 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGradient Weighted Superpixels for Interpretability in CNNs
Aug 16, 2019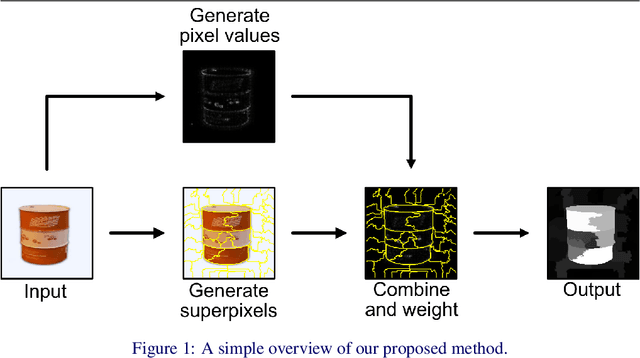
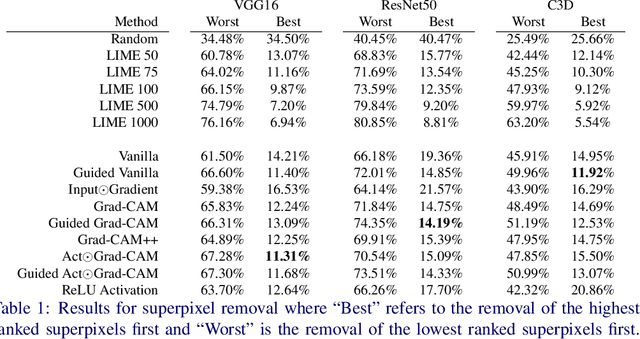
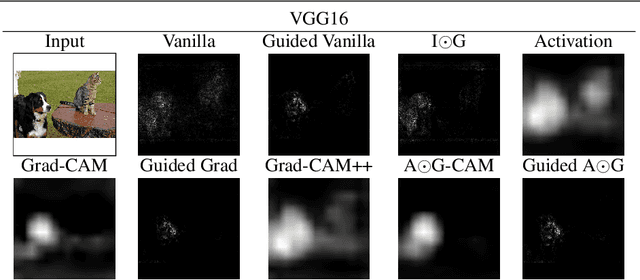
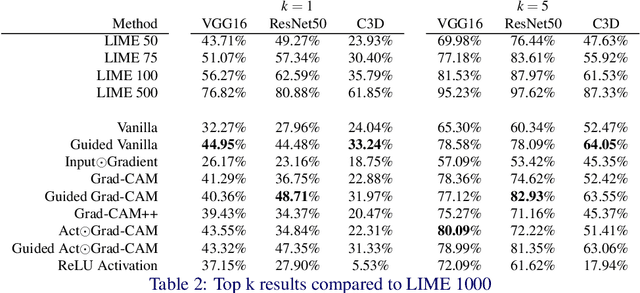
As Convolutional Neural Networks embed themselves into our everyday lives, the need for them to be interpretable increases. However, there is often a trade-off between methods that are efficient to compute but produce an explanation that is difficult to interpret, and those that are slow to compute but provide a more interpretable result. This is particularly challenging in problem spaces that require a large input volume, especially video which combines both spatial and temporal dimensions. In this work we introduce the idea of scoring superpixels through the use of gradient based pixel scoring techniques. We show qualitatively and quantitatively that this is able to approximate LIME, in a fraction of the time. We investigate our techniques using both image classification, and action recognition networks on large scale datasets (ImageNet and Kinetics-400 respectively).