 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReasoning about Reasoning: BAPO Bounds on Chain-of-Thought Token Complexity in LLMs
Feb 02, 2026Inference-time scaling via chain-of-thought (CoT) reasoning is a major driver of state-of-the-art LLM performance, but it comes with substantial latency and compute costs. We address a fundamental theoretical question: how many reasoning tokens are required to solve a problem as input size grows? By extending the bounded attention prefix oracle (BAPO) model--an abstraction of LLMs that quantifies the information flow required to solve a task--we prove lower bounds on the CoT tokens required for three canonical BAPO-hard tasks: binary majority, triplet matching, and graph reachability. We show that each requires $Ω(n)$ reasoning tokens when the input size is $n$. We complement these results with matching or near-matching upper bounds via explicit constructions. Finally, our experiments with frontier reasoning models show approximately linear reasoning token scaling on these tasks and failures when constrained to smaller reasoning budgets, consistent with our theoretical lower bounds. Together, our results identify fundamental bottlenecks in inference-time compute through CoT and offer a principled tool for analyzing optimal reasoning length.
Provably Learning from Language Feedback
Jun 12, 2025Interactively learning from observation and language feedback is an increasingly studied area driven by the emergence of large language model (LLM) agents. While impressive empirical demonstrations have been shown, so far a principled framing of these decision problems remains lacking. In this paper, we formalize the Learning from Language Feedback (LLF) problem, assert sufficient assumptions to enable learning despite latent rewards, and introduce $\textit{transfer eluder dimension}$ as a complexity measure to characterize the hardness of LLF problems. We show that transfer eluder dimension captures the intuition that information in the feedback changes the learning complexity of the LLF problem. We demonstrate cases where learning from rich language feedback can be exponentially faster than learning from reward. We develop a no-regret algorithm, called $\texttt{HELiX}$, that provably solves LLF problems through sequential interactions, with performance guarantees that scale with the transfer eluder dimension of the problem. Across several empirical domains, we show that $\texttt{HELiX}$ performs well even when repeatedly prompting LLMs does not work reliably. Our contributions mark a first step towards designing principled interactive learning algorithms from generic language feedback.
A Course Correction in Steerability Evaluation: Revealing Miscalibration and Side Effects in LLMs
May 27, 2025Despite advances in large language models (LLMs) on reasoning and instruction-following benchmarks, it remains unclear whether they can reliably produce outputs aligned with a broad variety of user goals, a concept we refer to as steerability. The abundance of methods proposed to modify LLM behavior makes it unclear whether current LLMs are already steerable, or require further intervention. In particular, LLMs may exhibit (i) poor coverage, where rare user goals are underrepresented; (ii) miscalibration, where models overshoot requests; and (iii) side effects, where changes to one dimension of text inadvertently affect others. To systematically evaluate these failures, we introduce a framework based on a multi-dimensional goal space that models user goals and LLM outputs as vectors with dimensions corresponding to text attributes (e.g., reading difficulty). Applied to a text-rewriting task, we find that current LLMs struggle with steerability, as side effects are persistent. Interventions to improve steerability, such as prompt engineering, best-of-$N$ sampling, and reinforcement learning fine-tuning, have varying effectiveness, yet side effects remain problematic. Our findings suggest that even strong LLMs struggle with steerability, and existing alignment strategies may be insufficient. We open-source our steerability evaluation framework at https://github.com/MLD3/steerability.
Lost in Transmission: When and Why LLMs Fail to Reason Globally
May 13, 2025Despite their many successes, transformer-based large language models (LLMs) continue to struggle with tasks that require complex reasoning over large parts of their input. We argue that these failures arise due to capacity limits on the accurate flow of information within LLMs. To formalize this issue, we introduce the bounded attention prefix oracle (BAPO) model, a new computational framework that models bandwidth constraints on attention heads, the mechanism for internal communication in LLMs. We show that several important reasoning problems like graph reachability require high communication bandwidth for BAPOs to solve; we call these problems BAPO-hard. Our experiments corroborate our theoretical predictions: GPT-4, Claude, and Gemini succeed on BAPO-easy tasks and fail even on relatively small BAPO-hard tasks. BAPOs also reveal another benefit of chain of thought (CoT): we prove that breaking down a task using CoT can turn any BAPO-hard problem into a BAPO-easy one. Our results offer principled explanations for key LLM failures and suggest directions for architectures and inference methods that mitigate bandwidth limits.
How to Solve Contextual Goal-Oriented Problems with Offline Datasets?
Aug 14, 2024



