the horizon. On the immediate impact side, this research serves three purposes. First, an automated LLM-based, post-breach exploitation framework can help analysts quickly test and continually improve their organization's network security posture against previously unseen attacks. Second, an LLM-based penetration test system can extend the effectiveness of red teams with a limited number of human analysts. Finally, this research can help defensive systems and teams learn to detect novel attack behaviors preemptively before their use in the wild....
TranSalNet: Visual saliency prediction using transformers
Oct 07, 2021



Convolutional neural networks (CNNs) have significantly advanced computational modeling for saliency prediction. However, the inherent inductive biases of convolutional architectures cause insufficient long-range contextual encoding capacity, which potentially makes a saliency model less humanlike. Transformers have shown great potential in encoding long-range information by leveraging the self-attention mechanism. In this paper, we propose a novel saliency model integrating transformer components to CNNs to capture the long-range contextual information. Experimental results show that the new components make improvements, and the proposed model achieves promising results in predicting saliency.
Gradient Weighted Superpixels for Interpretability in CNNs
Aug 16, 2019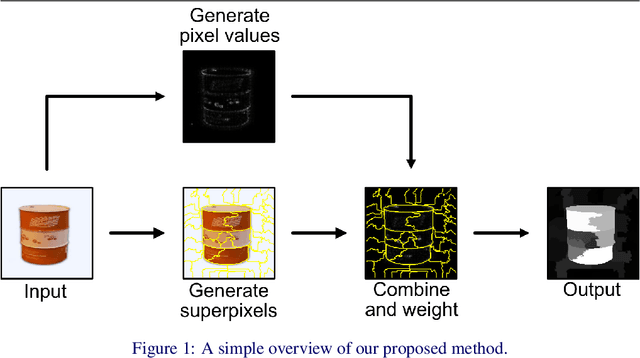
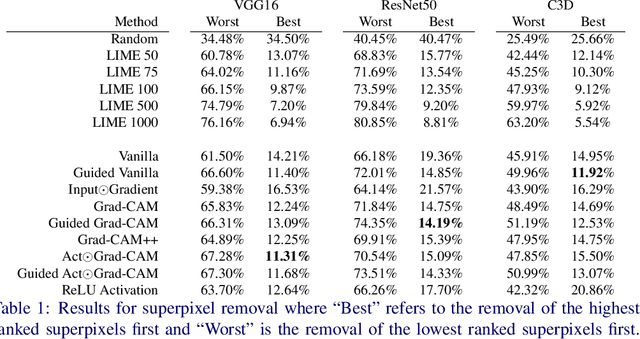
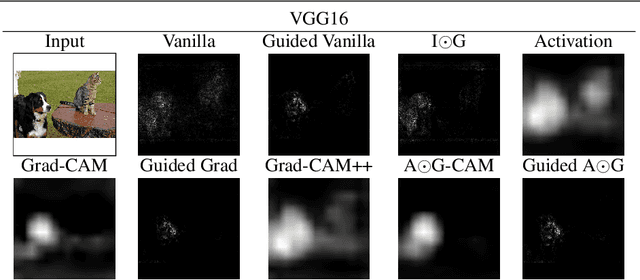
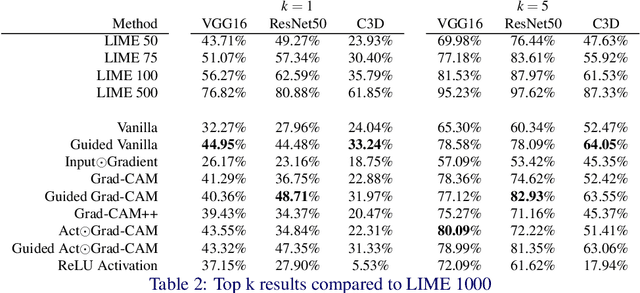
As Convolutional Neural Networks embed themselves into our everyday lives, the need for them to be interpretable increases. However, there is often a trade-off between methods that are efficient to compute but produce an explanation that is difficult to interpret, and those that are slow to compute but provide a more interpretable result. This is particularly challenging in problem spaces that require a large input volume, especially video which combines both spatial and temporal dimensions. In this work we introduce the idea of scoring superpixels through the use of gradient based pixel scoring techniques. We show qualitatively and quantitatively that this is able to approximate LIME, in a fraction of the time. We investigate our techniques using both image classification, and action recognition networks on large scale datasets (ImageNet and Kinetics-400 respectively).
Discriminating Spatial and Temporal Relevance in Deep Taylor Decompositions for Explainable Activity Recognition
Aug 14, 2019

Current techniques for explainable AI have been applied with some success to image processing. The recent rise of research in video processing has called for similar work n deconstructing and explaining spatio-temporal models. While many techniques are designed for 2D convolutional models, others are inherently applicable to any input domain. One such body of work, deep Taylor decomposition, propagates relevance from the model output distributively onto its input and thus is not restricted to image processing models. However, by exploiting a simple technique that removes motion information, we show that it is not the case that this technique is effective as-is for representing relevance in non-image tasks. We instead propose a discriminative method that produces a na\"ive representation of both the spatial and temporal relevance of a frame as two separate objects. This new discriminative relevance model exposes relevance in the frame attributed to motion, that was previously ambiguous in the original explanation. We observe the effectiveness of this technique on a range of samples from the UCF-101 action recognition dataset, two of which are demonstrated in this paper.
Weakly-Supervised Temporal Localization via Occurrence Count Learning
May 17, 2019

We propose a novel model for temporal detection and localization which allows the training of deep neural networks using only counts of event occurrences as training labels. This powerful weakly-supervised framework alleviates the burden of the imprecise and time-consuming process of annotating event locations in temporal data. Unlike existing methods, in which localization is explicitly achieved by design, our model learns localization implicitly as a byproduct of learning to count instances. This unique feature is a direct consequence of the model's theoretical properties. We validate the effectiveness of our approach in a number of experiments (drum hit and piano onset detection in audio, digit detection in images) and demonstrate performance comparable to that of fully-supervised state-of-the-art methods, despite much weaker training requirements.
Detecting Violent and Abnormal Crowd activity using Temporal Analysis of Grey Level Co-occurrence Matrix (GLCM) Based Texture Measures
Apr 03, 2017



The severity of sustained injury resulting from assault-related violence can be minimised by reducing detection time. However, it has been shown that human operators perform poorly at detecting events found in video footage when presented with simultaneous feeds. We utilise computer vision techniques to develop an automated method of abnormal crowd detection that can aid a human operator in the detection of violent behaviour. We observed that behaviour in city centre environments often occur in crowded areas, resulting in individual actions being occluded by other crowd members. We propose a real-time descriptor that models crowd dynamics by encoding changes in crowd texture using temporal summaries of Grey Level Co-Occurrence Matrix (GLCM) features. We introduce a measure of inter-frame uniformity (IFU) and demonstrate that the appearance of violent behaviour changes in a less uniform manner when compared to other types of crowd behaviour. Our proposed method is computationally cheap and offers real-time description. Evaluating our method using a privately held CCTV dataset and the publicly available Violent Flows, UCF Web Abnormality, and UMN Abnormal Crowd datasets, we report a receiver operating characteristic score of 0.9782, 0.9403, 0.8218 and 0.9956 respectively.
* Published under open access, 9 pages, 12 Figures