We present a novel method, Contextual goal-Oriented Data Augmentation (CODA), which uses commonly available unlabeled trajectories and context-goal pairs to solve Contextual Goal-Oriented (CGO) problems. By carefully constructing an action-augmented MDP that is equivalent to the original MDP, CODA creates a fully labeled transition dataset under training contexts without additional approximation error. We conduct a novel theoretical analysis to demonstrate CODA's capability to solve CGO problems in the offline data setup. Empirical results also showcase the effectiveness of CODA, which outperforms other baseline methods across various context-goal relationships of CGO problem. This approach offers a promising direction to solving CGO problems using offline datasets.
Trace is the New AutoDiff -- Unlocking Efficient Optimization of Computational Workflows
Jun 23, 2024



We study a class of optimization problems motivated by automating the design and update of AI systems like coding assistants, robots, and copilots. We propose an end-to-end optimization framework, Trace, which treats the computational workflow of an AI system as a graph akin to neural networks, based on a generalization of back-propagation. Optimization of computational workflows often involves rich feedback (e.g. console output or user's responses), heterogeneous parameters (e.g. prompts, hyper-parameters, codes), and intricate objectives (beyond maximizing a score). Moreover, its computation graph can change dynamically with the inputs and parameters. We frame a new mathematical setup of iterative optimization, Optimization with Trace Oracle (OPTO), to capture and abstract these properties so as to design optimizers that work across many domains. In OPTO, an optimizer receives an execution trace along with feedback on the computed output and updates parameters iteratively. Trace is the tool to implement OPTO in practice. Trace has a Python interface that efficiently converts a computational workflow into an OPTO instance using a PyTorch-like interface. Using Trace, we develop a general-purpose LLM-based optimizer called OptoPrime that can effectively solve OPTO problems. In empirical studies, we find that OptoPrime is capable of first-order numerical optimization, prompt optimization, hyper-parameter tuning, robot controller design, code debugging, etc., and is often competitive with specialized optimizers for each domain. We believe that Trace, OptoPrime and the OPTO framework will enable the next generation of interactive agents that automatically adapt using various kinds of feedback. Website: https://microsoft.github.io/Trace
On Overcoming Miscalibrated Conversational Priors in LLM-based Chatbots
Jun 01, 2024

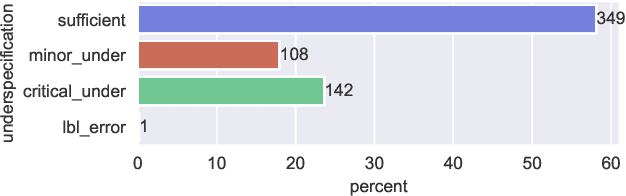

We explore the use of Large Language Model (LLM-based) chatbots to power recommender systems. We observe that the chatbots respond poorly when they encounter under-specified requests (e.g., they make incorrect assumptions, hedge with a long response, or refuse to answer). We conjecture that such miscalibrated response tendencies (i.e., conversational priors) can be attributed to LLM fine-tuning using annotators -- single-turn annotations may not capture multi-turn conversation utility, and the annotators' preferences may not even be representative of users interacting with a recommender system. We first analyze public LLM chat logs to conclude that query under-specification is common. Next, we study synthetic recommendation problems with configurable latent item utilities and frame them as Partially Observed Decision Processes (PODP). We find that pre-trained LLMs can be sub-optimal for PODPs and derive better policies that clarify under-specified queries when appropriate. Then, we re-calibrate LLMs by prompting them with learned control messages to approximate the improved policy. Finally, we show empirically that our lightweight learning approach effectively uses logged conversation data to re-calibrate the response strategies of LLM-based chatbots for recommendation tasks.
The Importance of Directional Feedback for LLM-based Optimizers
May 26, 2024



We study the potential of using large language models (LLMs) as an interactive optimizer for solving maximization problems in a text space using natural language and numerical feedback. Inspired by the classical optimization literature, we classify the natural language feedback into directional and non-directional, where the former is a generalization of the first-order feedback to the natural language space. We find that LLMs are especially capable of optimization when they are provided with {directional feedback}. Based on this insight, we design a new LLM-based optimizer that synthesizes directional feedback from the historical optimization trace to achieve reliable improvement over iterations. Empirically, we show our LLM-based optimizer is more stable and efficient in solving optimization problems, from maximizing mathematical functions to optimizing prompts for writing poems, compared with existing techniques.
AutoAttacker: A Large Language Model Guided System to Implement Automatic Cyber-attacks
Mar 02, 2024Large language models (LLMs) have demonstrated impressive results on natural language tasks, and security researchers are beginning to employ them in both offensive and defensive systems. In cyber-security, there have been multiple research efforts that utilize LLMs focusing on the pre-breach stage of attacks like phishing and malware generation. However, so far there lacks a comprehensive study regarding whether LLM-based systems can be leveraged to simulate the post-breach stage of attacks that are typically human-operated, or "hands-on-keyboard" attacks, under various attack techniques and environments. As LLMs inevitably advance, they may be able to automate both the pre- and post-breach attack stages. This shift may transform organizational attacks from rare, expert-led events to frequent, automated operations requiring no expertise and executed at automation speed and scale. This risks fundamentally changing global computer security and correspondingly causing substantial economic impacts, and a goal of this work is to better understand these risks now so we can better prepare for these inevitable ever-more-capable LLMs on the horizon. On the immediate impact side, this research serves three purposes. First, an automated LLM-based, post-breach exploitation framework can help analysts quickly test and continually improve their organization's network security posture against previously unseen attacks. Second, an LLM-based penetration test system can extend the effectiveness of red teams with a limited number of human analysts. Finally, this research can help defensive systems and teams learn to detect novel attack behaviors preemptively before their use in the wild....
LLF-Bench: Benchmark for Interactive Learning from Language Feedback
Dec 13, 2023We introduce a new benchmark, LLF-Bench (Learning from Language Feedback Benchmark; pronounced as "elf-bench"), to evaluate the ability of AI agents to interactively learn from natural language feedback and instructions. Learning from language feedback (LLF) is essential for people, largely because the rich information this feedback provides can help a learner avoid much of trial and error and thereby speed up the learning process. Large Language Models (LLMs) have recently enabled AI agents to comprehend natural language -- and hence AI agents can potentially benefit from language feedback during learning like humans do. But existing interactive benchmarks do not assess this crucial capability: they either use numeric reward feedback or require no learning at all (only planning or information retrieval). LLF-Bench is designed to fill this omission. LLF-Bench is a diverse collection of sequential decision-making tasks that includes user recommendation, poem writing, navigation, and robot control. The objective of an agent is to interactively solve these tasks based on their natural-language instructions and the feedback received after taking actions. Crucially, to ensure that the agent actually "learns" from the feedback, LLF-Bench implements several randomization techniques (such as paraphrasing and environment randomization) to ensure that the task isn't familiar to the agent and that the agent is robust to various verbalizations. In addition, LLF-Bench provides a unified OpenAI Gym interface for all its tasks and allows the users to easily configure the information the feedback conveys (among suggestion, explanation, and instantaneous performance) to study how agents respond to different types of feedback. Together, these features make LLF-Bench a unique research platform for developing and testing LLF agents.